Using the 2022-11-23 Registered Voter List (RVL) and the 2023-01-26 Voter History List (VHL) purchased from the VA Department of Elections (ELECT) I wrote up an analysis script to check for potentially duplicated registrant records in the RVL and cross reference duplicate pairings with the VHL to identify potential duplicate votes. This was my initial attempt at quantifying the number of potentially duplicate records in the RVL, and I have since updated the code to use a more rigorous Levenshtein distance metric, as well as making improvements to the parsing routines, bugfixes, etc. The details of the Hamming distance work are summarized below, and left up here for reference. For the latest and up to date information, please see the newer article posted here.
Errata note: One of the code bugs I discovered was that some of the entries did not actually get checked as they were accidentally skipped, so the numbers below are lower than the numbers presented in the newer work.
Please note that I will not publish voter Personally Identifiable Information (PII) on this blog. I have substituted fictitious PII information for all examples given below, and cryptographically hashed all voter information in the downloadable results file. I will make available the detailed information to those that have the authorization to receive and process voter data upon request (contact us).
Summary of Results:
We should mathematically expect approximately 11 exact string collisions in the full RVL dataset when comparing (First Name + Middle Name + Last Name + Suffix + Full DOB), but instead we see 1982 such collisions, which is over an order of magnitude increase from the expected value. While its possible that some of these collisions are false positives, there are quite a number of them that are deserving of further scrutiny.
Method:
For every entry in the latest RVL, I performed a string distance comparison, based on Hamming distance, between every possible pair of strings of (FIRST NAME + MIDDLE NAME + LAST NAME + SUFFIX + FULL DOB). So for the ~6M different RVL entries, we need to compute ~3.6 x 10^13 different string comparisons. A hamming distance of 0 indicates the strings being compared are identical, a hamming distance of 1 indicates that there is a single character different between the two strings, a hamming distance of 2 indicates 2 characters are different, etc. This obviously is a very computationally intensive process and it took over two days to complete the processing, once I got the bugs worked out. (I’ve been quietly working on this one for a while now … )
Note that the Hamming distance only compares each respective position in a string and does not account for adding or removing a character completely from a string. A metric that does include addition and subtraction is the Levenshtein Edit Distance, which is much more computationally expensive (but more rigorous) metric. The Hamming distance is related to the Levenshtein distance in that it is mathematically the upper bound on the Levenshtein distance for arbitrary strings. I haven’t yet finished making an optimized GPU accelerated version of the Levenshtein edit distance metric, but it is in the works and I will redo this analysis with the new metric once that is completed.
I aggregated all of the Hamming distance pairings that were less than or equal to 3 characters different in order to identify potential (key word) duplicated registrants, and additionally for each pairing looked at the voter history information for each registrant in the pair to determine if there was a potential (again … key word) for multiple ballots to be cast by the same person in any given election. As we allow for more characters to be different, we potentially are including many more likely false positive matches, even if we are catching more true positives.
For example: At a Hamming distance of 4 the strings of “Dave Joseph Smith M 10/01/1981” and “Tony Joseph Smith M 10/01/1981” at the same address would produce a potential match, but so would “Davey Joseph Smith M 10/01/1981” and “David Josiph Smith M 10/02/1981”. The first pair is more likely to be a false positive due to twins, while the second is more likely to be due to typo’s, mistakes, or use of nicknames and might warrant further investigation. A much stronger potential match would be something like “David Josiph Smith M 10/01/1981” and “David Joseph Smith M 10/01/1981”, with a Hamming distance of 1 at the same address. In an attempt to limit false positives, I have clamped the Hamming distance checks to <= 3 in this analysis.
One of the drawbacks of using Hamming distance over a more complete metric such as Levenshtein, is that the Hamming distance would give a very high score, and would therefore filter out of our results, an example pairing such as: “David Joseph Smith M 10/01/1981” and “Dave Joseph Smith M 10/01/1981”. The change from “id” to “e” adds/subtracts a character making the rest of the characters in the remainder of the string shift position and also not match. A Levenshtein metric would correctly return a small distance of 2, whereas the hamming distance returns 27. (As mentioned earlier, I am working on a Levenshtein implementation, but it is not yet complete.)
Note that with the official records obtained from ELECT, and in accordance with the laws of VA, I do not have access to the social security number or drivers license numbers for each registration record, which would help in identifying and discriminating potential duplicate errors vs things like twins, etc. I only have the first name, middle name, last name, suffix, month of birth, day of birth, year of birth, gender, and address information that I can work with. I can therefore only take things so far before someone else (with investigative authority and ability to access those other fields) would need to step in and confirm and validate these findings.
Results:
The summary totals are as follows, with detailed examples.
| Hamming Distance | 0 | 1 | 2 | 3 |
| Number of Potential Duplicate Registrant Pairs | 1982 | 3276 | 21864 | 120642 |
| Number of Potential Duplicate Ballots | 110 | 3248 | 31210 | 175872 |
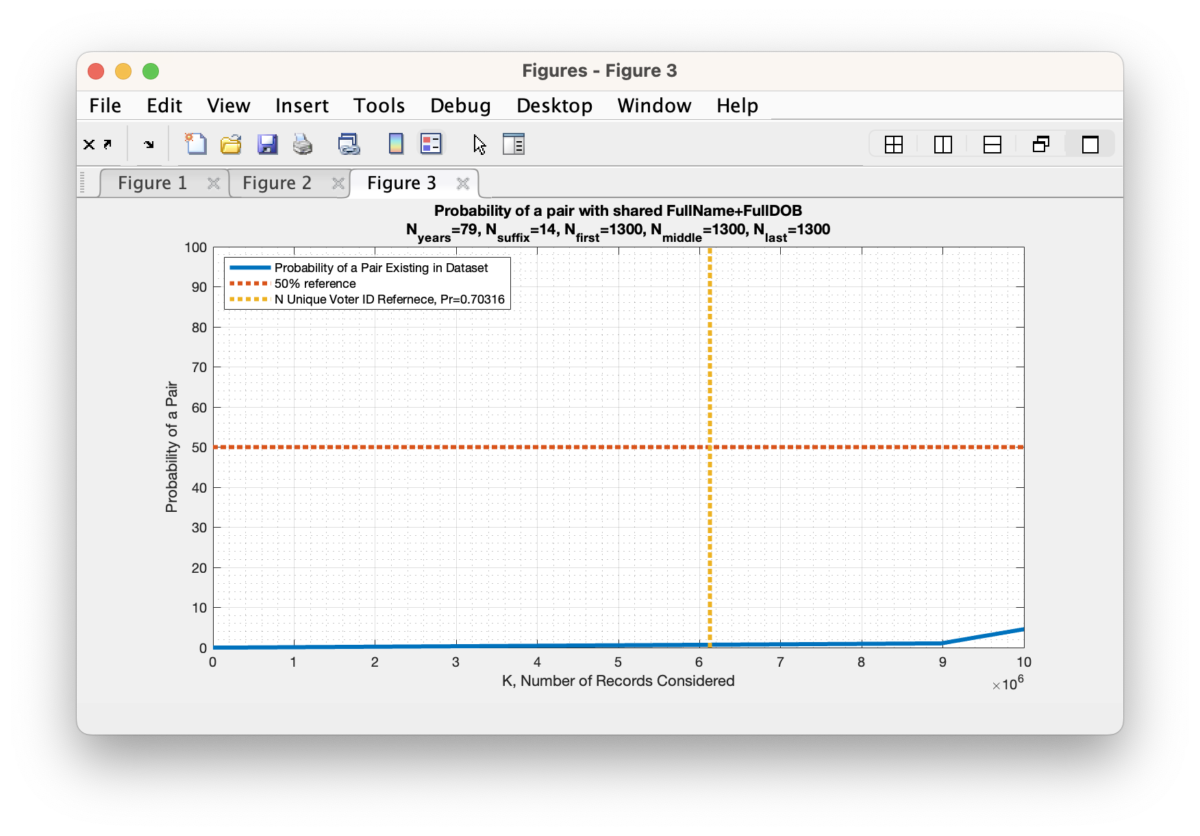
According to my derivations and simulations that are described in detail at the end of this article, we should only expect to see an average of 11 (+/- 3) potential duplicate pairs (a.k.a. “collisions”) at a Hamming distance of 0. This is over two orders of magnitude different than what we observe in the compiled results table above. Such a discrepancy deserves further investigation and verification.
Examples of Types of Issues Observed:
NOTE THE BELOW INFORMATION HAS HAD THE VOTER PERSONALLY IDENTIFIABLE INFORMATION (“PII”) FICTIONALIZED. WHILE THESE ARE BASED ON REAL DATA TO ILLUSTRATE THE DIFFERENT TYPES OF OBSERVATIONS, THEY DO NOT REPRESENT REAL VOTER INFORMATION.
Example #1: The following set of records has the exact match (Hamming Distance = 0) of full name and full birthdate (including year), but different address and different voter ID numbers AND there was a vote cast from each of those unique voter ID’s in the 2020 General Election. While it’s remotely possible that two individuals share the exact same name, month, day and year of birth … it is probabilistically unlikely (see section below on mathematical derivation of probabilities if interested), and should warrant further scrutiny.
Voter Record A:
AMY BETH McVOTER 12/05/1970 F 12345 CITIZEN CT
Voter Record B:
AMY BETH McVOTER 12/05/1970 F 5678 McPUBLIC DR
Example #2: This set of records has a single character different (Hamming distance of 1) in their first name, but middle name, last name, birthdate and address are identical AND both records are associated with votes that were cast in the 2020, 2021, and 2022 November General Elections. While it is possible that this is a pair of 23 year old twins (with same middle names) that live together, it at least bears looking into.
Voter Record A:
TAYLOR DAVID VOTER 02/16/2000 M 6543 OVERLOOK AVE NW
Voter Record B:
DAYLOR DAVID VOTER 02/16/2000 M 6543 OVERLOOK AVE NW
Example #3: This set of records has two characters different (Hamming distance of 2) in their birthdate, but name and address are identical AND the birth years are too close together for a child/parent relationship, AND both records are associated with votes that were cast in the 2020 and 2022 November General Elections.
Voter Record A:
REGINA DESEREE MACGUFFIN 02/05/1973 F 123 POPE AVE
Voter Record B:
REGINA DESEREE MACGUFFIN 03/07/1973 F 123 POPE AVE
Example #4: This set of records has again a single character different (Hamming distance of 1) in the first name (but not the first letter this time) and the last name, birthdate and address are identical. There were also multiple votes cast in the 2019 and 2022 November General from these registrants.
Voter Record A:
EDGARD JOHNSON 10/19/1981 M 5498 PAGELAND BLVD
Voter Record B:
EDUARD JOHNSON 10/19/1981 M 5498 PAGELAND BLVD
Example #5: This set of records has two characters different (Hamming distance of 2) in the first and middle names and the last name, birthdate, gender and address are identical. There were also multiple votes cast in the 2021 and 2022 November General from these registrants. Again it is possible that these records represent a set of twins given the information that ELECT provides.
Voter Record A:
ALANA JAVETTE THOMPSON 01/01/2003 F 123 CHARITY LN
Voter Record B:
ALAYA YAVETTE THOMPSON 01/01/2003 F 123 CHARITY LN
Example #6: The following set of records has the exact match (Hamming Distance = 0) of full name and full birthdate (including year), and same address but different voter ID numbers. There was no duplicated votes in the same election detected between the two ID numbers.
Voter Record A:
JAMES TIBERIUS KIRK 03/22/2223 M 1701 Enterprise Bridge
Voter Record B:
JAMES TIBERIUS KIRK 03/22/2223 M 1701 Enterprise Bridge
Example #7: The following set of records has the exact match (Hamming Distance = 0) of full name and full birthdate (including year), same address but different gender and voter ID numbers. There was no duplicated votes in the same election detected between the two ID numbers.
Voter Record A:
MAXWELL QUAID CLINGER 11/03/2004 M 4077 MASH DR
Voter Record B:
MAXWELL QUAID CLINGER 11/03/2004 U 4077 MASH DR
Results Dataset:
A full version of the aggregated excel data is provided below, however all voter information (ID, first name, middle name, last name, dob, gender, address) have been removed and replaced by a one-way hash number, with randomized salt, based on the voter ID. The full file with specific voter information can be provided to parties authorized by ELECT to recieve and process voter information, Election Officials, or Law Enforcement upon request.
On the mathematical probability of matches:
2023-05-27: I have moved my derivation of the expected value of the number of collisions to a separate post, available here.
