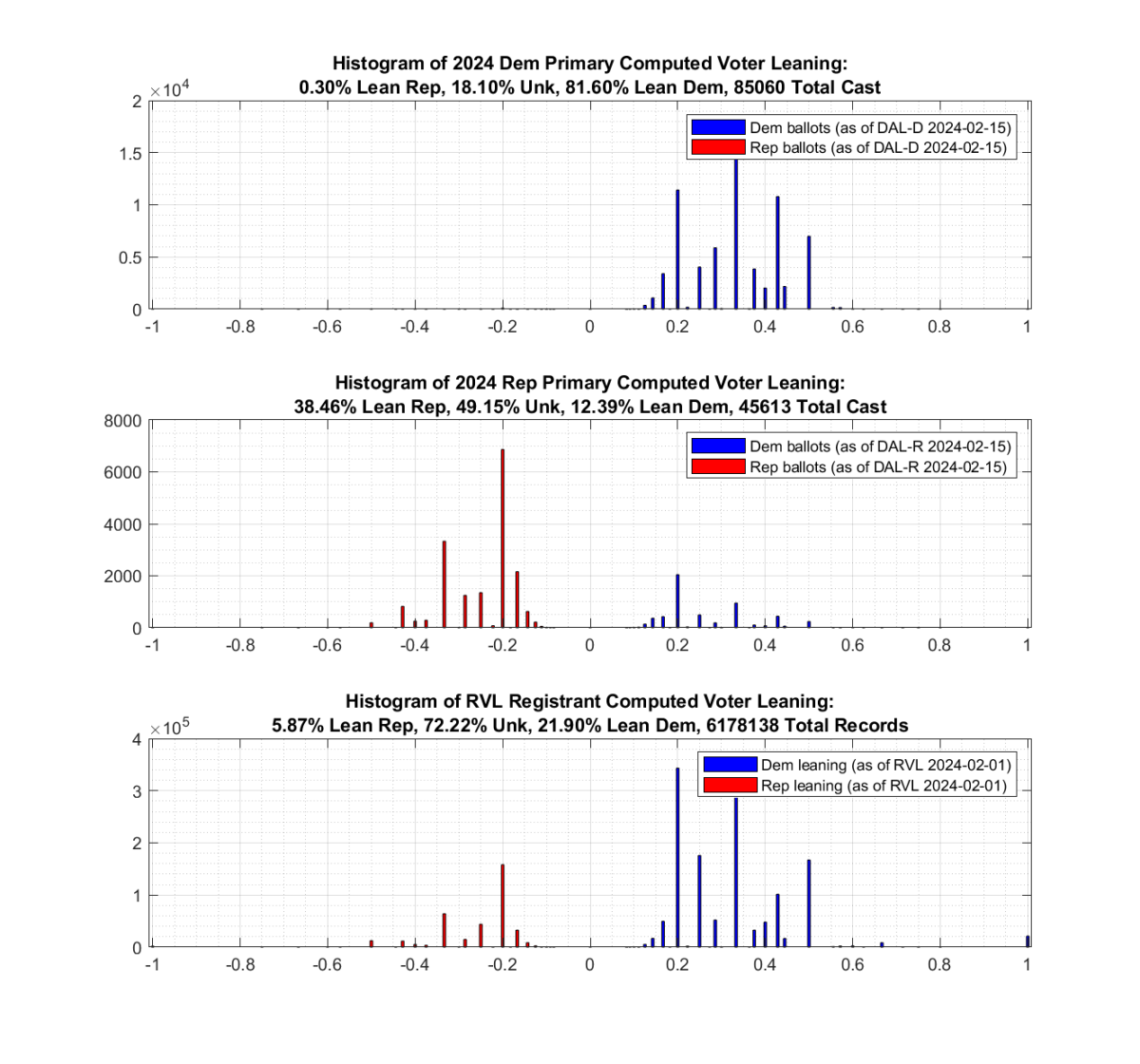
There are currently two completely separate but simultaneous primary elections being held in VA, with actual Election Day coming up fast on March 5th. As part of EPEC’s data analysis on the ongoing Democrat and Republican primaries, I took some time to look at the distribution of voter participation. VA does not have voter registration by party, but participation in primary elections is often used as a surrogate method to try and estimate a voter leaning.
I was specifically interested as to how many “cross-over” voters were participating in each parties primary. There have been multiple news articles (here, for example) discussing the potential for democrats to cross-vote in the 2024 Primaries, and I wanted to see if I could observe evidence of that behavior in the data.
Results:
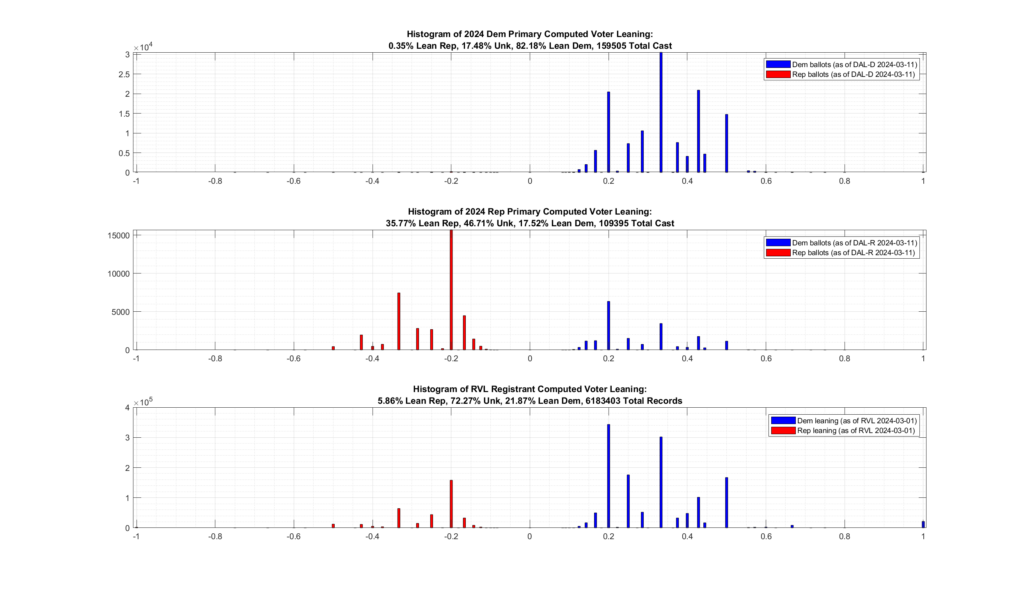
As can be seen from the image below, there is definitely evidence of crossover voting occurring, with historically democratic primary voters crossing over and voting in this years (2024) Republican primary.
Approximately 17.5% of the 109,395 ballots cast in the 2024 VA Republican primary are associated with historically Democrat leaning registrants. Only 0.35% of the 159,505 ballots cast in the 2024 VA Democratic primary are associated with historically Republican leaning registrants. [Note this plot was updated on 2024-03-11 to reflect the latest values. The previous results from mid-February had the number of crossover D->R voters at ~12%]
Method:
Step 1: Compute an estimate of voter leaning.
The data utilized in this analysis all comes directly from the VA Dept of Elections (“ELECT”) and includes the statewide Registered Voter List (“RVL”) and Voter History List (“VHL”) files dated 03/11/2024, as well as the Daily Absentee List (“DAL”) files corresponding to each of the ongoing Democrat and Republican primaries.
An estimation of each party leaning is first computed by going through the VHL and for each unique voter in the VHL summing the number of Democrat or Republican primaries that voter has participated in historically. We then take the difference of these two fields and divide by the total number of election contests the voter has participated in. This gives us a resultant estimate of the “leaning” for each unique voter.
leaning = (# Dem Primaries – # Rep Primaries) / (# of Total Contests)
A leaning < 0 indicates a Republican lean, and > 0 indicates a Democratic lean. A voter might have a lean == 0 if they had a balanced participation in previous primaries, or if there is no voter history for that particular voter.
Step 2: Plot the histogram of voter leaning for ballots cast so far in both the Democratic and Republican primaries. Additionally plot the Computed voter leaning for the entire RVL as a reference.
After reading through the press release we decided to independently try to verify the claims in the release. Note that an analysis like this has been on our list of things-to-do, but there are only so many hours in the day! The fact this press release was issued gave us a well deserved prod to complete this analysis.
EPEC has purchased the entire statewide registered voter list data from the VA Department of Elections (ELECT) and has current records as of 2023-08-01. Eligible parties can purchase data from ELECT via their website here.
The necessary data from the US Census office can be downloaded here and included the estimates of the eligible voting age citizens in each county. From the documentation on the census site, the “cvap_est” field in the census data represents “The rounded estimate of the total number of United States citizens 18 years of age or older for that geographic area and group.”
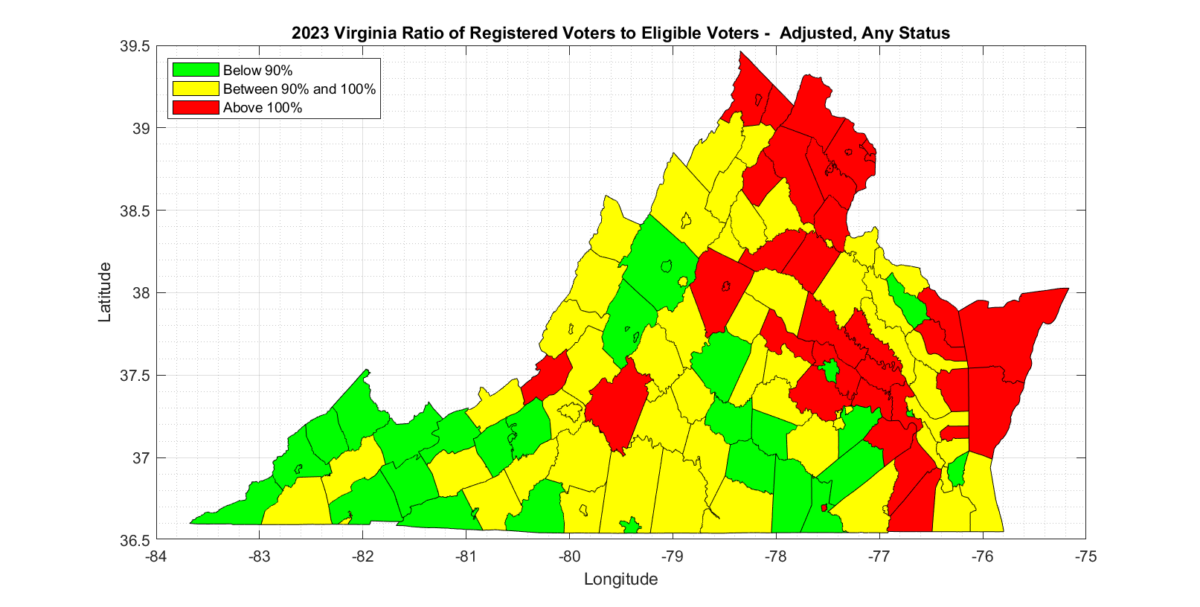
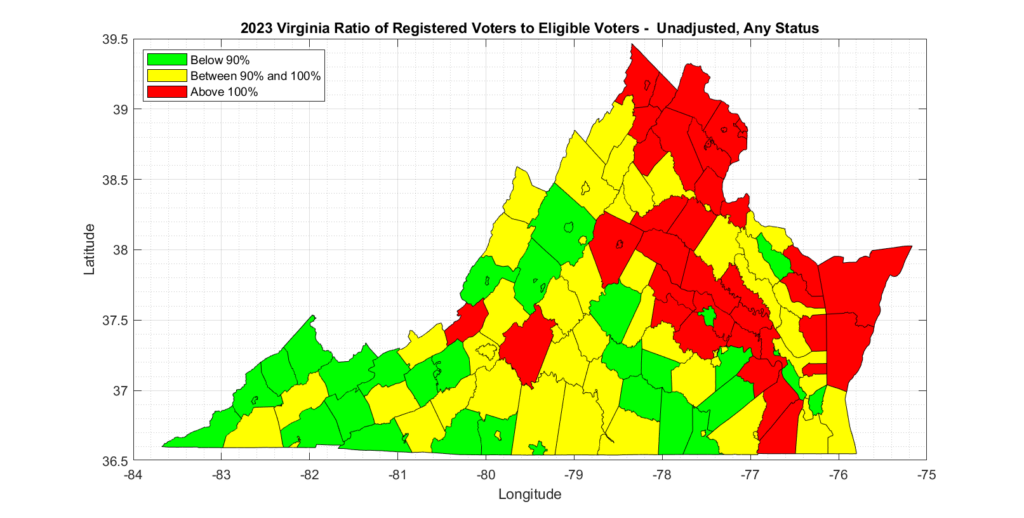
It is therefore a straightforward process to accumulate the number of registrant records in each county, as well as accumulating the number of eligible voting age citizens and compute the registration percent “REG_PCT” as (# Registered / # Eligible * 100). The below table has the results of this direct computation for each county.
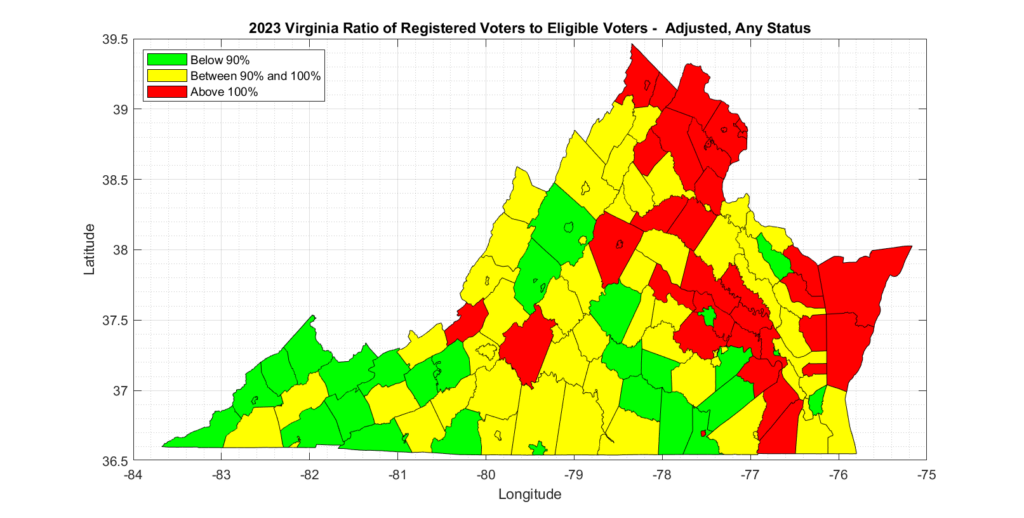
The results are only slightly different than the results presented by Honest Elections Project, but still show significant issues with 38 counties being over 100%.
Adjusting for population growth since 2020 census
As the census redistricting data is circa 2020, and the eligible voter data was estimated for 2021, we can attempt to account for population shifts since the 2020 census data was collected and the voter eligibility data was computed. The US Census bureau also makes available the estimates of population growth by county year-over-year since the date of the last census here, which we can use to find the recent rates of growth or decline for each county. We can then use these rates to adjust the number of eligible voter estimates to scale with the most recent rates of population change. This is admittedly an approximation and assumes a linear relationship, but it is arguably better than taking the 2020 census and 2021 eligible voter estimates and applying them directly to the latest (2023) RVL.
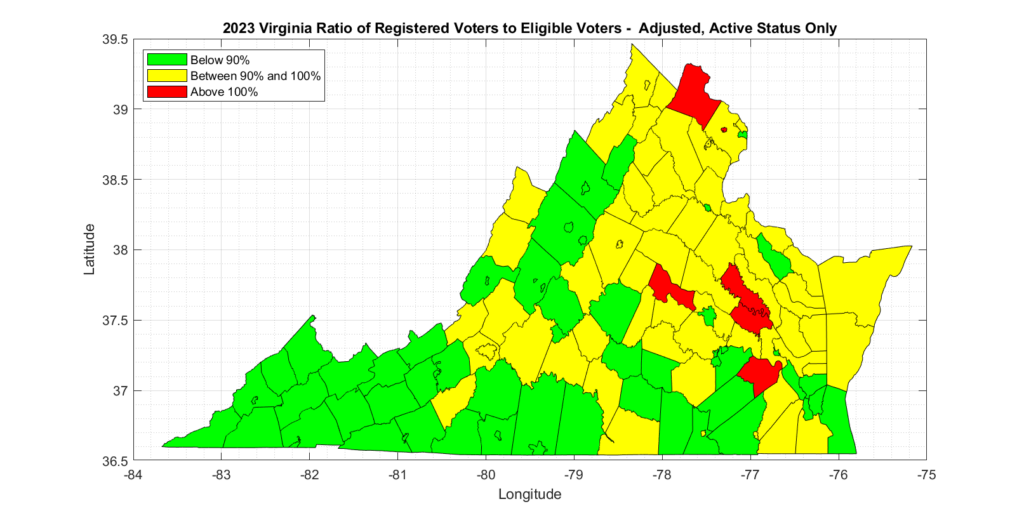
The REG_PCT_ADJ column in the table below represents this adjusted estimate.
Active vs inactive registrations
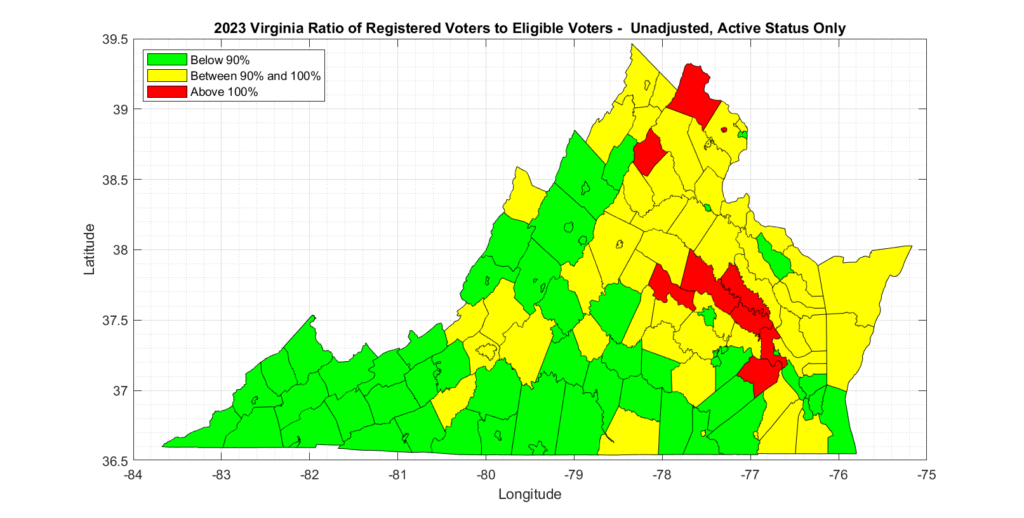
An additional consideration that can be made with this data, is to attempt to consider only “Active” voter registrations vs registrations with any status assigned. Note that “Inactive” voter registrations can be immediately returned to “Active” status by simply having any type of interaction with the department of elections (or through DMV, etc), and the registrant will then be allowed to vote. Because of this easy ability to change “Inactive” records to “Active”, it is most appropriate (IMO) to include them in this analysis. However, for completeness, and in order to bound the scope of the issue, the corresponding REG_PCT_ACTIVE and REG_PCT_ADJ_ACTIVE columns have also been computed which only consider “Active” voters.
Results
Even the most forgiving analysis we could compute with the official data from US Census and VA ELECT, which only considers active voters and attempts to adjust for population change since the census, still results in multiple (6) counties in VA having more than 100% registered voters than eligible voters, and many counties that had over 90%.
The most appropriate metric to consider, in my opinion, is the Adjusted and either Active or Inactive status results, as inactive status registrations can still be converted to active status and voted. There were 36 localities with over 100% in this category and 59 between 90% and 100%. There are 133 voting localities in total in VA.
The summary tabulated data and graphics for each of the methods of analyzing the data is presented below.
Per the recent James O’Keefe video documenting incredulous amounts of contributions by individuals to political committees, I took a few minutes to download the public FEC data in bulk format and collated all of the individuals that had more than 100 donations to each of the following organizations: DNC, DCCC, DSCC, RNC, NRSC, NRCC, WinRed, ActBlue in the 2021-2022 Election period.
I made sure to account for and remove those records of contributions that had been (legally) returned due to over-contribution, or earmarked for campaign committee legal or facility funds, etc which are exempt from campaign finance limits.
I hope it helps James. I’m not going to try and do any sort of analysis on this data, as I’ve got plenty to do regarding the IT of our elections, but I wanted to help where I could. Any questions, or if you would like the raw transaction data, please feel free to contact me, or if you have a particular committee ID that you would like the information for, just let me know. I am happy to help.
Using the 2022-11-23 Registered Voter List (RVL) and the 2023-01-26 Voter History List (VHL) purchased from the VA Department of Elections (ELECT) I wrote up an analysis script to check for potentially duplicated registrant records in the RVL and cross reference duplicate pairings with the VHL to identify potential duplicate votes. This was my initial attempt at quantifying the number of potentially duplicate records in the RVL, and I have since updated the code to use a more rigorous Levenshtein distance metric, as well as making improvements to the parsing routines, bugfixes, etc. The details of the Hamming distance work are summarized below, and left up here for reference. For the latest and up to date information, please see the newer article posted here.
Errata note: One of the code bugs I discovered was that some of the entries did not actually get checked as they were accidentally skipped, so the numbers below are lower than the numbers presented in the newer work.
Please note that I will not publish voter Personally Identifiable Information (PII) on this blog. I have substituted fictitious PII information for all examples given below, and cryptographically hashed all voter information in the downloadable results file. I will make available the detailed information to those that have the authorization to receive and process voter data upon request (contact us).
Summary of Results:
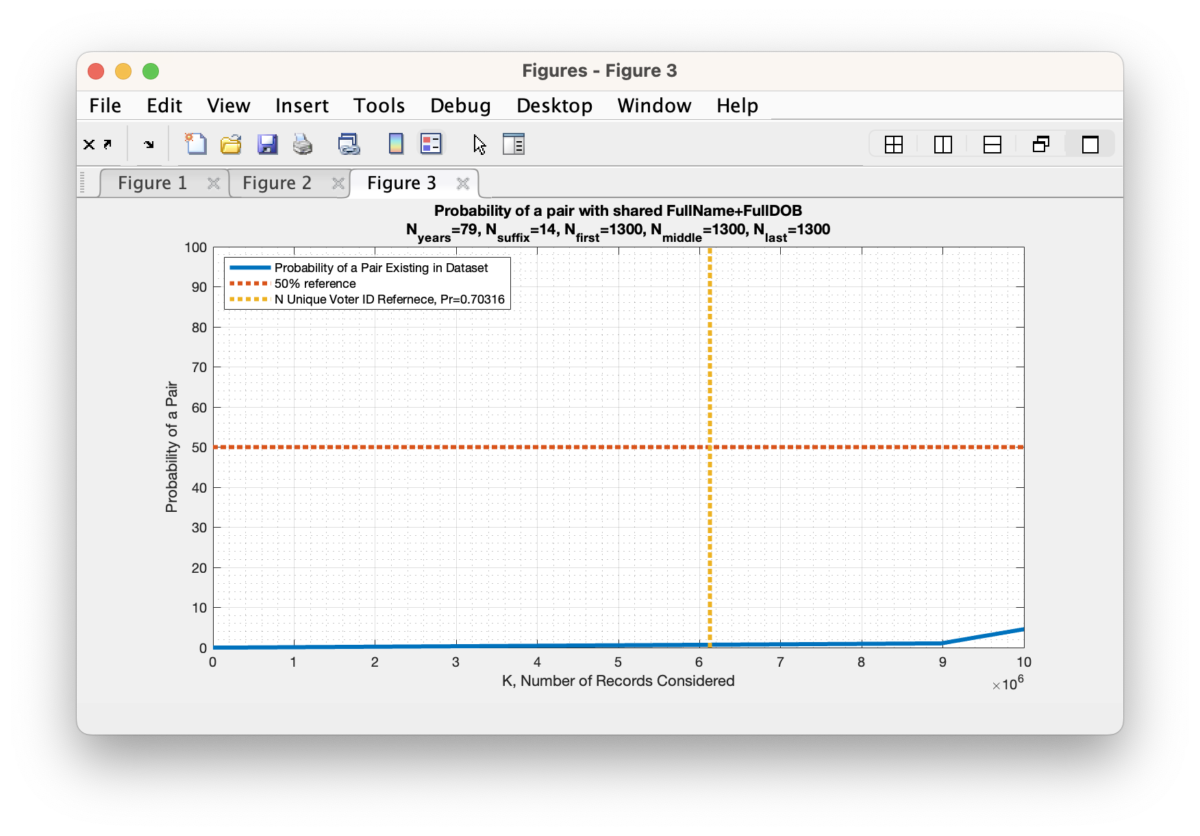
We should mathematically expect approximately 11 exact string collisions in the full RVL dataset when comparing (First Name + Middle Name + Last Name + Suffix + Full DOB), but instead we see 1982 such collisions, which is over an order of magnitude increase from the expected value. While its possible that some of these collisions are false positives, there are quite a number of them that are deserving of further scrutiny.
Method:
For every entry in the latest RVL, I performed a string distance comparison, based on Hamming distance, between every possible pair of strings of (FIRST NAME + MIDDLE NAME + LAST NAME + SUFFIX + FULL DOB). So for the ~6M different RVL entries, we need to compute ~3.6 x 10^13 different string comparisons. A hamming distance of 0 indicates the strings being compared are identical, a hamming distance of 1 indicates that there is a single character different between the two strings, a hamming distance of 2 indicates 2 characters are different, etc. This obviously is a very computationally intensive process and it took over two days to complete the processing, once I got the bugs worked out. (I’ve been quietly working on this one for a while now … )
Note that the Hamming distance only compares each respective position in a string and does not account for adding or removing a character completely from a string. A metric that does include addition and subtraction is the Levenshtein Edit Distance, which is much more computationally expensive (but more rigorous) metric. The Hamming distance is related to the Levenshtein distance in that it is mathematically the upper bound on the Levenshtein distance for arbitrary strings. I haven’t yet finished making an optimized GPU accelerated version of the Levenshtein edit distance metric, but it is in the works and I will redo this analysis with the new metric once that is completed.
I aggregated all of the Hamming distance pairings that were less than or equal to 3 characters different in order to identify potential (key word) duplicated registrants, and additionally for each pairing looked at the voter history information for each registrant in the pair to determine if there was a potential (again … key word) for multiple ballots to be cast by the same person in any given election. As we allow for more characters to be different, we potentially are including many more likely false positive matches, even if we are catching more true positives.
For example: At a Hamming distance of 4 the strings of “Dave Joseph Smith M 10/01/1981” and “Tony Joseph Smith M 10/01/1981” at the same address would produce a potential match, but so would “Davey Joseph Smith M 10/01/1981” and “David Josiph Smith M 10/02/1981”. The first pair is more likely to be a false positive due to twins, while the second is more likely to be due to typo’s, mistakes, or use of nicknames and might warrant further investigation. A much stronger potential match would be something like “David Josiph Smith M 10/01/1981” and “David Joseph Smith M 10/01/1981”, with a Hamming distance of 1 at the same address. In an attempt to limit false positives, I have clamped the Hamming distance checks to <= 3 in this analysis.
One of the drawbacks of using Hamming distance over a more complete metric such as Levenshtein, is that the Hamming distance would give a very high score, and would therefore filter out of our results, an example pairing such as: “David Joseph Smith M 10/01/1981” and “Dave Joseph Smith M 10/01/1981”. The change from “id” to “e” adds/subtracts a character making the rest of the characters in the remainder of the string shift position and also not match. A Levenshtein metric would correctly return a small distance of 2, whereas the hamming distance returns 27. (As mentioned earlier, I am working on a Levenshtein implementation, but it is not yet complete.)
Note that with the official records obtained from ELECT, and in accordance with the laws of VA, I do not have access to the social security number or drivers license numbers for each registration record, which would help in identifying and discriminating potential duplicate errors vs things like twins, etc. I only have the first name, middle name, last name, suffix, month of birth, day of birth, year of birth, gender, and address information that I can work with. I can therefore only take things so far before someone else (with investigative authority and ability to access those other fields) would need to step in and confirm and validate these findings.
Results:
The summary totals are as follows, with detailed examples.
Hamming Distance
0
1
2
3
Number of Potential Duplicate Registrant Pairs
1982
3276
21864
120642
Number of Potential Duplicate Ballots
110
3248
31210
175872
According to my derivations and simulations that are described in detail at the end of this article, we should only expect to see an average of 11 (+/- 3) potential duplicate pairs (a.k.a. “collisions”) at a Hamming distance of 0. This is over two orders of magnitude different than what we observe in the compiled results table above. Such a discrepancy deserves further investigation and verification.
Examples of Types of Issues Observed:
NOTE THE BELOW INFORMATION HAS HAD THE VOTER PERSONALLY IDENTIFIABLE INFORMATION (“PII”) FICTIONALIZED. WHILE THESE ARE BASED ON REAL DATA TO ILLUSTRATE THE DIFFERENT TYPES OF OBSERVATIONS, THEY DO NOT REPRESENT REAL VOTER INFORMATION.
Example #1: The following set of records has the exact match (Hamming Distance = 0) of full name and full birthdate (including year), but different address and different voter ID numbers AND there was a vote cast from each of those unique voter ID’s in the 2020 General Election. While it’s remotely possible that two individuals share the exact same name, month, day and year of birth … it is probabilistically unlikely (see section below on mathematical derivation of probabilities if interested), and should warrant further scrutiny.
Voter Record A:
AMY BETH McVOTER 12/05/1970 F 12345 CITIZEN CT
Voter Record B:
AMY BETH McVOTER 12/05/1970 F 5678 McPUBLIC DR
Example #2: This set of records has a single character different (Hamming distance of 1) in their first name, but middle name, last name, birthdate and address are identical AND both records are associated with votes that were cast in the 2020, 2021, and 2022 November General Elections. While it is possible that this is a pair of 23 year old twins (with same middle names) that live together, it at least bears looking into.
Voter Record A:
TAYLOR DAVID VOTER 02/16/2000 M 6543 OVERLOOK AVE NW
Voter Record B:
DAYLOR DAVID VOTER 02/16/2000 M 6543 OVERLOOK AVE NW
Example #3: This set of records has two characters different (Hamming distance of 2) in their birthdate, but name and address are identical AND the birth years are too close together for a child/parent relationship, AND both records are associated with votes that were cast in the 2020 and 2022 November General Elections.
Voter Record A:
REGINA DESEREE MACGUFFIN 02/05/1973 F 123 POPE AVE
Voter Record B:
REGINA DESEREE MACGUFFIN 03/07/1973 F 123 POPE AVE
Example #4: This set of records has again a single character different (Hamming distance of 1) in the first name (but not the first letter this time) and the last name, birthdate and address are identical. There were also multiple votes cast in the 2019 and 2022 November General from these registrants.
Voter Record A:
EDGARD JOHNSON 10/19/1981 M 5498 PAGELAND BLVD
Voter Record B:
EDUARD JOHNSON 10/19/1981 M 5498 PAGELAND BLVD
Example #5: This set of records has two characters different (Hamming distance of 2) in the first and middle names and the last name, birthdate, gender and address are identical. There were also multiple votes cast in the 2021 and 2022 November General from these registrants. Again it is possible that these records represent a set of twins given the information that ELECT provides.
Voter Record A:
ALANA JAVETTE THOMPSON 01/01/2003 F 123 CHARITY LN
Voter Record B:
ALAYA YAVETTE THOMPSON 01/01/2003 F 123 CHARITY LN
Example #6: The following set of records has the exact match (Hamming Distance = 0) of full name and full birthdate (including year), and same address but different voter ID numbers. There was no duplicated votes in the same election detected between the two ID numbers.
Voter Record A:
JAMES TIBERIUS KIRK 03/22/2223 M 1701 Enterprise Bridge
Voter Record B:
JAMES TIBERIUS KIRK 03/22/2223 M 1701 Enterprise Bridge
Example #7: The following set of records has the exact match (Hamming Distance = 0) of full name and full birthdate (including year), same address but different gender and voter ID numbers. There was no duplicated votes in the same election detected between the two ID numbers.
Voter Record A:
MAXWELL QUAID CLINGER 11/03/2004 M 4077 MASH DR
Voter Record B:
MAXWELL QUAID CLINGER 11/03/2004 U 4077 MASH DR
Results Dataset:
A full version of the aggregated excel data is provided below, however all voter information (ID, first name, middle name, last name, dob, gender, address) have been removed and replaced by a one-way hash number, with randomized salt, based on the voter ID. The full file with specific voter information can be provided to parties authorized by ELECT to recieve and process voter information, Election Officials, or Law Enforcement upon request.
Edited on 2022-12-15 for typo corrections, addition of Congressional District breakdown, and added commentary section.
BLUF (Bottom Line Up Front):
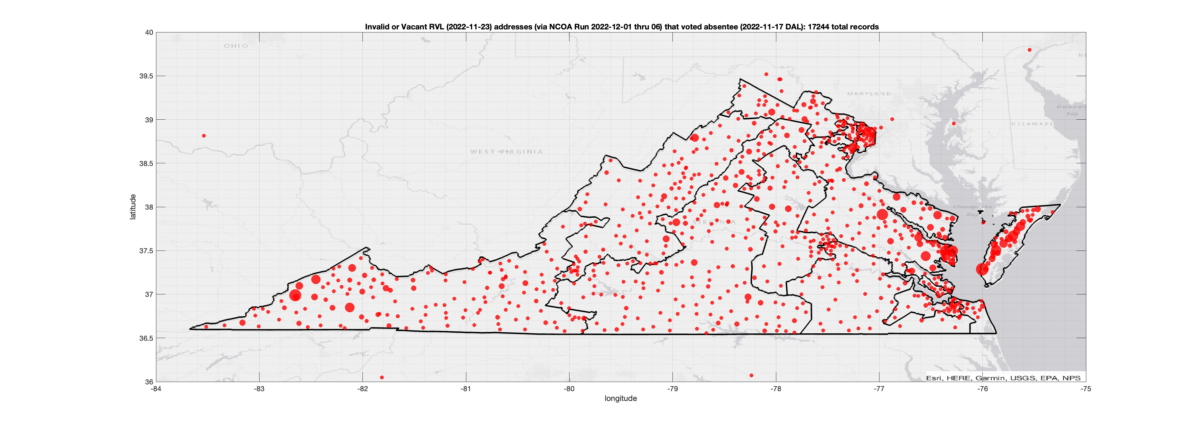
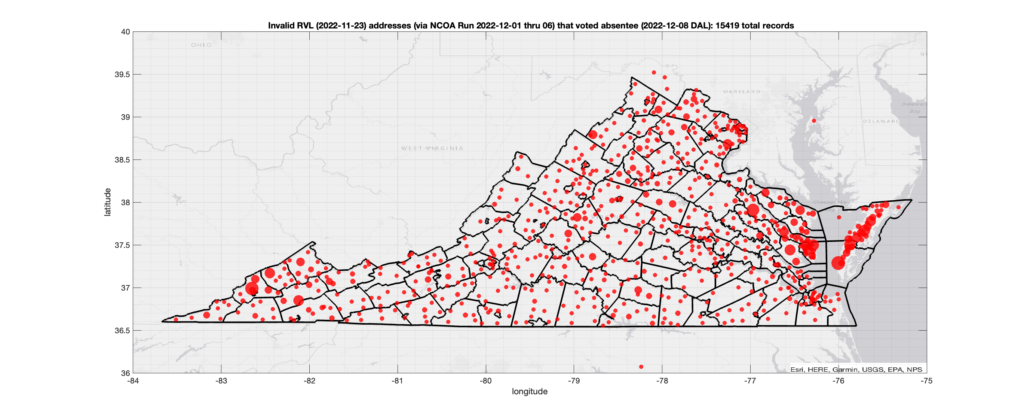
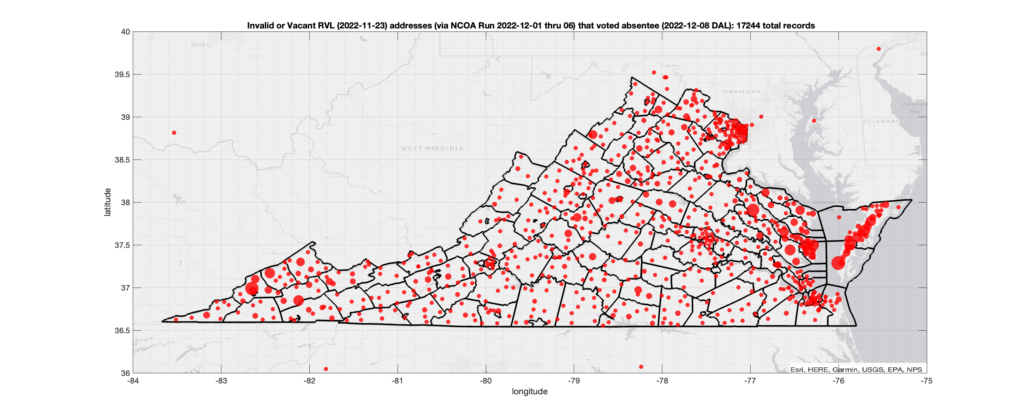
There were 15,419 ballots cast during early voting in the VA 2022 General Election where the voters’ registered address on record were flagged as “Invalid” by a National Change of Address (NCOA) database check. If we include addresses that were identified as 90-day Vacant the total rises to 17,244. Plotting the distribution of these based on the ZIP+4 identified by the NCOA check shows a disproportionate high amount of issues in the Eastern shore of VA.
A certified commercial provider of NCOA data verification was used to facilitate this analysis on raw data obtained from the VA Dept of Elections (“ELECT”). It is not technically possible to obtain a truly time-synchronized complete set of data for any election due to the way elections are run in VA, but we made every effort to obtain the data from the state as close in time as was possible. The NCOA database is maintained and curated by the United States Postal Service (USPS).
For those wishing to review specific entries, or to help validate these issues, and who are part of an organization that is able to receive and handle election information according to VA law and the VA Dept of Elections requirements, you may contact us to request the raw data breakdowns. We will need to validate your organization or employment and will make data available as legally allowed.
Commentary and Discussion (added 2022-12-15):
In response to recent interest on this matter, I would like to be very clear: We are simply presenting the data as compiled to facilitate public discourse. We have strived to only utilize data directly obtained from authoritative sources (ELECT, the USPS via TrueNCOA provider).
The designation of “Invalid” addresses is according to the definition by the USPS and TrueNCOA, i.e. the TrueNCOA check has reported the addresses as listed in the RVL have no match in the USPS database. Invalid addresses do not include things like valid P.O. Boxes or valid rural addresses.
The VA Constitution (Section II-1 and II-2) specify the requirements for voter eligibility to include that voters are required to supply a primary address for their registration record, regardless of their method of voting. VA is required by law to consistently maintain and validate these records. Based on the below analysis, the data shows that there is a small but statistically significant number of “Invalid” addresses associated for voters who cast ballots in the Nov 2022 election.
Continuing EPEC’s mission to promote voter participation, analyze election technology, and educate the public about best practices in managing election technology systems; we are providing the below analysis in order to educate and inform the public, legislators and elections officials about the existence of these discrepancies.
Details:
After receiving the results of a National Change of Address (NCOA) database check on the registration (not the temporary) addresses in the latest VA Registered Voter List (RVL). I’ve gone through and collated the flagged addresses and reconciled them with the entries in the Daily Absentee List (DAL) file records provided by the VA Dept. of Elections (“ELECT”).
The DAL file (dated 2022-12-08) provides a records of all of the voters that cast absentee (either Early In-Person or Mail-In) ballots in the election, and the RVL (dated 2022-11-23) gives all of the registered voter addresses and other pertinent information. Both datasets come directly from the VA Dept. of Elections and must be purchased. Total cost was ~$7000. The two datasets can be tied together using the voter Identification Number that is assigned to each (supposedly) unique voter by the state. Entries in the RVL should be unique to each registered voter (although there are a small number of duplicate voter IDs that I have seen … but thats for another post), whereas the DAL file can have multiple entries attributed to a single voter recording the various stages of ballot processing.
The NCOA check was performed on all addresses in the RVL file in order to detect recent moves, invalid addresses, vacant addresses, P.O. Boxes, commercial addresses, etc. The NCOA check takes multiple days to run using a commercial service provider and was executed between 2022-12-01 through 2022-12-06. The processing needed to be performed in two batches.
Results:
Raw TrueNCOA Processing result stats on the full RVA dataset:
NCOA Processing of VA RVL 2022-11-23 Records
Batch 1
Batch 2
Total
Percent
Records Processed
5,831,089
296,767
6,127,856
18 – Month NCOA Moves
264,210
12,618
276,828
4.52%
48 – Month NCOA Moves
155,274
865
156,139
2.55%
Moves with no Forwarding Address
23,651
447
24,098
0.39%
Total NCOA Moves
443,135
13,930
457,065
7.46%
Vacant Flag
26,865
1,742
28,607
0.47%
DPV Updated/Address Corrected Records
568,039
20,748
588,787
9.61%
DPV Deliverable Records
5,555,024
280,207
5,835,231
95.22%
DPV Non-Deliverable Records
173,322
12,427
185,749
3.03%
LACS Updated (Rural Address converted to Street Address)
32,116
1,327
33,443
0.55%
Residential Delivery Indicator
5,681,183
289,345
5,970,528
97.43%
Addresses matched to the USPS Database
5,728,347
292,634
6,020,981
98.26%
Invalid Addresses
102,617
4,161
106,778
1.74%
Expired Addresses
6,875
576
7,451
0.12%
Business Move (B)
339
6
345
0.01%
Family Move (F)
110,444
3,549
113,993
1.86%
Individual Move (I)
332,352
10,375
342,727
5.59%
General Delivery Address
153
0
153
0.00%
High Rise Address
703,903
62,059
765,962
12.50%
PO Box Address
26,973
770
27,743
0.45%
Rural Route Address
79
1
80
0.00%
Single Family Address
5,012,679
230,200
5,242,879
85.56%
Unknown
49,299
2,457
51,756
0.84%
Reporting as presented from the TrueNCOA data service. The TrueNCOA data dictionary is presented here.
Combining NCOA results of RVL Addresses with the DAL data:
Vacant Addresses:
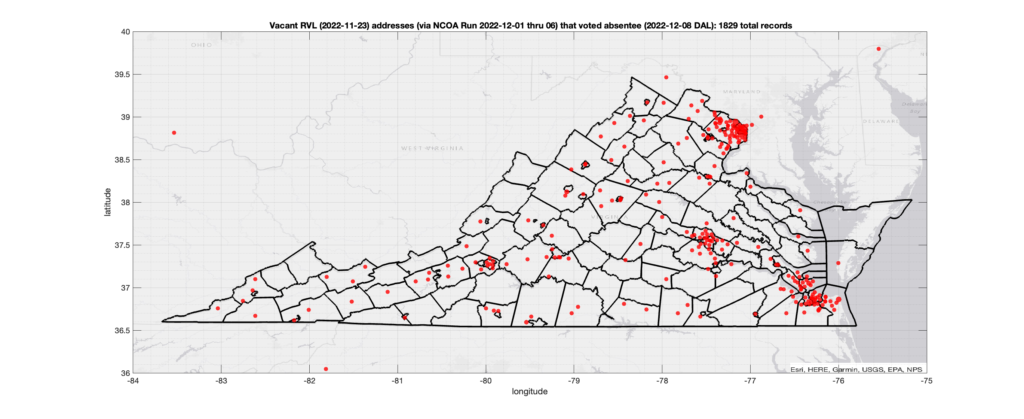
There were 1,829 records across the state with registered addresses that have been flagged as (90-day) “Vacant” by the NCOA check and also had an Early In-Person, Mail-In, FWAB or Provisional ballot cast in the VA 2022 General Election according to the DAL file. Of those records, 1,317 were Early In-Person and 491 were Mail-In. The geographic distribution of the addresses (based on the ZIP+4), as reported by the NCOA service, is shown below, with the size of the marker proportional to the total number of counts at that ZIP+4 location.
Note: This graphic was updated on Thu Dec 15 to correct a typo in the title as to the date of the DAL file that was used.
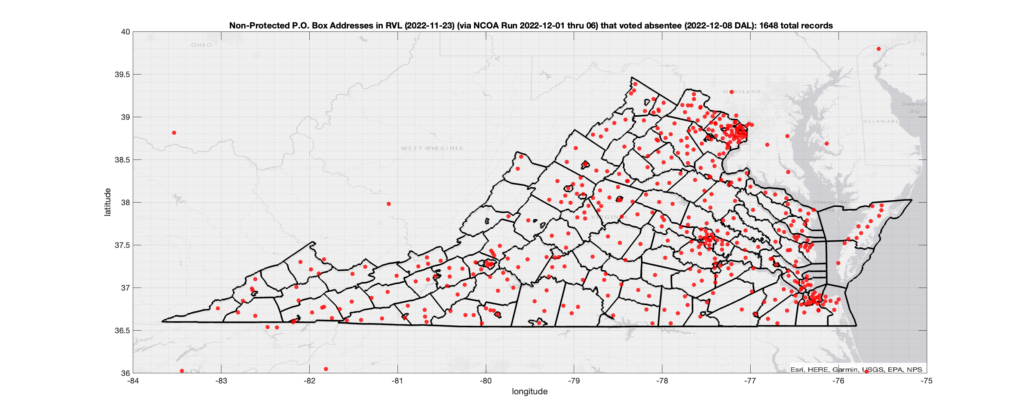
P.O. Boxes (Non-protected):
There were 1,648 records across the state with registered addresses that have been flagged as P.O. Box Addresses by the NCOA check and also had an Early In-Person, Mail-In, FWAB or Provisional ballot cast in the VA 2022 General Election AND were NOT listed as protected entries according to the DAL file. (VA allows for voters who have a legal protective order to list a P.O. Box as their address of record on public documents) Of those records, 1,348 were Early In-Person and 294 were Mail-In. The geographic distribution of the addresses (based on the ZIP+4), as reported by the NCOA service, is shown below, with the size of the marker proportional to the total number of counts at that ZIP+4 location.
Note: This graphic was updated on Thu Dec 15 to correct a typo in the title as to the date of the DAL file that was used.
Invalid Addresses:
There were 15,419 records across the state with registered addresses that have been flagged as “Invalid” Addresses by the NCOA check and also had an Early In-Person, Mail-In, FWAB or Provisional ballot cast in the VA 2022 General Election. Of those records, 12,766 were Early In-Person and 2,566 were Mail-In. The geographic distribution of the addresses (based on the ZIP+4), as reported by the NCOA service, is shown below, with the size of the marker proportional to the total number of counts at that ZIP+4 location.
Note: This graphic was updated on Thu Dec 15 to correct a typo in the title as to the date of the DAL file that was used.
Invalid OR Vacant Addresses:
There were 17,244 records across the state with registered addresses that have been flagged as “Invalid” or “Vacant” Addresses by the NCOA check and also had an Early In-Person, Mail-In, FWAB or Provisional ballot cast in the VA 2022 General Election. Of those records, 14,083 were Early In-Person and 3,053 were Mail-In. The geographic distribution of the addresses (based on the ZIP+4), as reported by the NCOA service, is shown below, with the size of the marker proportional to the total number of counts at that ZIP+4 location.
Note: This graphic was updated on Thu Dec 15 to correct a typo in the title as to the date of the DAL file that was used.
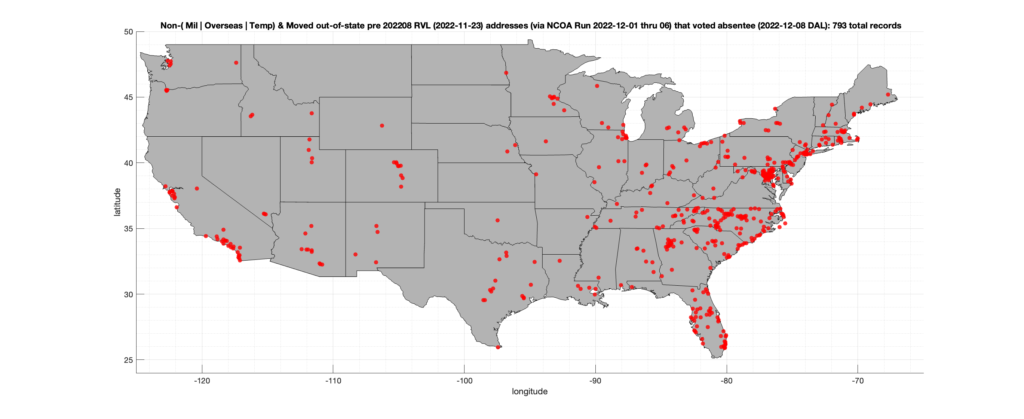
Record of Moves Out-of-State:
There were 793 records that had records of NCOA moves to valid out-of-state addresses before 2022-08 that also had an Early In-Person, Mail-In, FWAB or Provisional ballot cast in the VA 2022 General Election. Of those records, 338 were Early In-Person and 454 were Mail-In. The geographic distribution of the addresses (based on the ZIP+4), as reported by the NCOA service, is shown below, with the size of the marker proportional to the total number of counts at that ZIP+4 location.
Note: This graphic was updated on Thu Dec 15 to correct a typo in the title as to the date of the DAL file that was used.
Results By District:
This section was added 2022-12-15, per multiple requests for by-district breakouts.
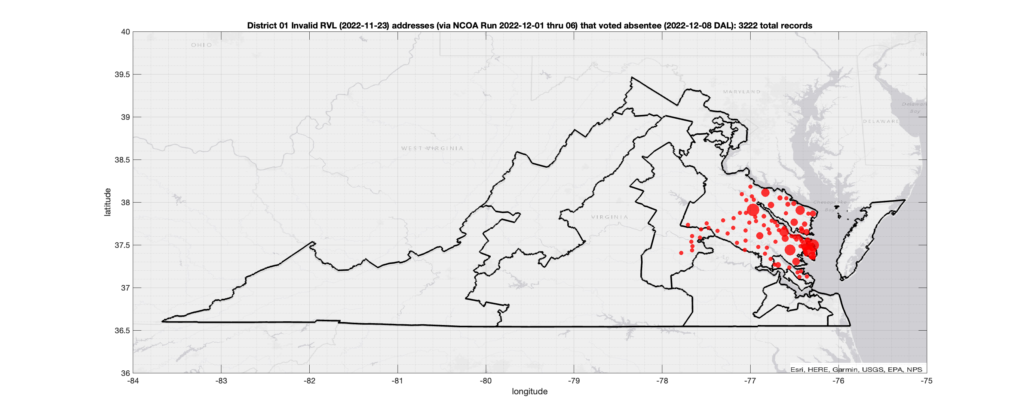
District 01:
Invalid Addresses:
There were 3,222 records with registered addresses that have been flagged as “Invalid” Addresses by the NCOA check and also had an Early In-Person, Mail-In, FWAB or Provisional ballot cast in the VA 2022 General Election in District 01. Of those records, 2,841 were Early In-Person and 364 were Mail-In. The geographic distribution of the addresses (based on the ZIP+4), as reported by the NCOA service, is shown below, with the size of the marker proportional to the total number of counts at that ZIP+4 location.
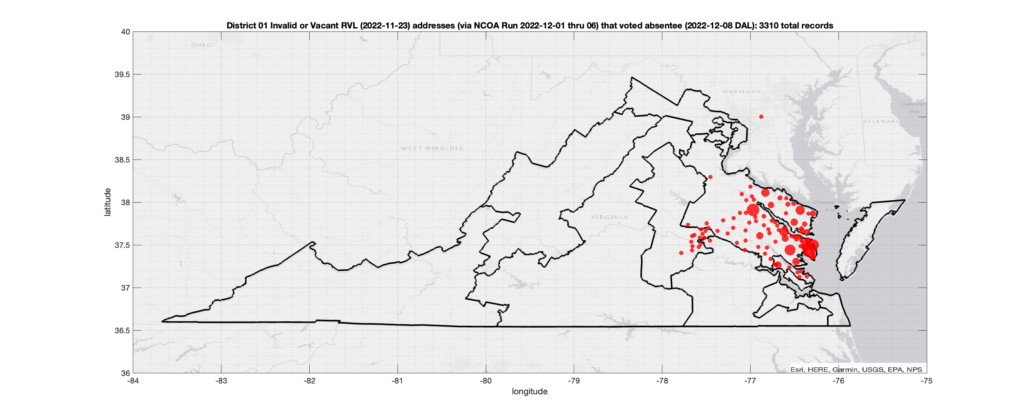
Invalid OR Vacant Addresses:
There were 3,310 records with registered addresses that have been flagged as “Invalid” or “Vacant” Addresses by the NCOA check and also had an Early In-Person, Mail-In, FWAB or Provisional ballot cast in the VA 2022 General Election in District 01. Of those records, 2,909 were Early In-Person and 384 were Mail-In. The geographic distribution of the addresses (based on the ZIP+4), as reported by the NCOA service, is shown below, with the size of the marker proportional to the total number of counts at that ZIP+4 location.
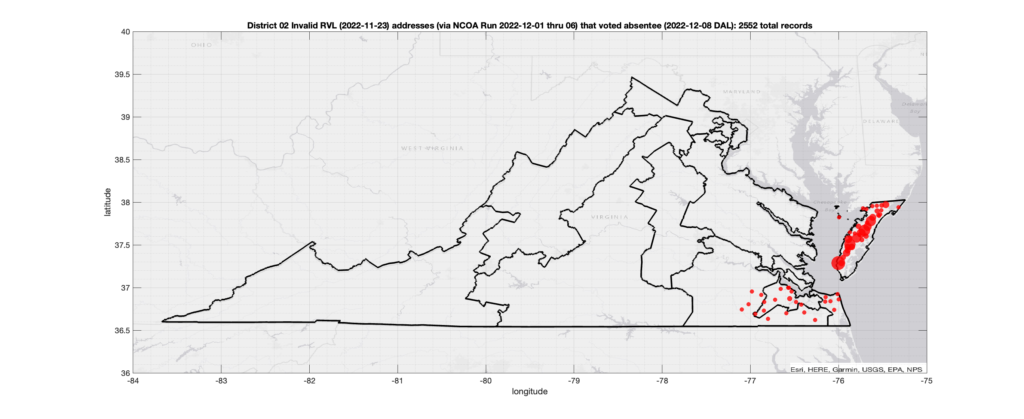
District 02:
Invalid Addresses:
There were 2,552 records with registered addresses that have been flagged as “Invalid” Addresses by the NCOA check and also had an Early In-Person, Mail-In, FWAB or Provisional ballot cast in the VA 2022 General Election in District 02. Of those records, 2,185 were Early In-Person and 353 were Mail-In. The geographic distribution of the addresses (based on the ZIP+4), as reported by the NCOA service, is shown below, with the size of the marker proportional to the total number of counts at that ZIP+4 location.
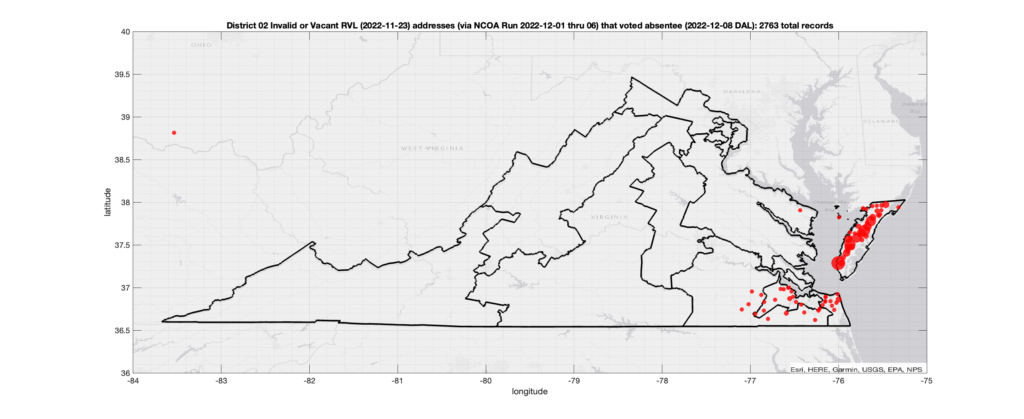
Invalid OR Vacant Addresses:
There were 2,763 records with registered addresses that have been flagged as “Invalid” or “Vacant” Addresses by the NCOA check and also had an Early In-Person, Mail-In, FWAB or Provisional ballot cast in the VA 2022 General Election in District 02. Of those records, 2,346 were Early In-Person and 400 were Mail-In. The geographic distribution of the addresses (based on the ZIP+4), as reported by the NCOA service, is shown below, with the size of the marker proportional to the total number of counts at that ZIP+4 location.
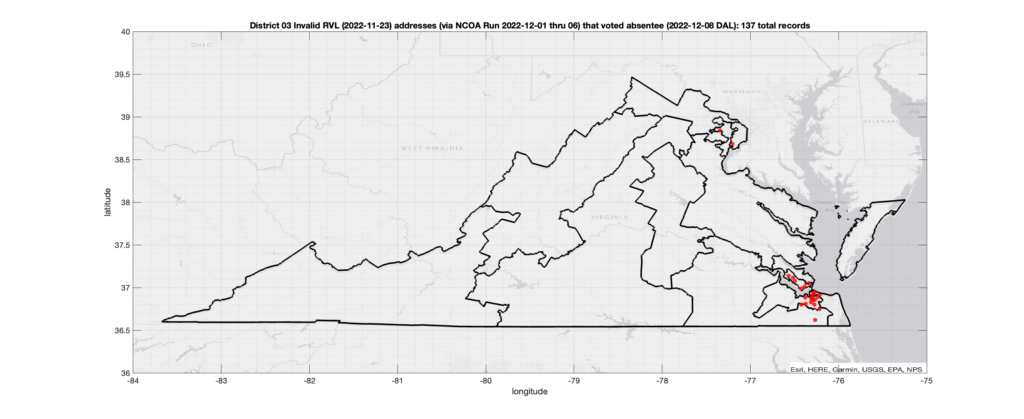
District 03:
Invalid Addresses:
There were 137 records with registered addresses that have been flagged as “Invalid” Addresses by the NCOA check and also had an Early In-Person, Mail-In, FWAB or Provisional ballot cast in the VA 2022 General Election in District 03. Of those records, 97 were Early In-Person and 34 were Mail-In. The geographic distribution of the addresses (based on the ZIP+4), as reported by the NCOA service, is shown below, with the size of the marker proportional to the total number of counts at that ZIP+4 location.
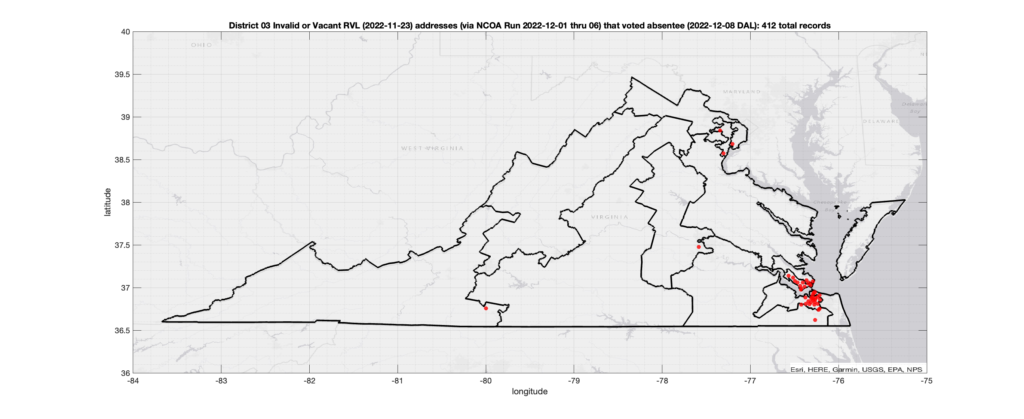
Invalid OR Vacant Addresses:
There were 412 records with registered addresses that have been flagged as “Invalid” or “Vacant” Addresses by the NCOA check and also had an Early In-Person, Mail-In, FWAB or Provisional ballot cast in the VA 2022 General Election in District 03. Of those records, 283 were Early In-Person and 117 were Mail-In. The geographic distribution of the addresses (based on the ZIP+4), as reported by the NCOA service, is shown below, with the size of the marker proportional to the total number of counts at that ZIP+4 location.
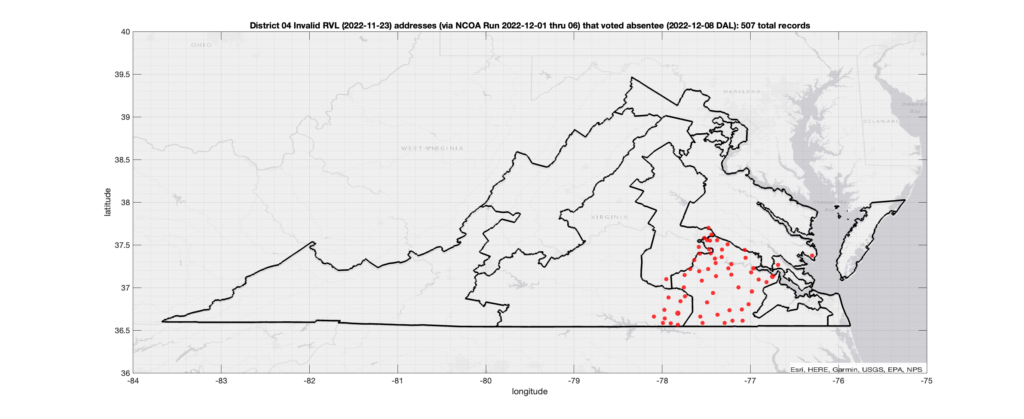
District 04:
Invalid Addresses:
There were 507 records with registered addresses that have been flagged as “Invalid” Addresses by the NCOA check and also had an Early In-Person, Mail-In, FWAB or Provisional ballot cast in the VA 2022 General Election in District 04. Of those records, 423 were Early In-Person and 78 were Mail-In. The geographic distribution of the addresses (based on the ZIP+4), as reported by the NCOA service, is shown below, with the size of the marker proportional to the total number of counts at that ZIP+4 location.
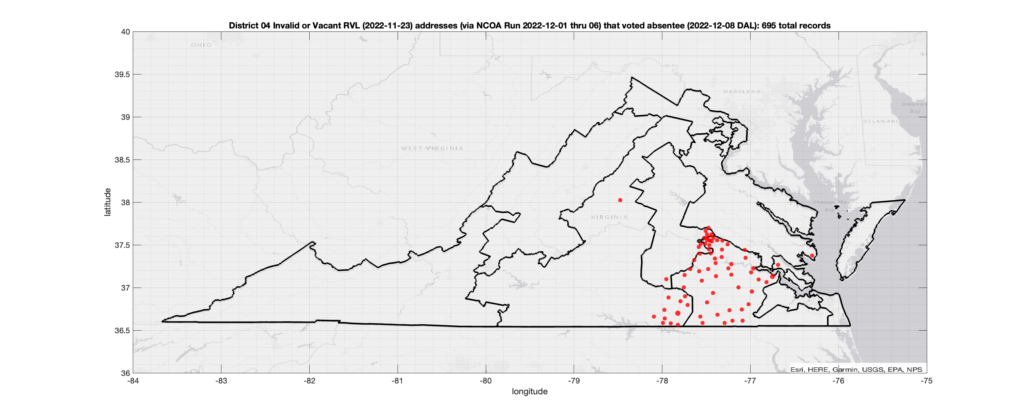
Invalid OR Vacant Addresses:
There were 695 records with registered addresses that have been flagged as “Invalid” or “Vacant” Addresses by the NCOA check and also had an Early In-Person, Mail-In, FWAB or Provisional ballot cast in the VA 2022 General Election in District 04. Of those records, 567 were Early In-Person and 121 were Mail-In. The geographic distribution of the addresses (based on the ZIP+4), as reported by the NCOA service, is shown below, with the size of the marker proportional to the total number of counts at that ZIP+4 location.
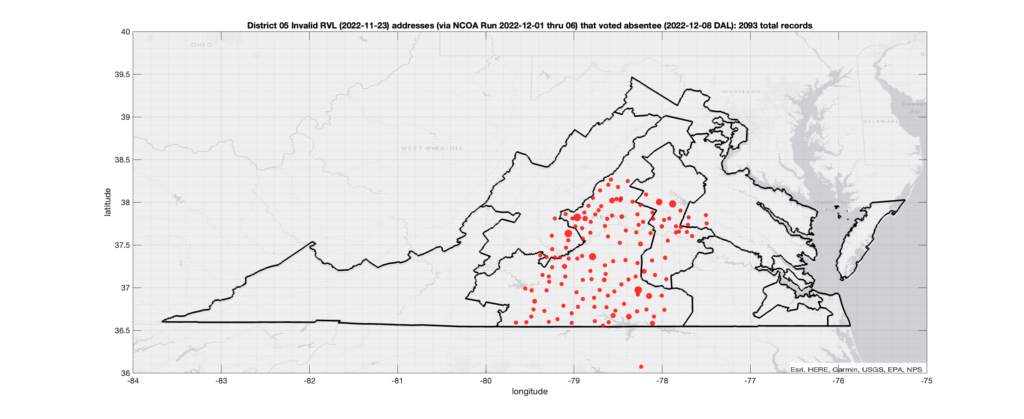
District 05:
Invalid Addresses:
There were 2,093 records with registered addresses that have been flagged as “Invalid” Addresses by the NCOA check and also had an Early In-Person, Mail-In, FWAB or Provisional ballot cast in the VA 2022 General Election in District 05. Of those records, 1,738 were Early In-Person and 348 were Mail-In. The geographic distribution of the addresses (based on the ZIP+4), as reported by the NCOA service, is shown below, with the size of the marker proportional to the total number of counts at that ZIP+4 location.
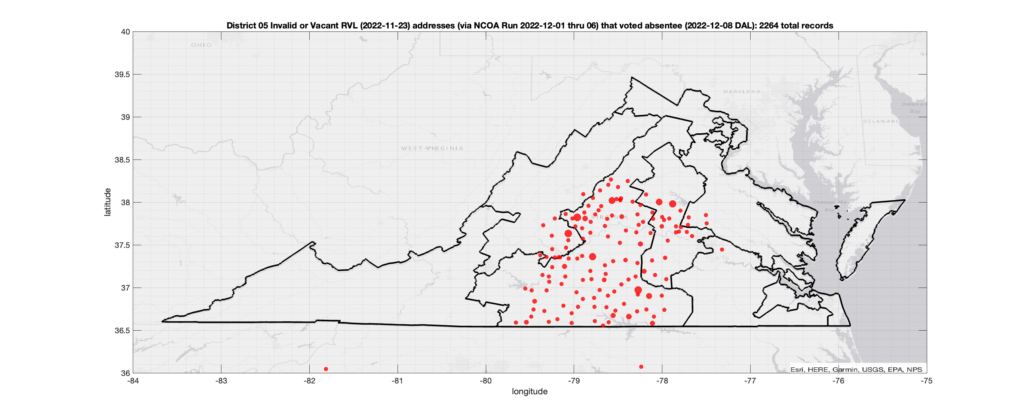
Invalid OR Vacant Addresses:
There were 2,264 records with registered addresses that have been flagged as “Invalid” or “Vacant” Addresses by the NCOA check and also had an Early In-Person, Mail-In, FWAB or Provisional ballot cast in the VA 2022 General Election in District 05. Of those records, 1,860 were Early In-Person and 395 were Mail-In. The geographic distribution of the addresses (based on the ZIP+4), as reported by the NCOA service, is shown below, with the size of the marker proportional to the total number of counts at that ZIP+4 location.
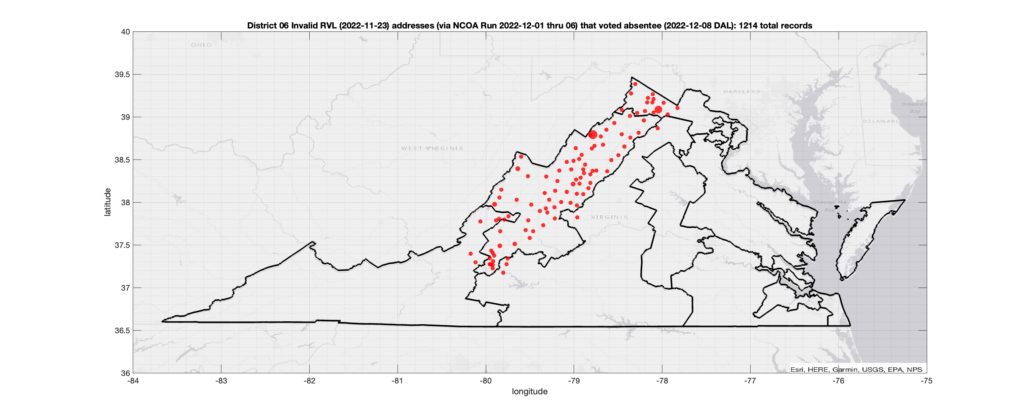
District 06:
Invalid Addresses:
There were 1,214 records with registered addresses that have been flagged as “Invalid” Addresses by the NCOA check and also had an Early In-Person, Mail-In, FWAB or Provisional ballot cast in the VA 2022 General Election in District 06. Of those records, 990 were Early In-Person and 212 were Mail-In. The geographic distribution of the addresses (based on the ZIP+4), as reported by the NCOA service, is shown below, with the size of the marker proportional to the total number of counts at that ZIP+4 location.
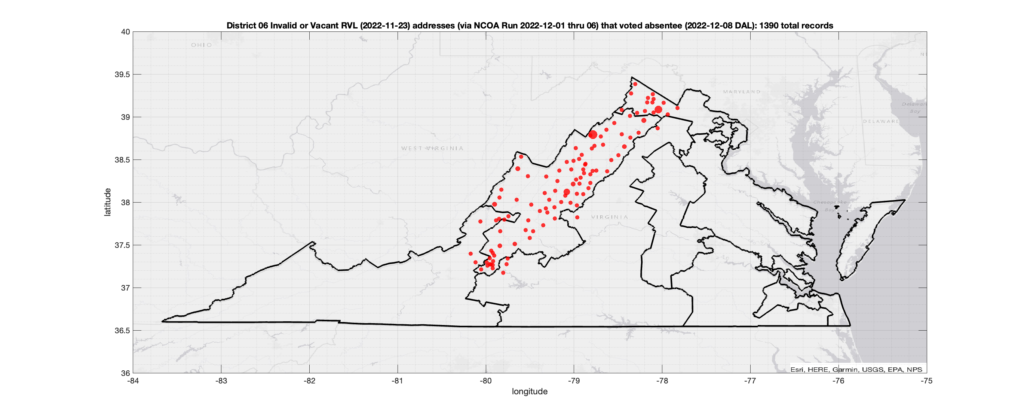
Invalid OR Vacant Addresses:
There were 1,390 records with registered addresses that have been flagged as “Invalid” or “Vacant” Addresses by the NCOA check and also had an Early In-Person, Mail-In, FWAB or Provisional ballot cast in the VA 2022 General Election in District 06. Of those records, 1,129 were Early In-Person and 247 were Mail-In. The geographic distribution of the addresses (based on the ZIP+4), as reported by the NCOA service, is shown below, with the size of the marker proportional to the total number of counts at that ZIP+4 location.
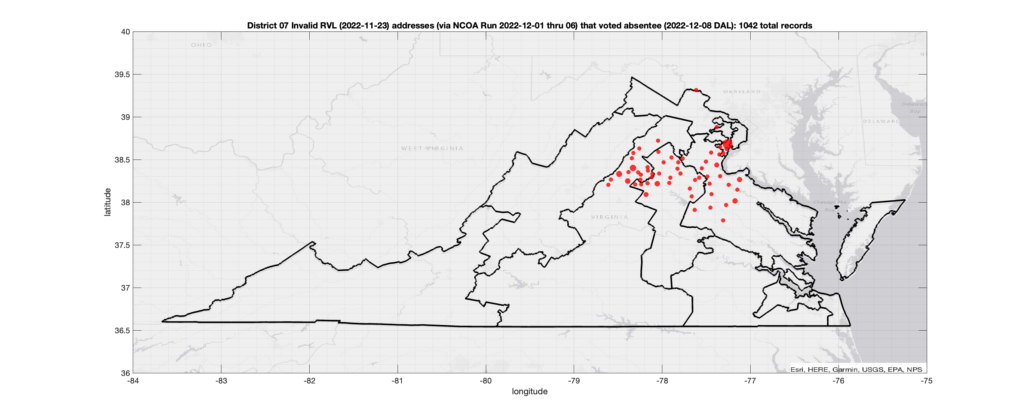
District 07:
Invalid Addresses:
There were 1,042 records with registered addresses that have been flagged as “Invalid” Addresses by the NCOA check and also had an Early In-Person, Mail-In, FWAB or Provisional ballot cast in the VA 2022 General Election in District 07. Of those records, 868 were Early In-Person and 167 were Mail-In. The geographic distribution of the addresses (based on the ZIP+4), as reported by the NCOA service, is shown below, with the size of the marker proportional to the total number of counts at that ZIP+4 location.
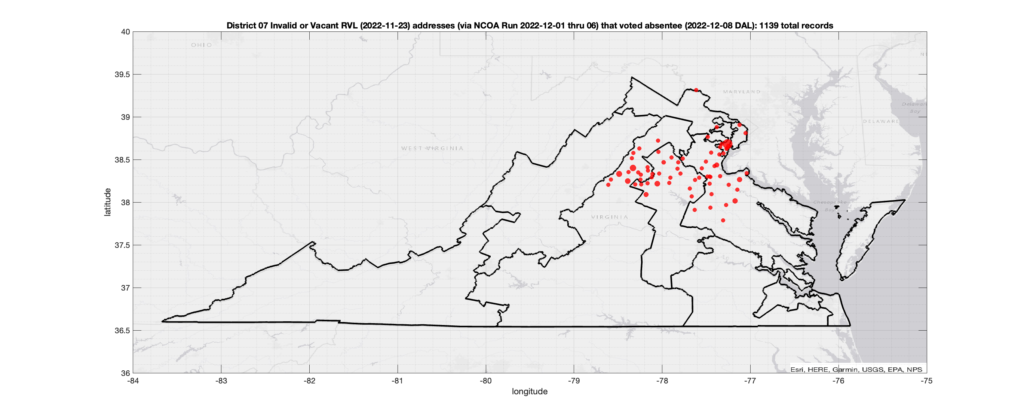
Invalid OR Vacant Addresses:
There were 1,139 records with registered addresses that have been flagged as “Invalid” or “Vacant” Addresses by the NCOA check and also had an Early In-Person, Mail-In, FWAB or Provisional ballot cast in the VA 2022 General Election in District 07. Of those records, 946 were Early In-Person and 183 were Mail-In. The geographic distribution of the addresses (based on the ZIP+4), as reported by the NCOA service, is shown below, with the size of the marker proportional to the total number of counts at that ZIP+4 location.
District 08:
Invalid Addresses:
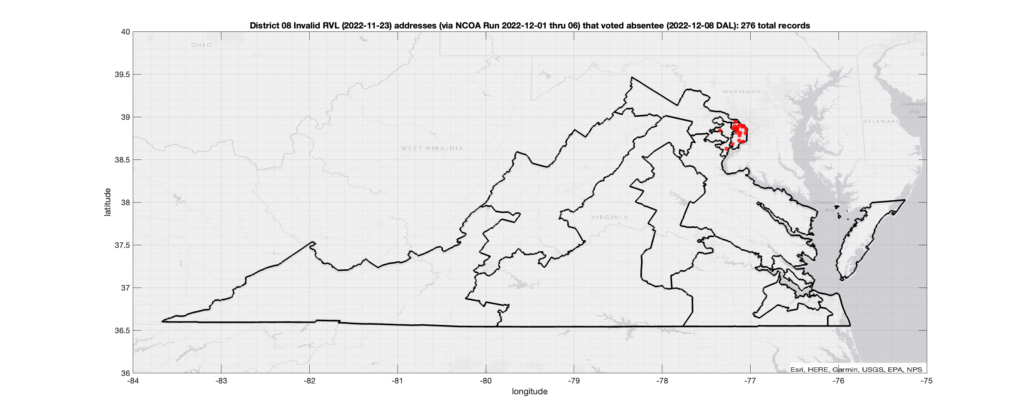
There were 276 records with registered addresses that have been flagged as “Invalid” Addresses by the NCOA check and also had an Early In-Person, Mail-In, FWAB or Provisional ballot cast in the VA 2022 General Election in District 08. Of those records, 148 were Early In-Person and 125 were Mail-In. The geographic distribution of the addresses (based on the ZIP+4), as reported by the NCOA service, is shown below, with the size of the marker proportional to the total number of counts at that ZIP+4 location.
Invalid OR Vacant Addresses:
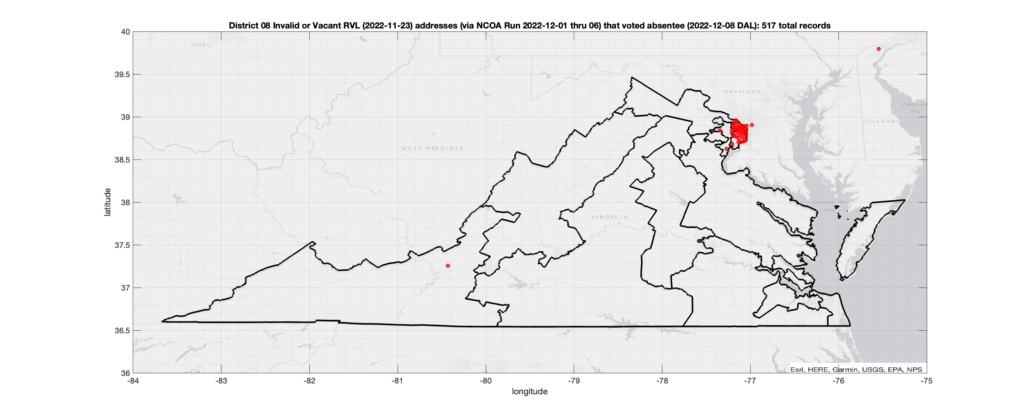
There were 517 records with registered addresses that have been flagged as “Invalid” or “Vacant” Addresses by the NCOA check and also had an Early In-Person, Mail-In, FWAB or Provisional ballot cast in the VA 2022 General Election in District 08. Of those records, 300 were Early In-Person and 212 were Mail-In. The geographic distribution of the addresses (based on the ZIP+4), as reported by the NCOA service, is shown below, with the size of the marker proportional to the total number of counts at that ZIP+4 location.
District 09:
Invalid Addresses:
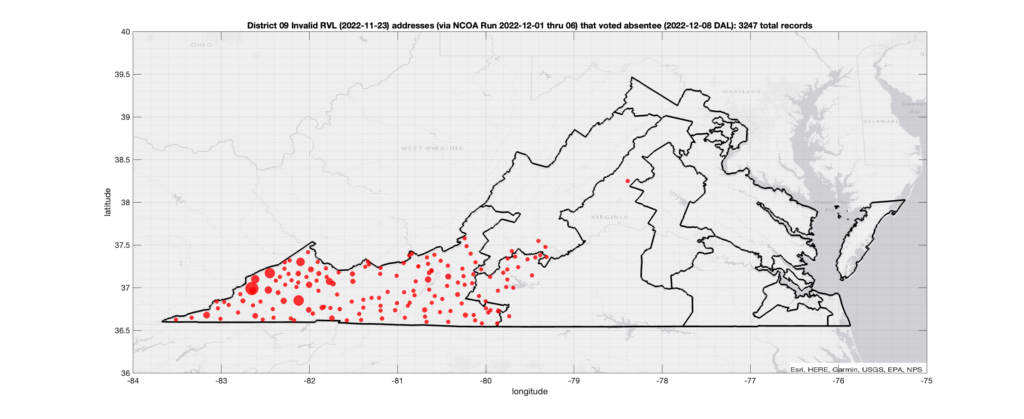
There were 3,247 records with registered addresses that have been flagged as “Invalid” Addresses by the NCOA check and also had an Early In-Person, Mail-In, FWAB or Provisional ballot cast in the VA 2022 General Election in District 09. Of those records, 2,639 were Early In-Person and 597 were Mail-In. The geographic distribution of the addresses (based on the ZIP+4), as reported by the NCOA service, is shown below, with the size of the marker proportional to the total number of counts at that ZIP+4 location.
Invalid OR Vacant Addresses:
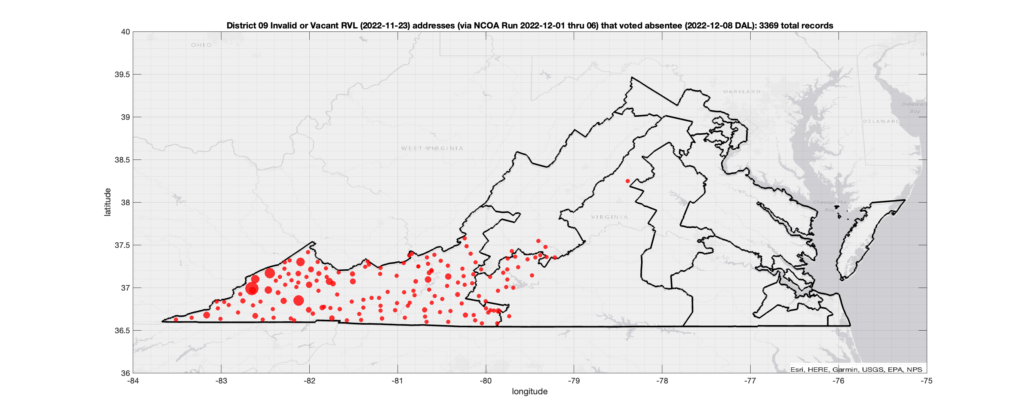
There were 3,369 records with registered addresses that have been flagged as “Invalid” or “Vacant” Addresses by the NCOA check and also had an Early In-Person, Mail-In, FWAB or Provisional ballot cast in the VA 2022 General Election in District 09. Of those records, 2,733 were Early In-Person and 624 were Mail-In. The geographic distribution of the addresses (based on the ZIP+4), as reported by the NCOA service, is shown below, with the size of the marker proportional to the total number of counts at that ZIP+4 location.
District 10:
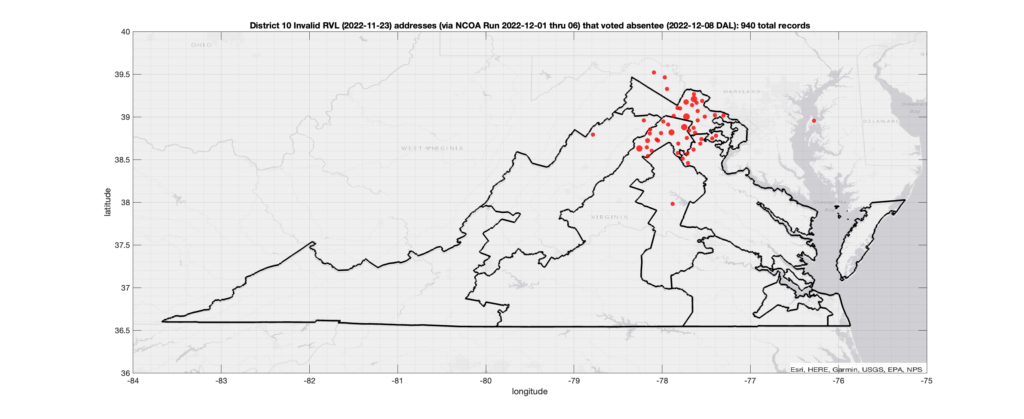
Invalid Addresses:
There were 940 records with registered addresses that have been flagged as “Invalid” Addresses by the NCOA check and also had an Early In-Person, Mail-In, FWAB or Provisional ballot cast in the VA 2022 General Election in District 10. Of those records, 740 were Early In-Person and 198 were Mail-In. The geographic distribution of the addresses (based on the ZIP+4), as reported by the NCOA service, is shown below, with the size of the marker proportional to the total number of counts at that ZIP+4 location.
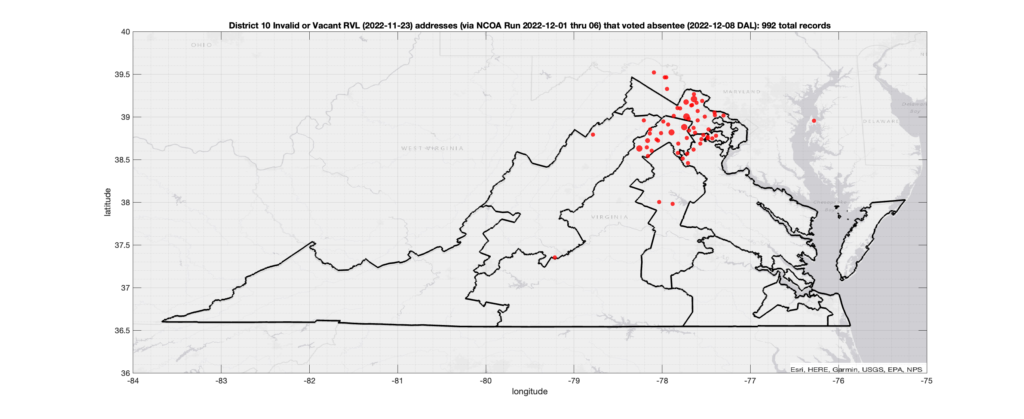
Invalid OR Vacant Addresses:
There were 992 records with registered addresses that have been flagged as “Invalid” or “Vacant” Addresses by the NCOA check and also had an Early In-Person, Mail-In, FWAB or Provisional ballot cast in the VA 2022 General Election in District 10. Of those records, 783 were Early In-Person and 207 were Mail-In. The geographic distribution of the addresses (based on the ZIP+4), as reported by the NCOA service, is shown below, with the size of the marker proportional to the total number of counts at that ZIP+4 location.
District 11:
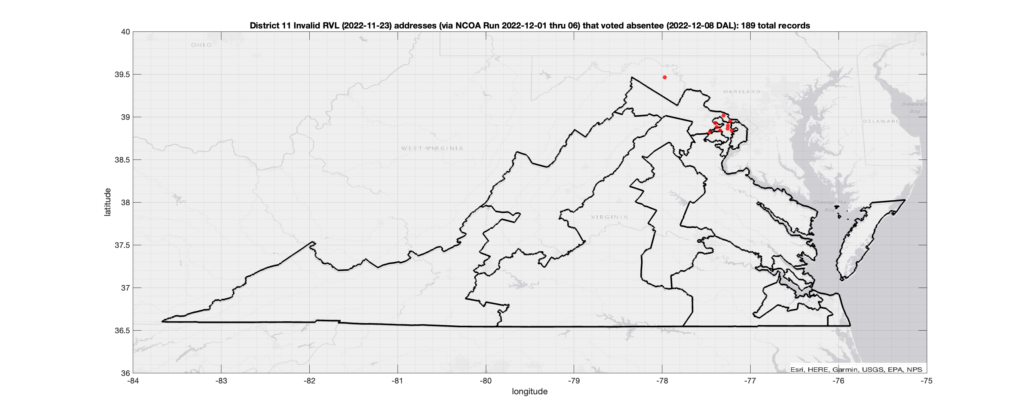
Invalid Addresses:
There were 189 records with registered addresses that have been flagged as “Invalid” Addresses by the NCOA check and also had an Early In-Person, Mail-In, FWAB or Provisional ballot cast in the VA 2022 General Election in District 11. Of those records, 97 were Early In-Person and 90 were Mail-In. The geographic distribution of the addresses (based on the ZIP+4), as reported by the NCOA service, is shown below, with the size of the marker proportional to the total number of counts at that ZIP+4 location.
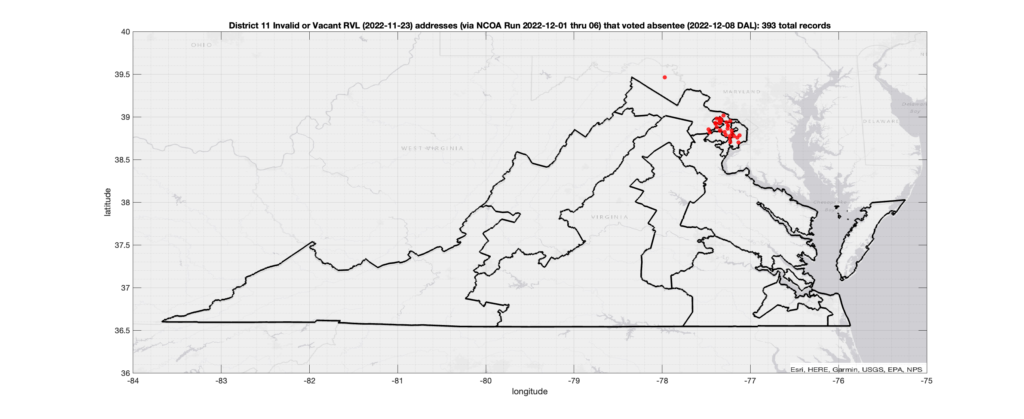
Invalid OR Vacant Addresses:
There were 393 records with registered addresses that have been flagged as “Invalid” or “Vacant” Addresses by the NCOA check and also had an Early In-Person, Mail-In, FWAB or Provisional ballot cast in the VA 2022 General Election in District 11. Of those records, 227 were Early In-Person and 163 were Mail-In. The geographic distribution of the addresses (based on the ZIP+4), as reported by the NCOA service, is shown below, with the size of the marker proportional to the total number of counts at that ZIP+4 location.
Summary Data Files by Locality:
The complete set of graphics and statistics for each locality, and each congressional district in VA can be downloaded here as a zip file. The tabulated summary results can also be downloaded in excel, csv, or numbers format:
I’ve stumbled across an interesting data artifact that I’m not sure what to make of. But I will present it here for completeness.
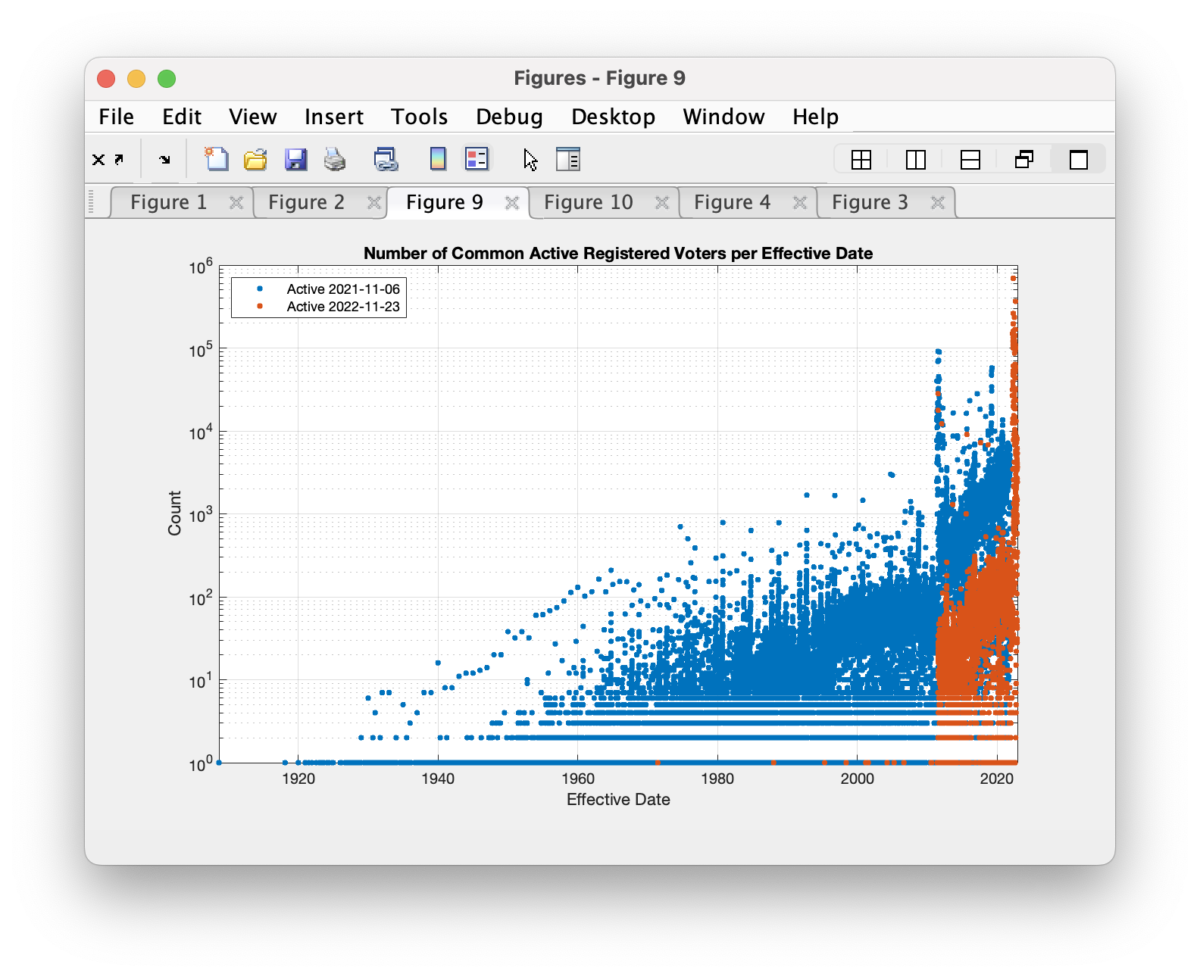
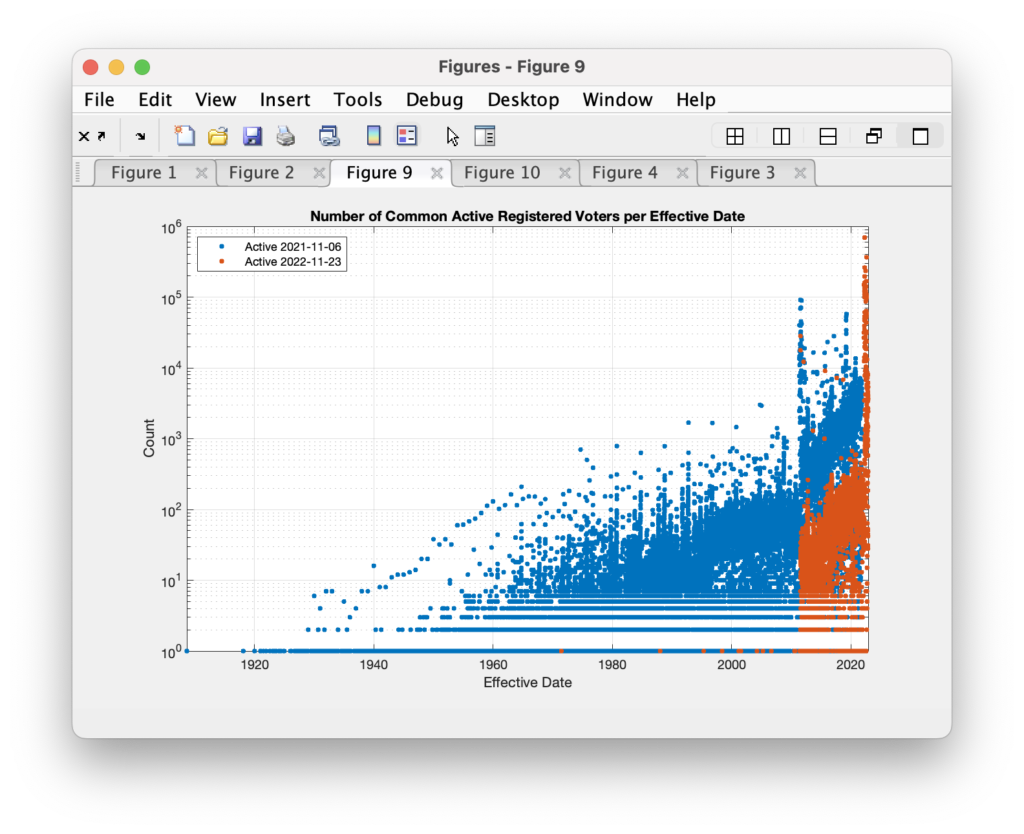
In the Registered Voter List available from the VA Dept of Elections (“ELECT”), each record of a registered voter has an “effective date” associated with it. This can be the same as the actual registration date, or the date that the voters record is returned to “active” status, etc. It appears that sometime within the last year, almost all of the voter registrations with a previous effective date earlier than June 2011 have had their effective date reassigned.
For this analysis I am using an RVL that I purchased from ELECT on 2021-11-06 and comparing it with an RVL purchased on 2022-11-22. I am only comparing the records associated with common voter IDs between each dataset. Any new or removed voters in the last year have been removed from the data and the corresponding plots below.
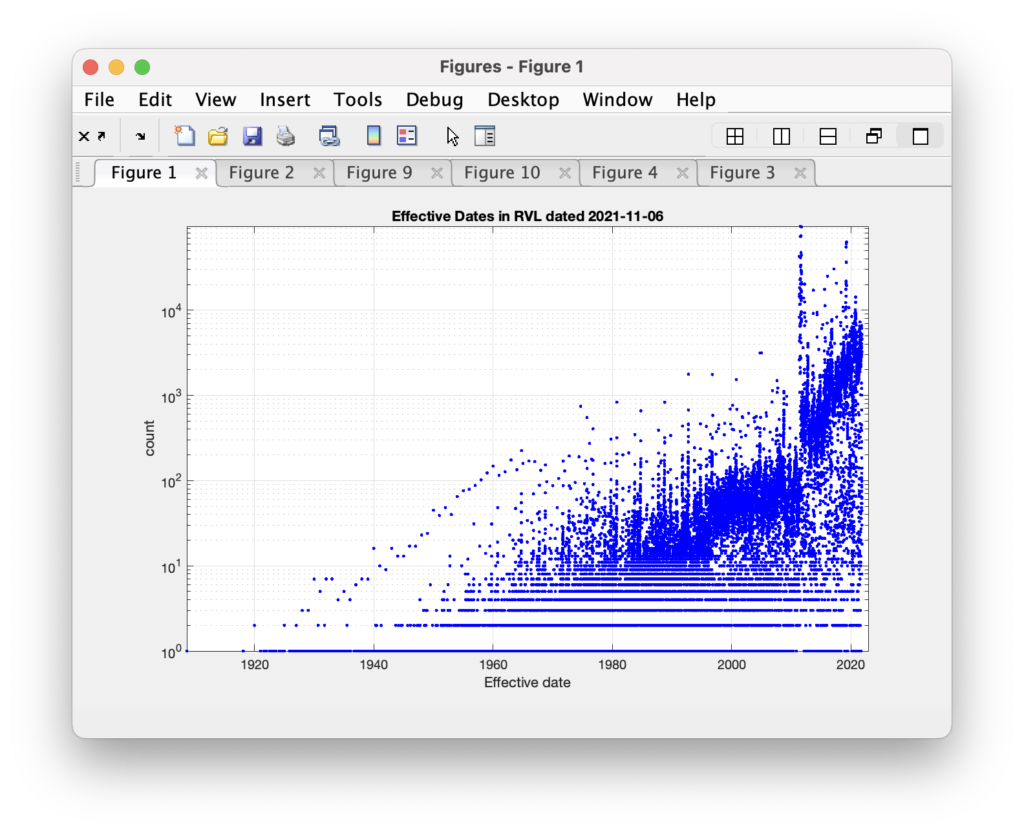
In the 2021 RVL, we can see the distribution of the effective dates in the histogram below. The majority of records have rather recent effective dates, but there are diminishing tails from long-term voters who’s effective date of their registration goes back many years. (The y-axis in the plot is logarithmic, so we can better see the shape of the distribution tails.)
This isn’t all-together so surprising. Newer voters, or voters who have made recent changes to their registration information, will likely get an updated effective date on their voter registration record. Older, or longer term voters, that have not made any recent changes and stay active would show older effective dates on their records.
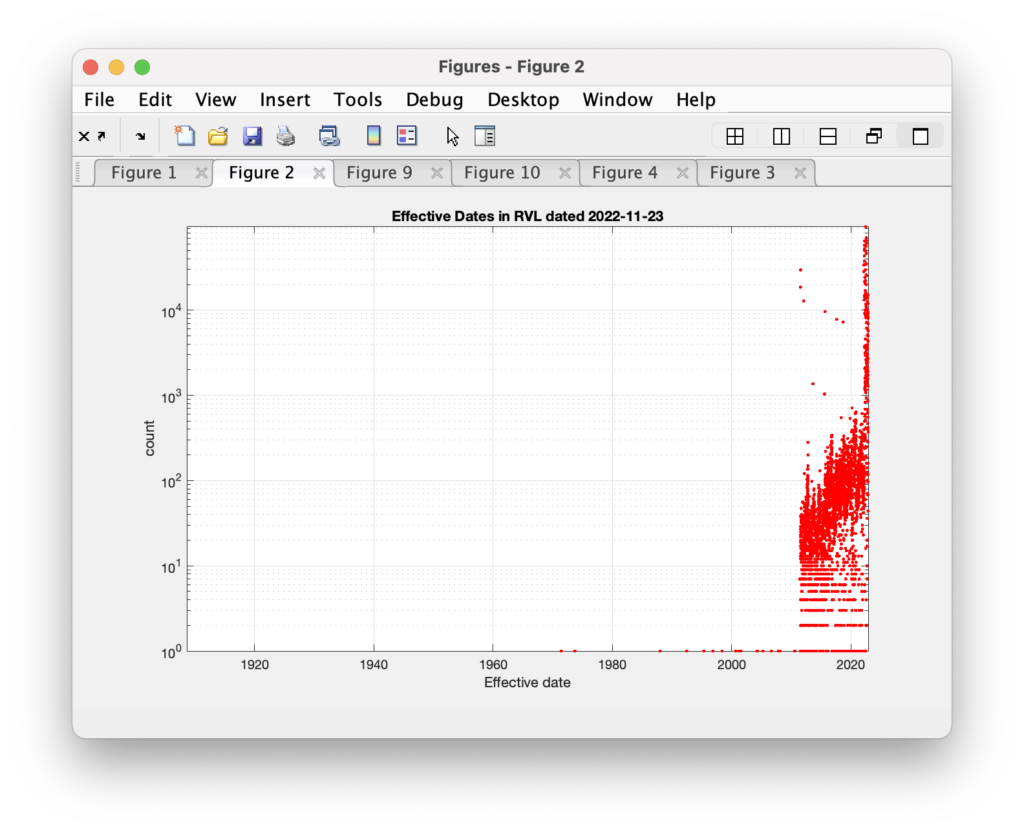
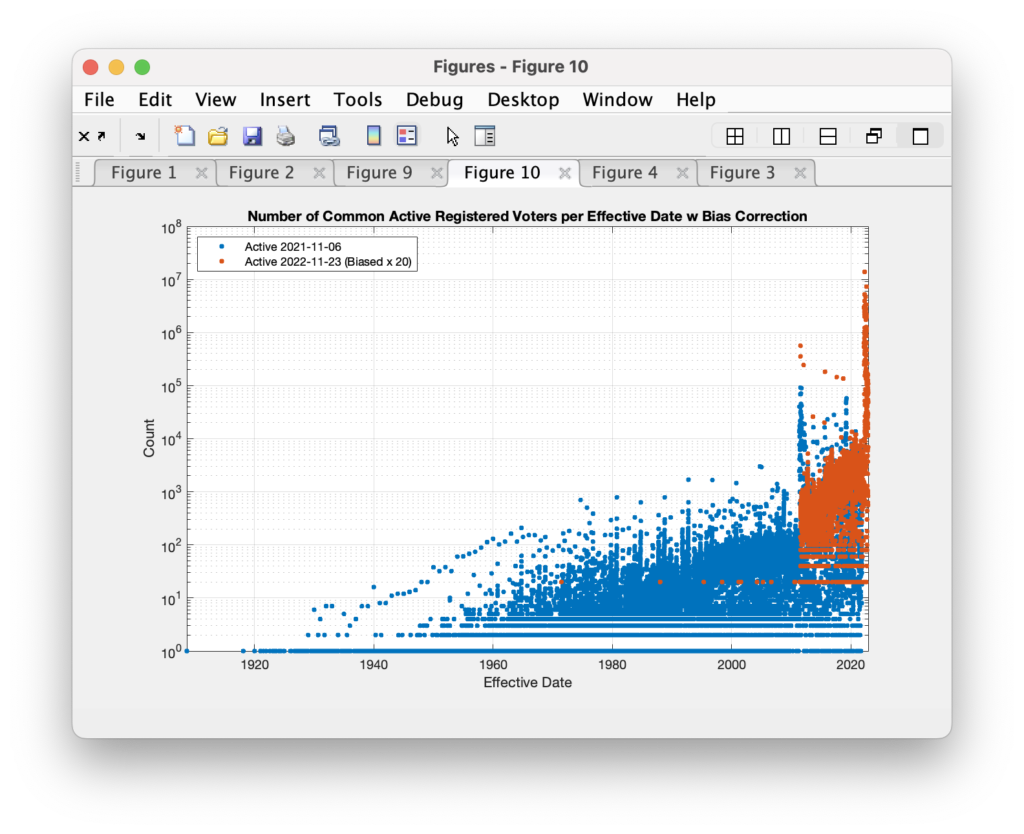
Now compare that to the RVL file dated 2022-11-22. Again, this comparison and the data in these plots is only those records that share common voter ids between the two files. Sometime between the time I downloaded the 2021-11-06 RVL and the 2022-11-22 RVL, almost all records with effective dates before July 2011 have had their effective dates reset to a more recent date.
I don’t really know what to make of this. Was there a mass update of voter registration records? Or a database restore, or some other operation on the records?
Even more interesting is when we superimpose the two histograms we see that the 2022 records with effective date after July 2011 look to also have had a significant percentage of dates reset. We see the red curve maintains it shape, save for the large spike at the far right, but is shifted lower … as if a constant percentage of the records have been included in the effective date shift.
Now if we apply a constant multiplier of 20x to the red (2022) dataset we can mostly re-align the histograms.
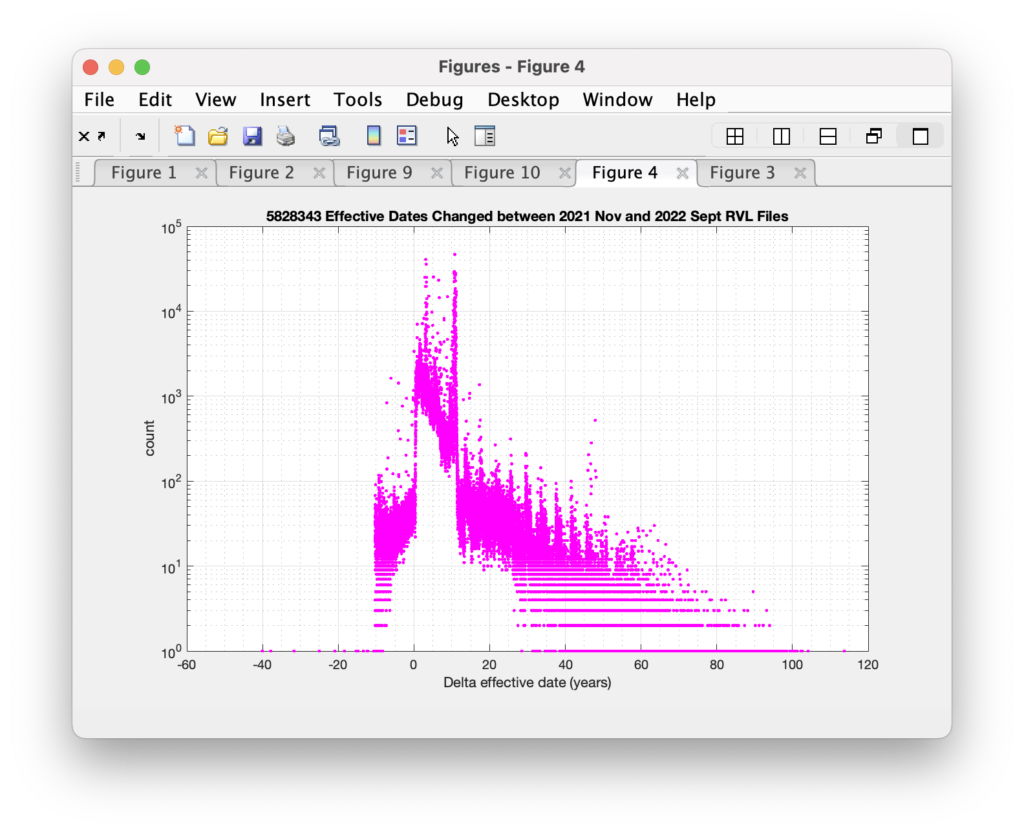
Of the effective dates that were changed between the two files, the distribution of the adjustments to the effective dates is shown below. I find it interesting that there are a number of records where the effective date has been moved backwards (?) in time.
We know there have been significant issues with the database used by ELECT (known as the “VERIS” database), so maybe this is an artifact of some maintenance operations or repairs on the data entries? Or maybe this is a symptom of a larger problem. Whatever it is, it doesn’t make a lot of sense in what should be a very well maintained and authoritative set of records.
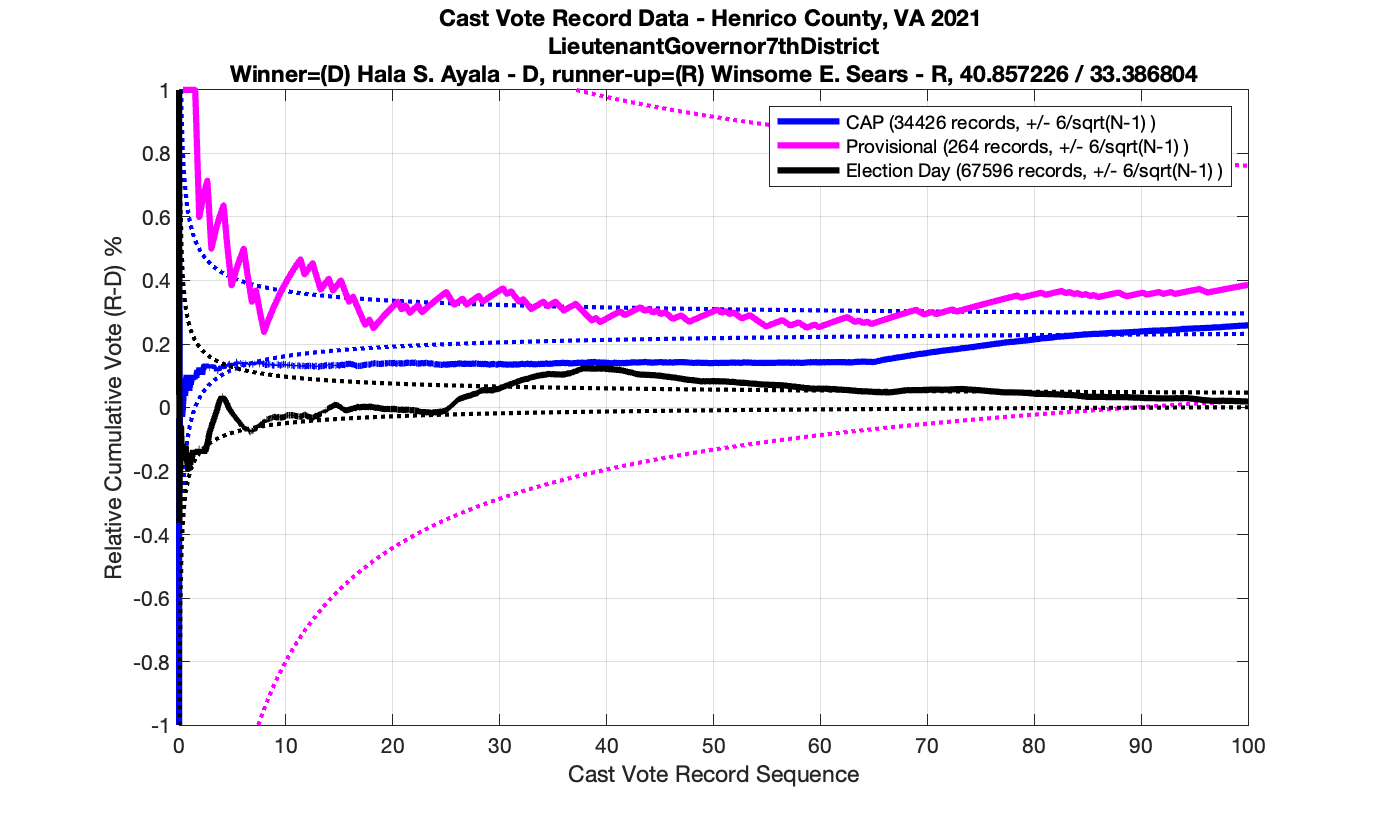
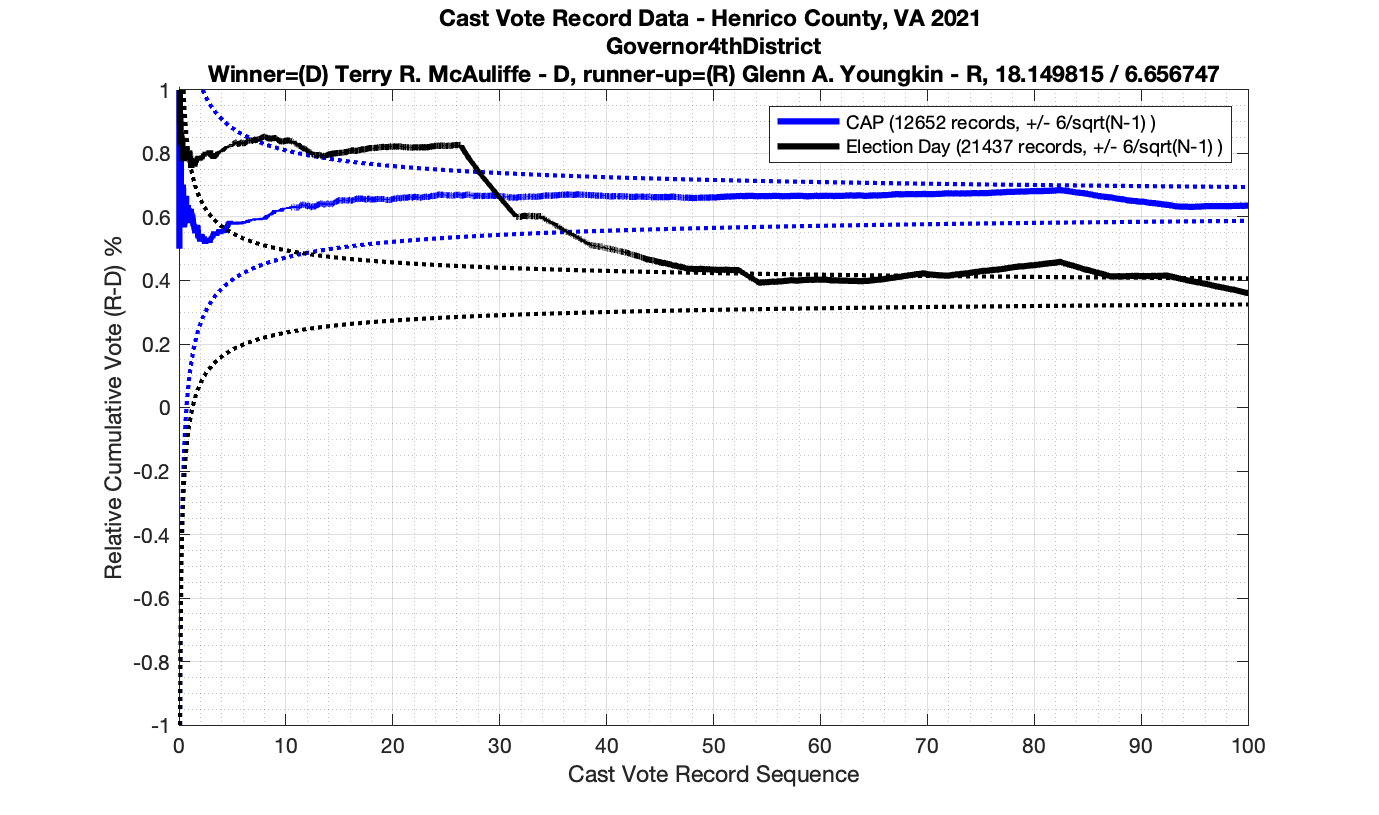
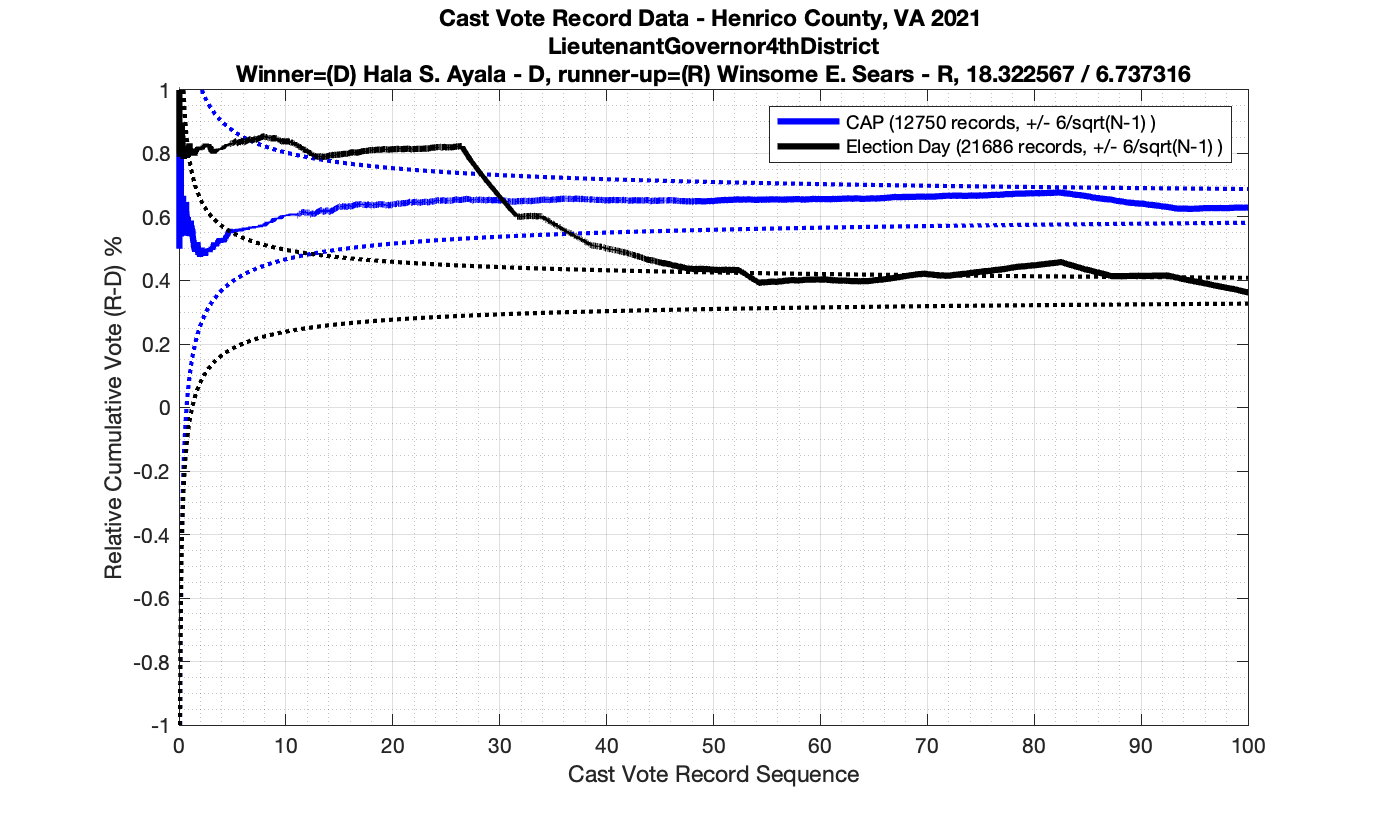
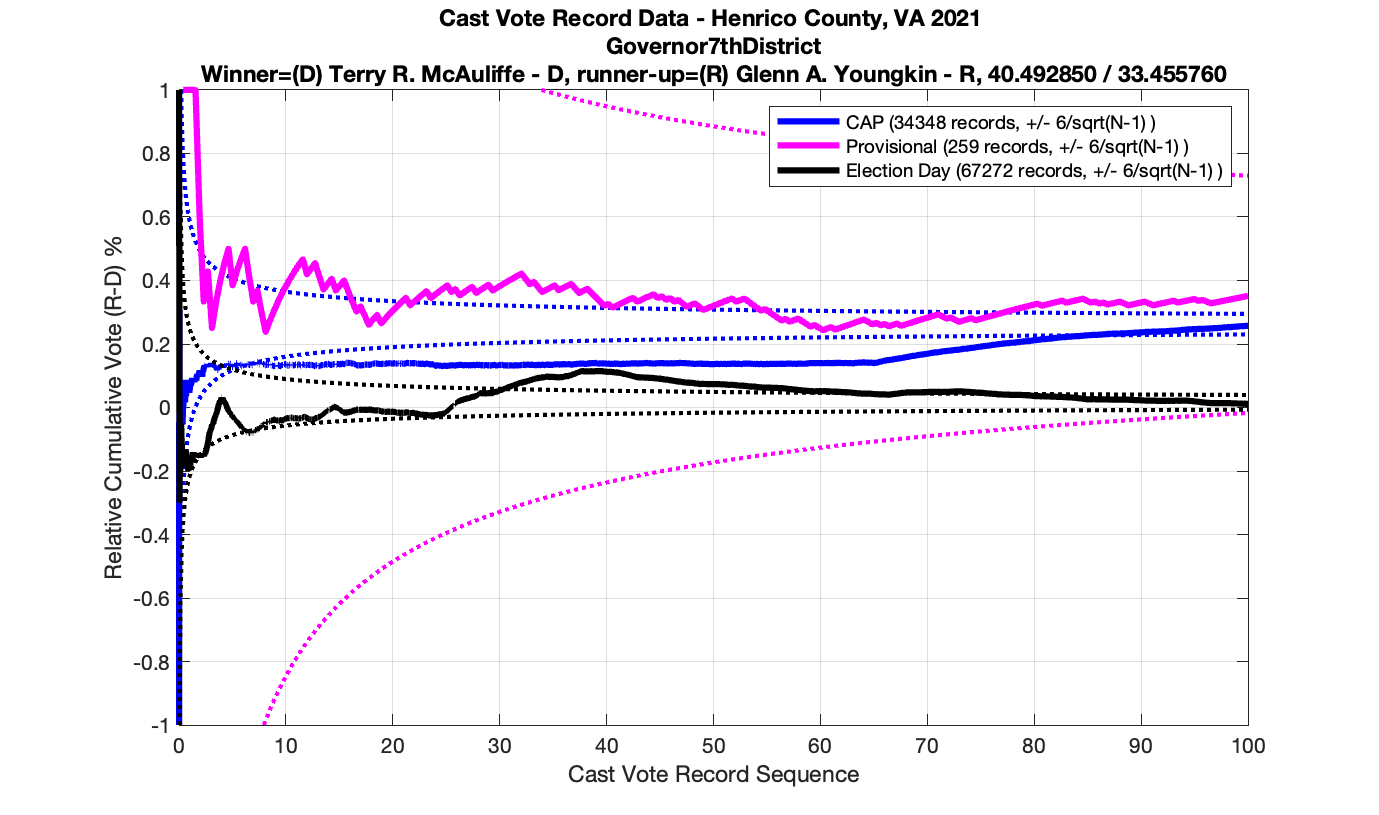
Since I posted my initial analysis of the Henrico CVR data, one comment was made to me by a member of the Texas election integrity group I have been working with: We have been assuming, based on vendor documentation and the laws and requirements in various states, that when a cast vote record is produced by vendor software the results are sorted by the time the ballot was recorded onto a scanner. However, when looking at the results that we’ve been getting so far and trying to figure out plausible explanations for what we were seeing, he realized it might be the case that the ordering of the CVR entries are being done by both time AND USB stick grouping (which is usually associated with a specific scanner or precinct) but then simply concatenating all of those results together.
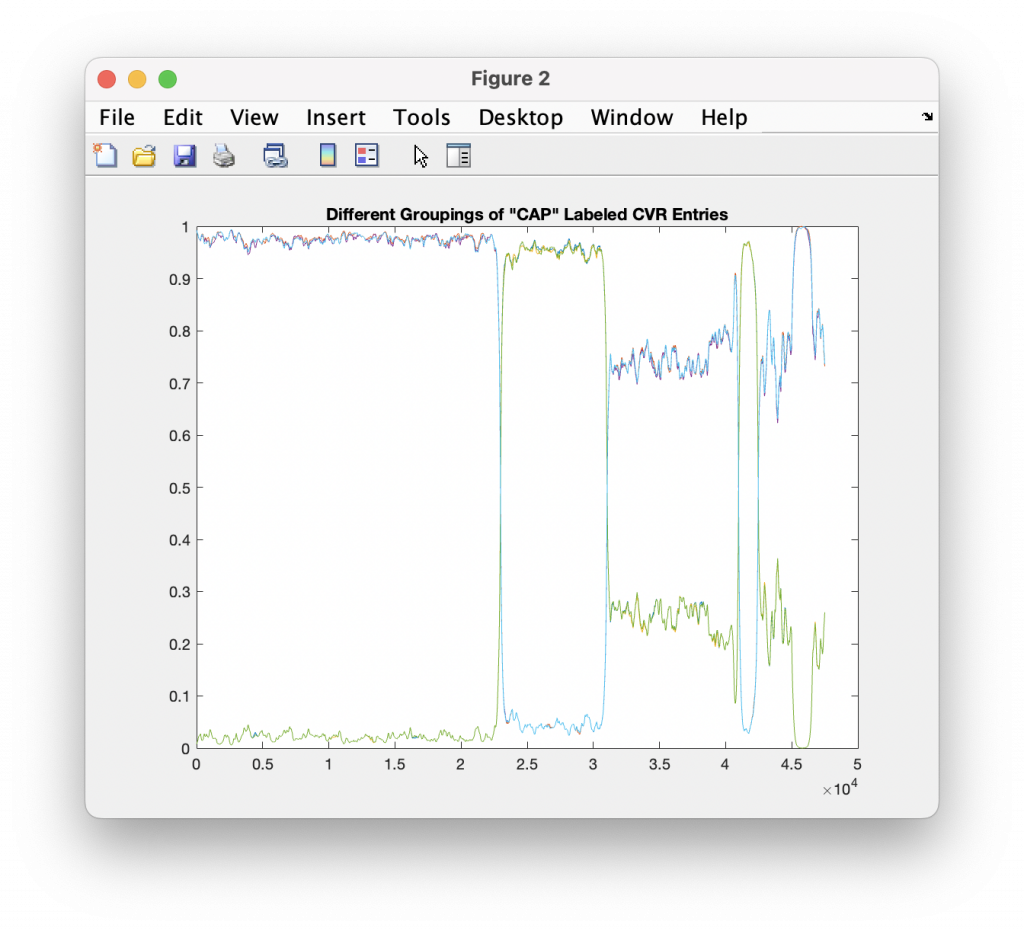
While there isn’t enough information in the Henrico CVR files to breakout the entries by USB/Scanner, and the Henrico data has record ID numbers instead of actual timestamps, there is enough information to break out them by Precinct, District and Race, with the exception of the Central Absentee Precincts (CAP) entries where we can only break them out by district given the metadata alone. However, with some careful MATLAB magic I was able to cluster the results marked as just “CAP” into at least 5 different sub-groupings that are statistically distinct. (I used an exponential moving average to discover the boundaries between groupings, and looking at the crossover points in vote share.) I then relabeled the entries with the corresponding “CAP 1”, “CAP 2”, … , “CAP 5” labels as appropriate. My previous analysis was only broken out by Race ID and CAP/Non-CAP/Provisional category.
Processing in this manner makes the individual distributions look much cleaner, so I think this does confirm that there is not a true sequential ordering in the CVR files coming out of the vendor software packages. (If they would just give us the dang timestamps … this would be a lot easier!)
I have also added a bit more rigor to the statistics outlier detection by adding plots of the length of observed runs (e.g. how many “heads” did we get in a row?) as we move through the entries, as well as the plot of the probability of this number of consecutive tosses occurring. We compute this probability for K consecutive draws using the rules of statistical independence, which is P([a,a,a,a]) = P(a) x P(a) x P(a) x P(a) = P(a)^4. Therefore the probability of getting 4 “heads” in a row with a hypothetical 53/47 weighted coin would be .53^4 = 0.0789. There are also plotted lines for a probability 1/#Ballots for reference.
Results
The good news is that this method of slicing the data and assuming that the Vendor is simply concatenating USB drives seems to produce much tighter results that look to obey the expected IID distributions. Breaking up the data this way resulted in no plot breaking the +/- 3/sqrt(N-1) boundaries, but there still are a few interesting datapoints that we can observe.
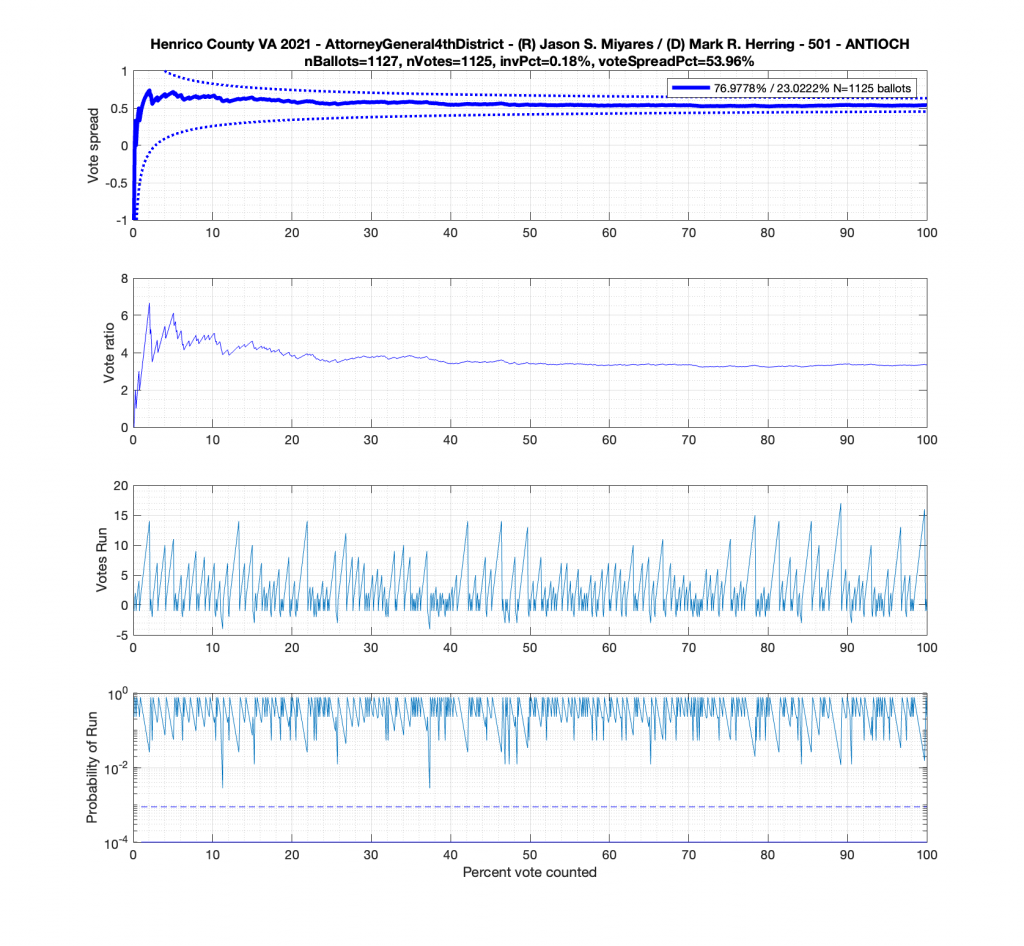
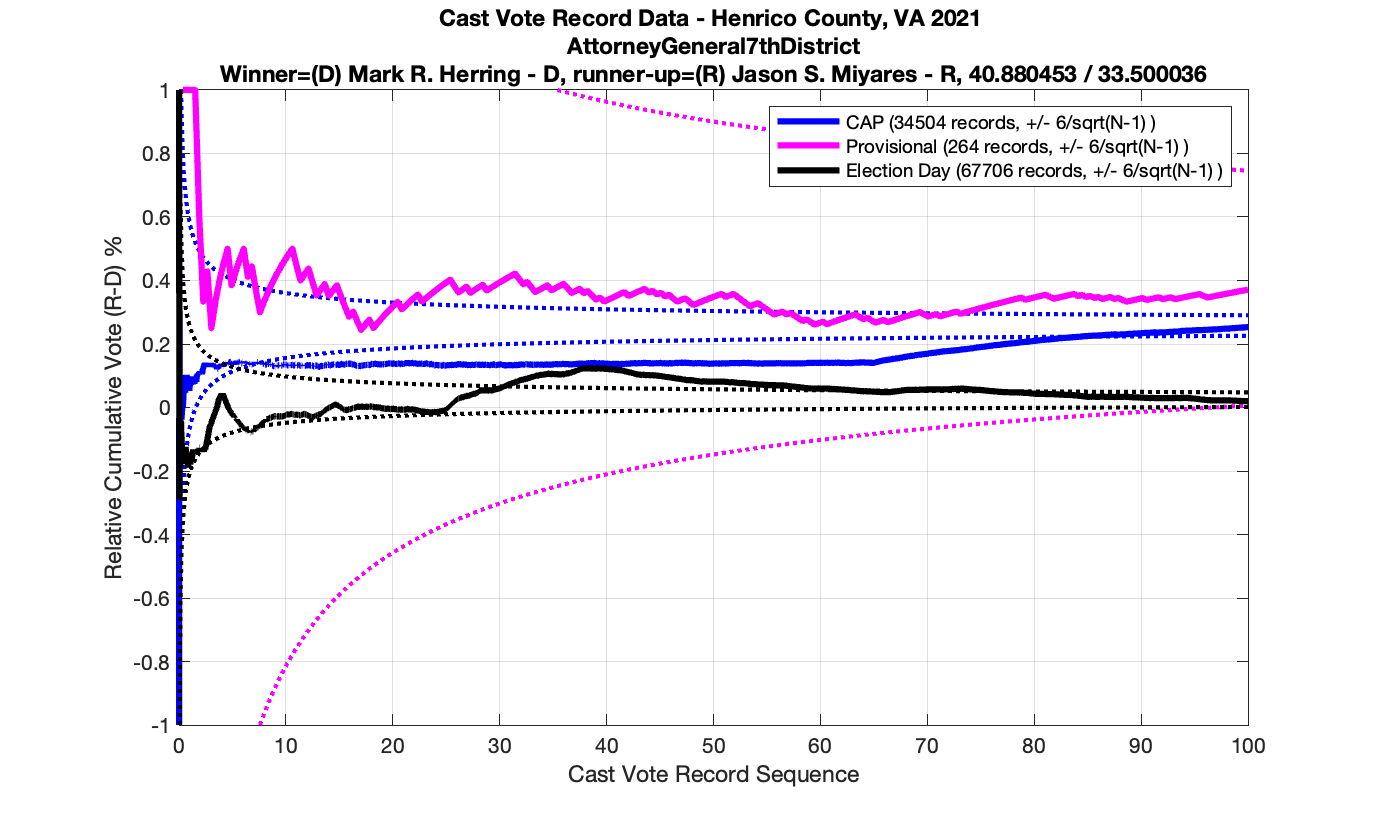
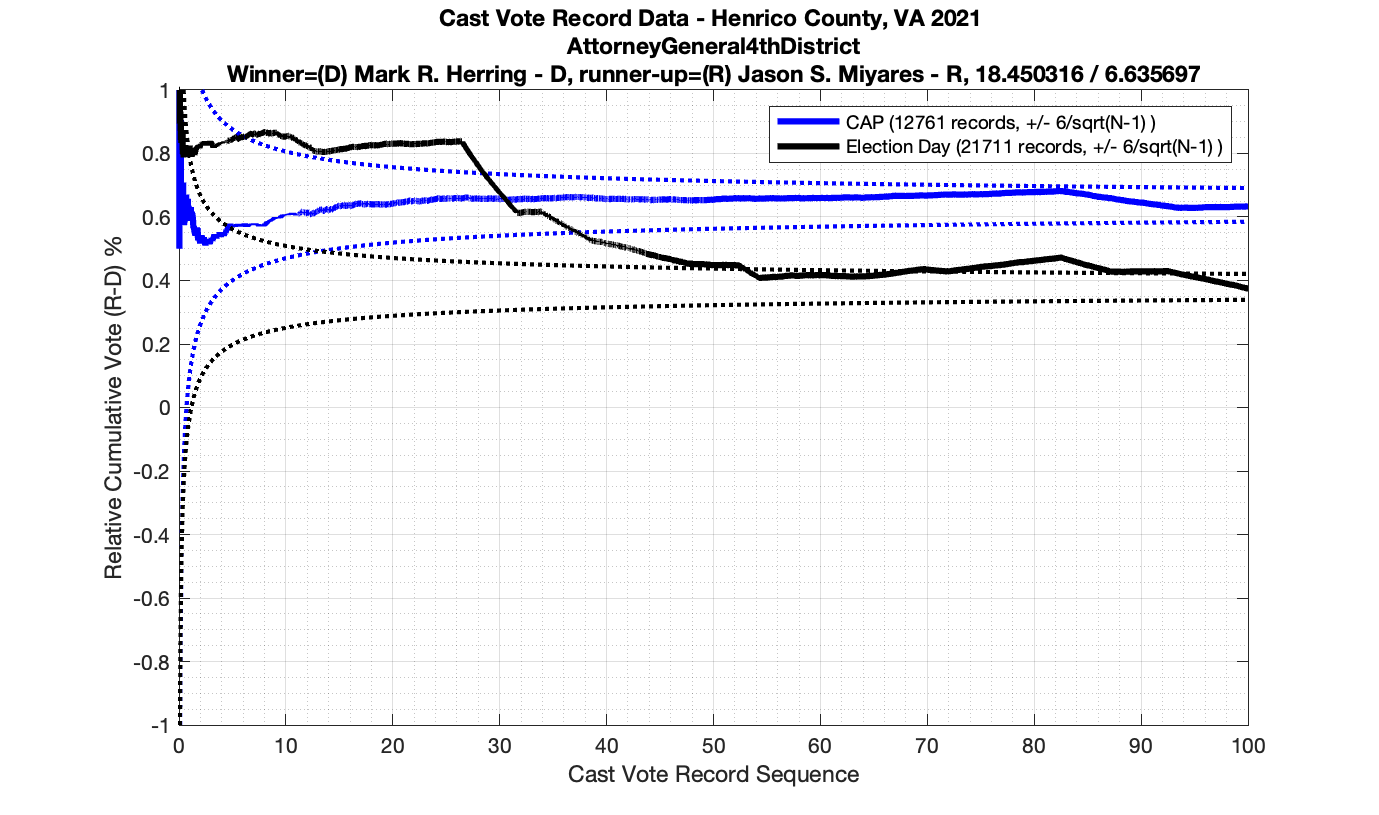
In the plot below we have the Attorney Generals race in the 4th district from precinct 501 – Antioch. This is a district that Miyares won handily 77%/23%. We see that the top plot of the cumulative spread is nicely bounded by the +/- 3/sqrt(N-1) lines. The second plot from the top gives the vote ratio in order to compare with the work that Draza Smith, Jeff O’Donnell and others are doing with CVR’s over at Ordros.com. The second from bottom plot gives the number k of consecutive ballots (in either candidates favor) that have been seen at each moment in the counting process. And the bottom plot raises either the 77% or 23% overall probability to the k-th power to determine the probability associated with pulling that many consecutive Miyares or Herring ballots from an IID distribution. The most consecutive ballots Miyares received in a row was just over 15, which had a .77^15 = 0.0198 or 1.98% chance of occurring. The most consecutive ballots Herring received was about 4, which equates to a probability of occurrence of .23^4 = 0.0028 or 0.28% chance. The dotted line on the bottom plot is referenced at 1/N, and the solid line is referenced at 0.01%.
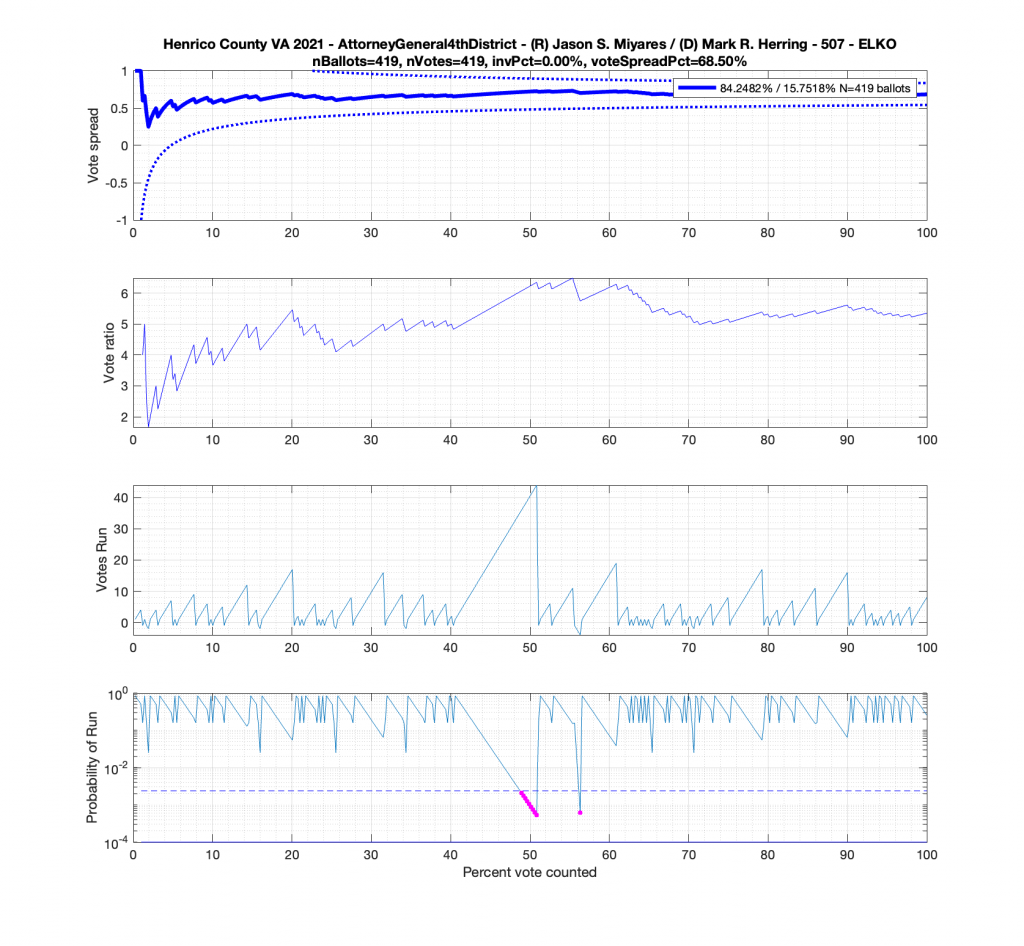
But let’s now take a look at another plot for the Miyares contest in another blowout locality with 84% / 16% for Miyares. The +/- 3/sqrt(N-1) limit nicely bounds our ballot distribution again. There is, however, an interesting block of 44 consecutive ballots for Miyares about halfway through the processing of ballots. This equates to .84^44 = 0.0004659 or a 0.04659% chance of occurrence from an IID distribution. Close to this peak is a run of 4 ballots for Herring which doesn’t sound like much, but given the 84% / 16% split, the probability of occurrence for that small run is .16^4 = 0.0006554 or 0.06554%!
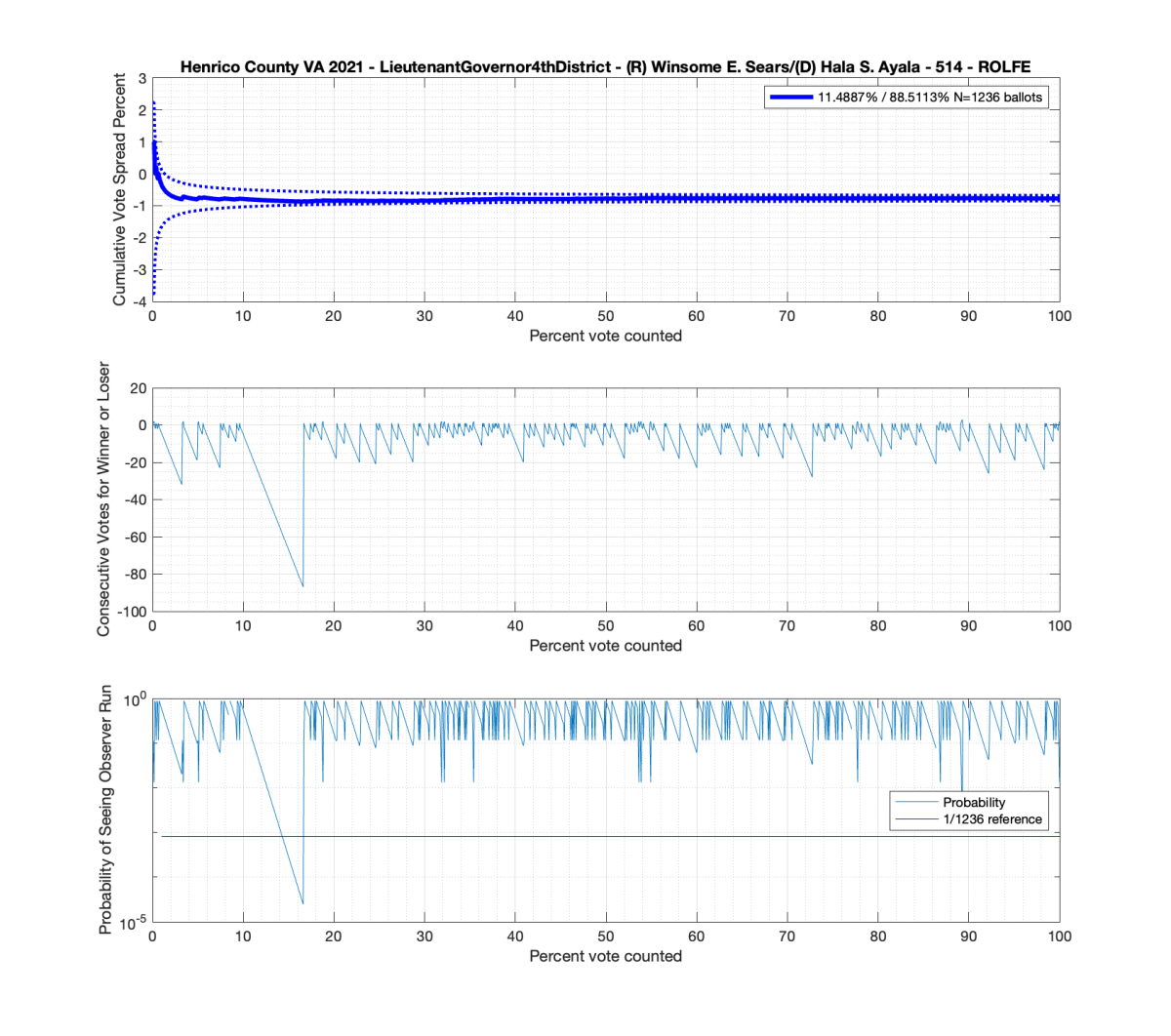
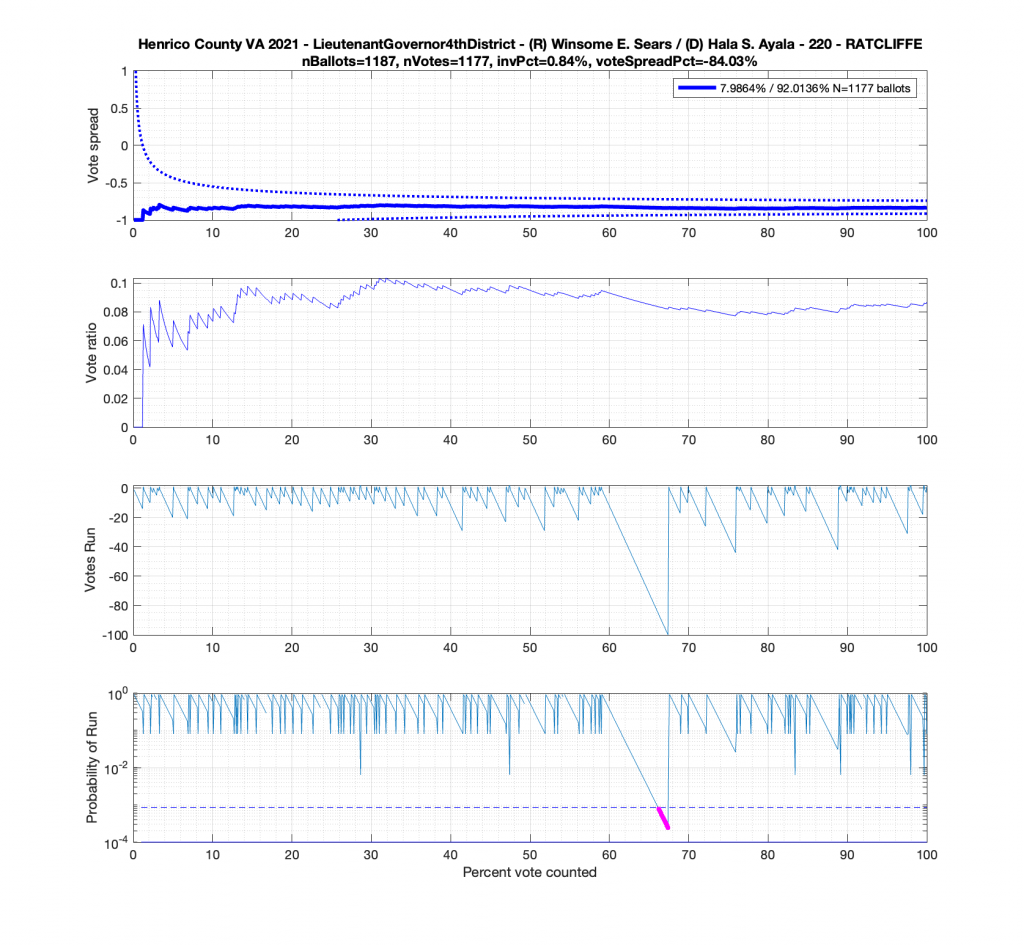
Moving to the Lt. Governors race we see an interesting phenomenon where where Ayala received a sudden 100 consecutive votes a little over midway through the counting process. Now granted, this was a landslide district for Ayala, but this still equates to a .92^100 = 0.000239 or 0.0239% chance of occurrence.
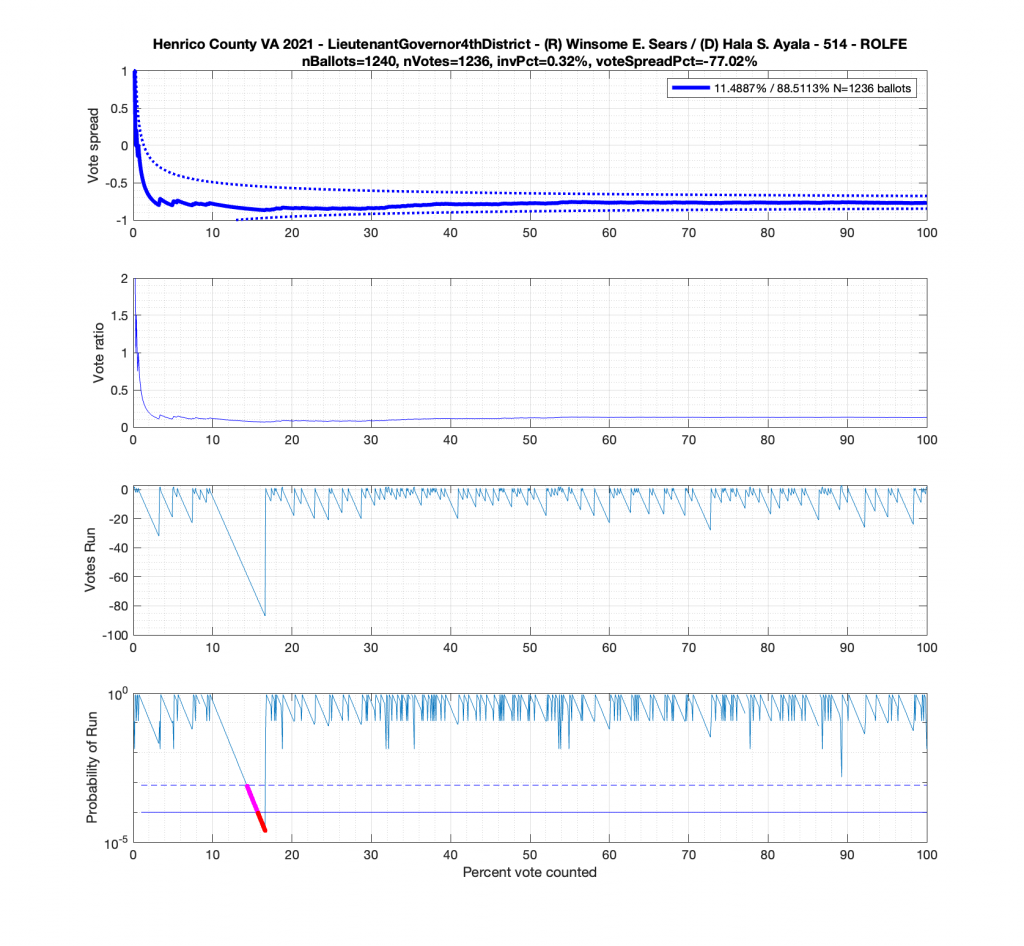
And here’s another large block of contiguous Ayala ballots equating to about .89^84 = 0.00005607 or 0.0056% chance of occurrence.
Tests for Differential Invalidation (added 2022-09-19):
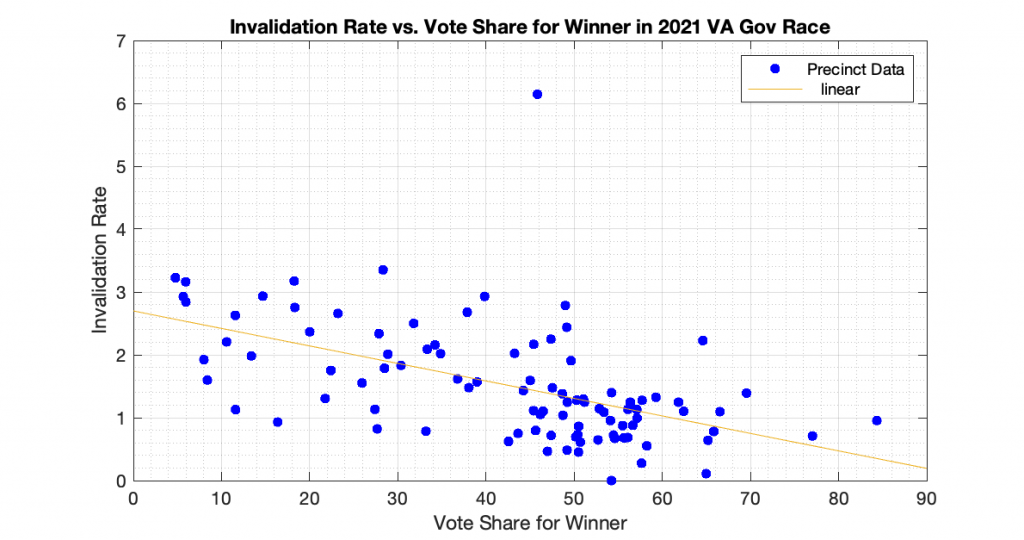
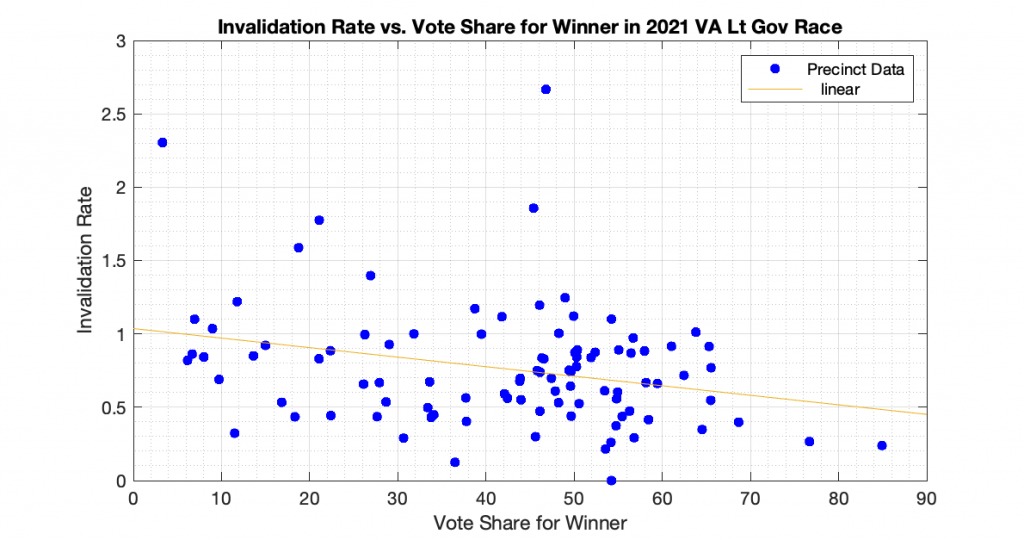
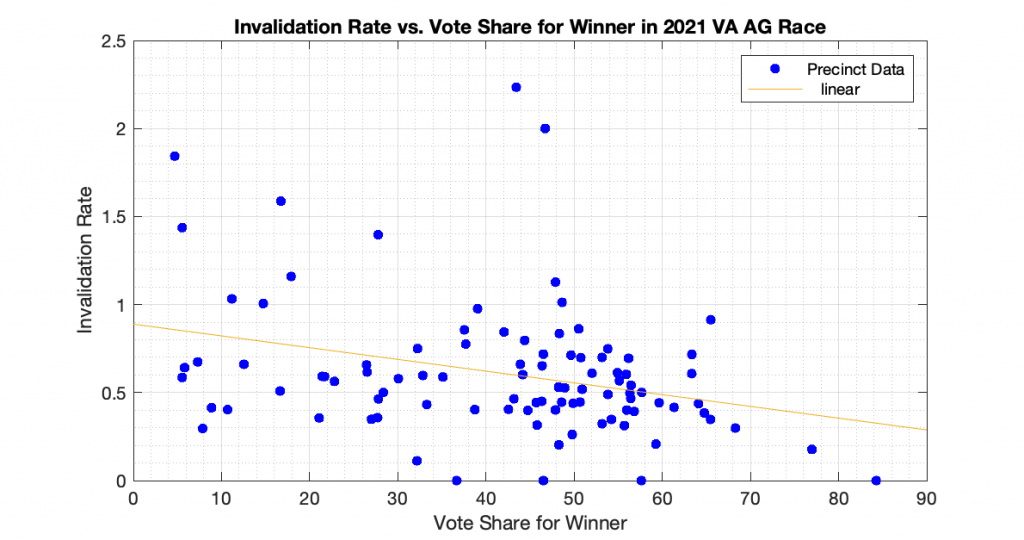
“Differential invalidation” takes place when the ballots of one candidate or position are invalidated at a higher rate than for other candidates or positions. With this dataset we know how many ballots were cast, and how many ballots had incomplete or invalid results (no recorded vote in the cvr, but the ballot record exists) for the 3 statewide races. In accordance with the techniques presented in [1] and [2], I computed the plots of the Invalidation Rate vs the Percent Vote Share for the Winner in an attempt to observe if there looks to be any evidence of Differential Invalidation ([1], ch 6). This is similar to the techniques presented in [2], which I used previously to produce my election fingerprint plots and analysis that plotted the 2D histograms of the vote share for the winner vs the turnout percentage.
The generated the invalidation rate plots for the Gov, Lt Gov and AG races statewide in VA 2021 are below. Each plot below is representing one of the statewide races, and each dot is representing the ballots from a specific precinct. The x axis is the percent vote share for the winner, and the y axis is computed as 100 – 100 * Nvotes / Nballots. All three show a small but statistically significant linear trend and evidence of differential invalidation. The linear regression trendlines have been computed and superimposed on the data points in each graph.
To echo the warning from [1]: a differential invalidation rate does not directly indicate any sort of fraud. It indicates an unfairness or inequality in the rate of incomplete or invalid ballots conditioned on candidate choice. While it could be caused by fraud, it could also be caused by confusing ballot layout, or socio-economic issues, etc.
[1] Forsberg, O.J. (2020). Understanding Elections through Statistics: Polling, Prediction, and Testing (1st ed.). Chapman and Hall/CRC. https://doi.org/10.1201/9781003019695
[2] Klimek, Peter & Yegorov, Yuri & Hanel, Rudolf & Thurner, Stefan. (2012). Statistical Detection of Systematic Election Irregularities. Proceedings of the National Academy of Sciences of the United States of America. 109. 16469-73. https://doi.org/10.1073/pnas.1210722109.
Update 2022-08-29 per observations by members of the Texas team I am working with, we’ve been able to figure out that (a) the vendor was simply concatenating data records from each machine and not sorting the CVR results and (b) how to mostly unwrap this affect on the data to produce much cleaner results. The results below are left up for historical reference.
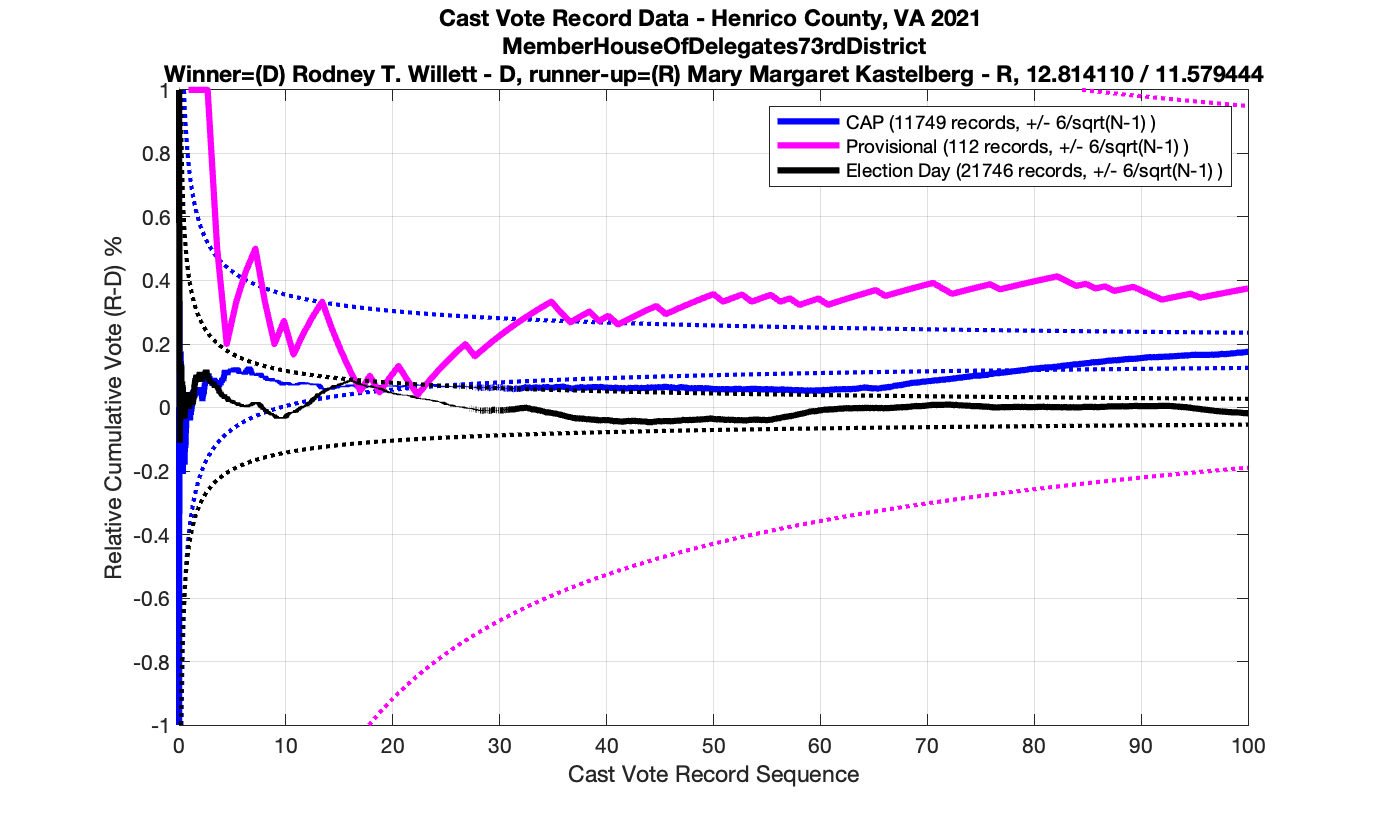
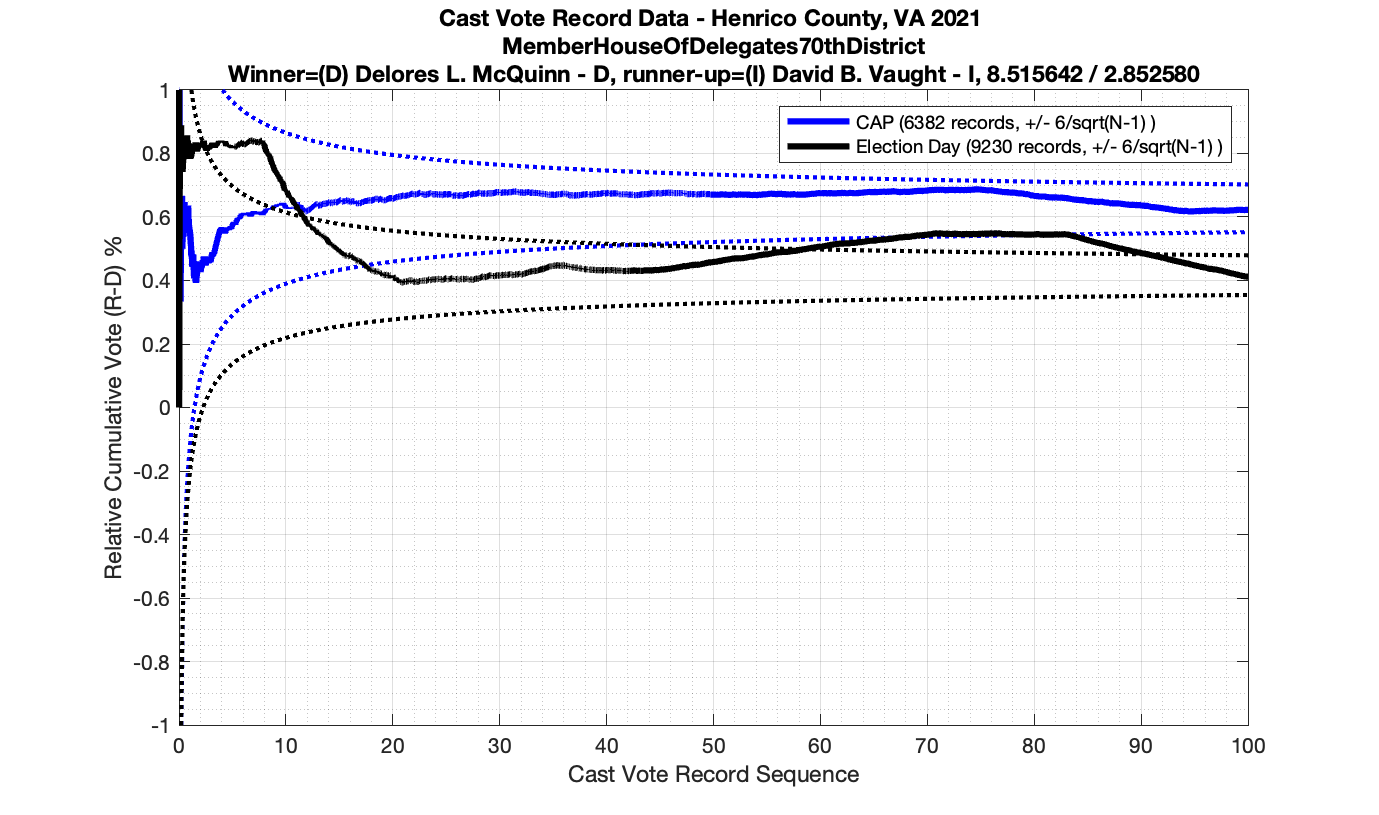
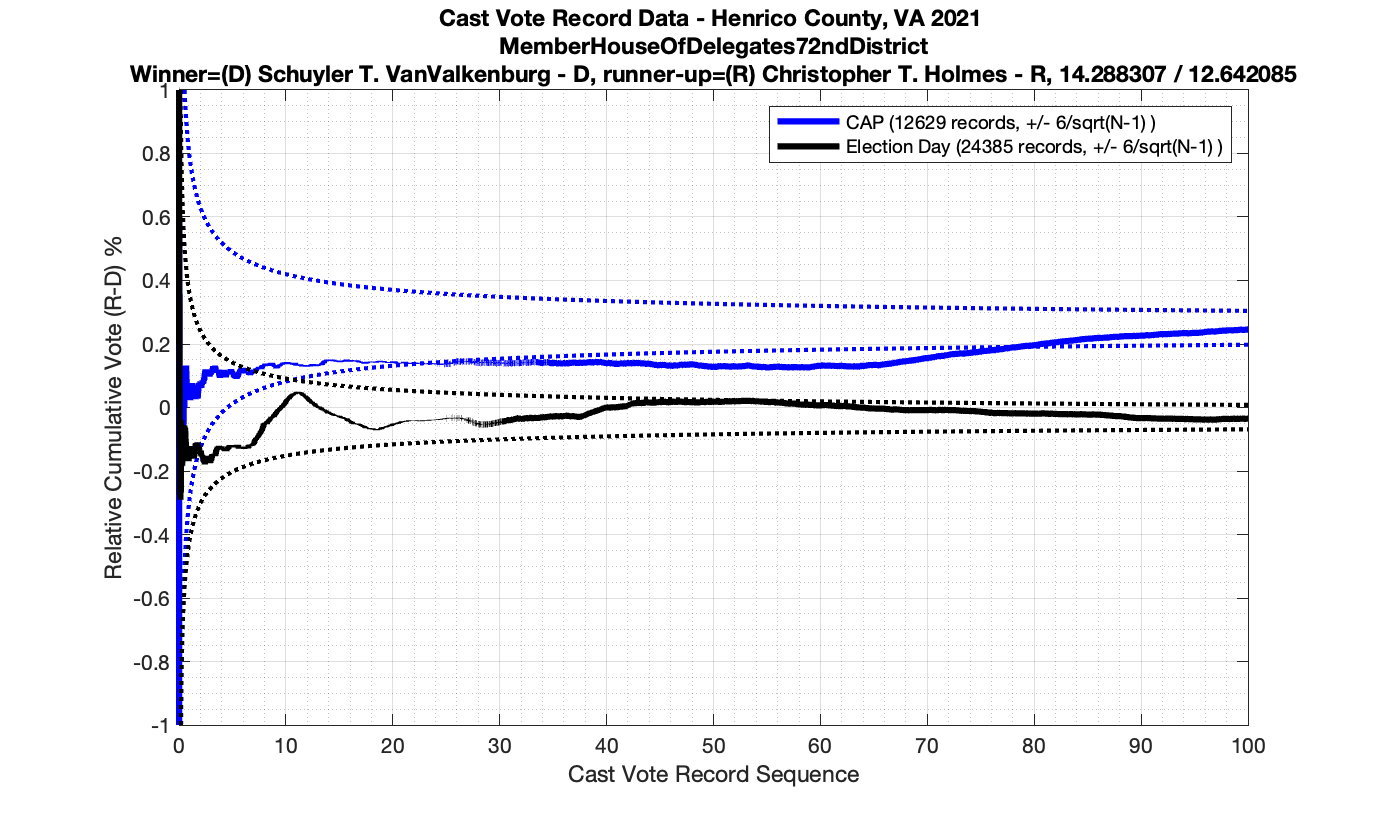
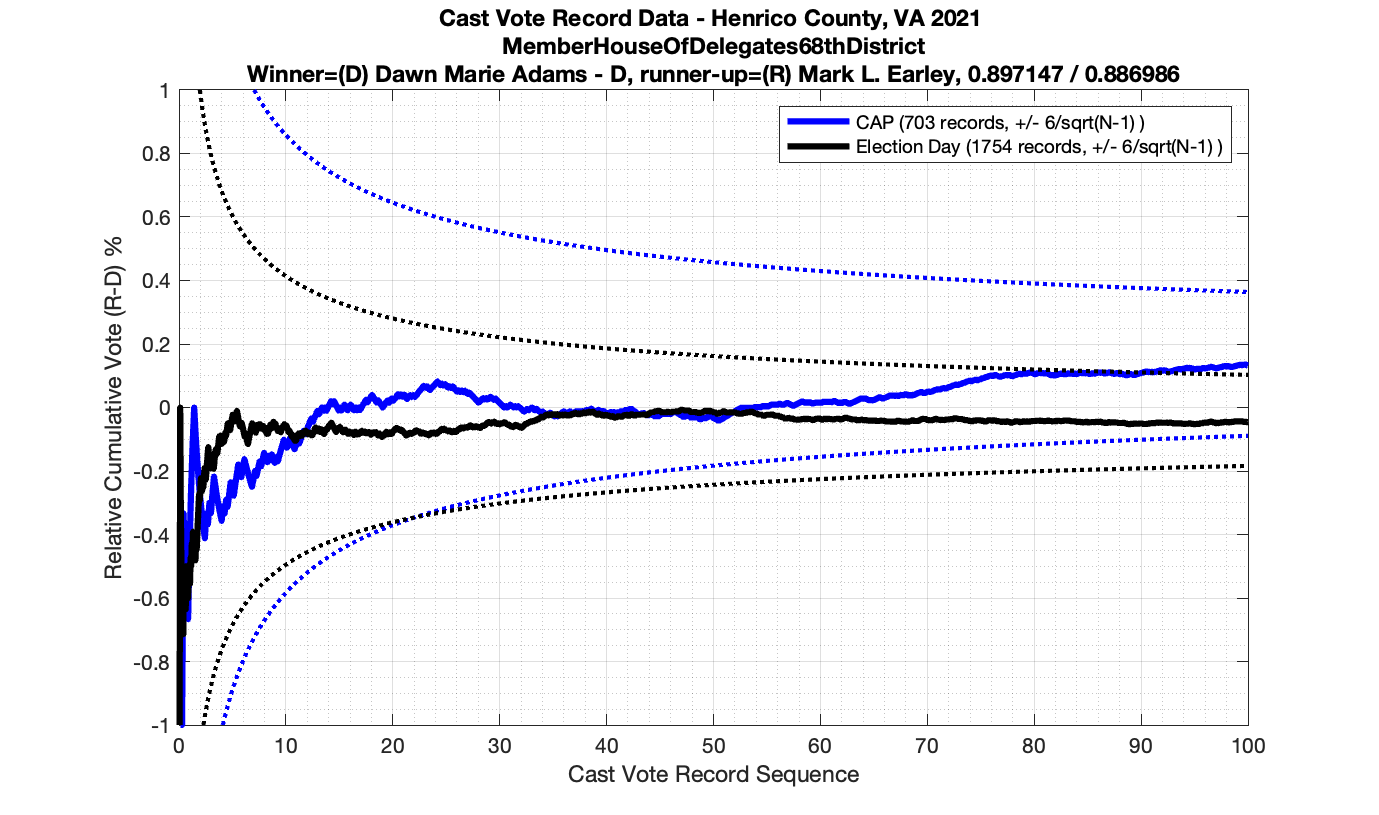
For background information, please see my introduction to Cast Vote Records processing and theory here: Statistical Detection of Irregularities via Cast Vote Records. This entry will be specifically documenting the results from processing the Henrico County Virginia CVR data from the 2021 election.
As in the results from the previous post, I expanded the theoretical error bounds out to 6/sqrt(N) instead of 3/sqrt(N) in order to give a little bit of extra “wiggle room” for small fluctuations.
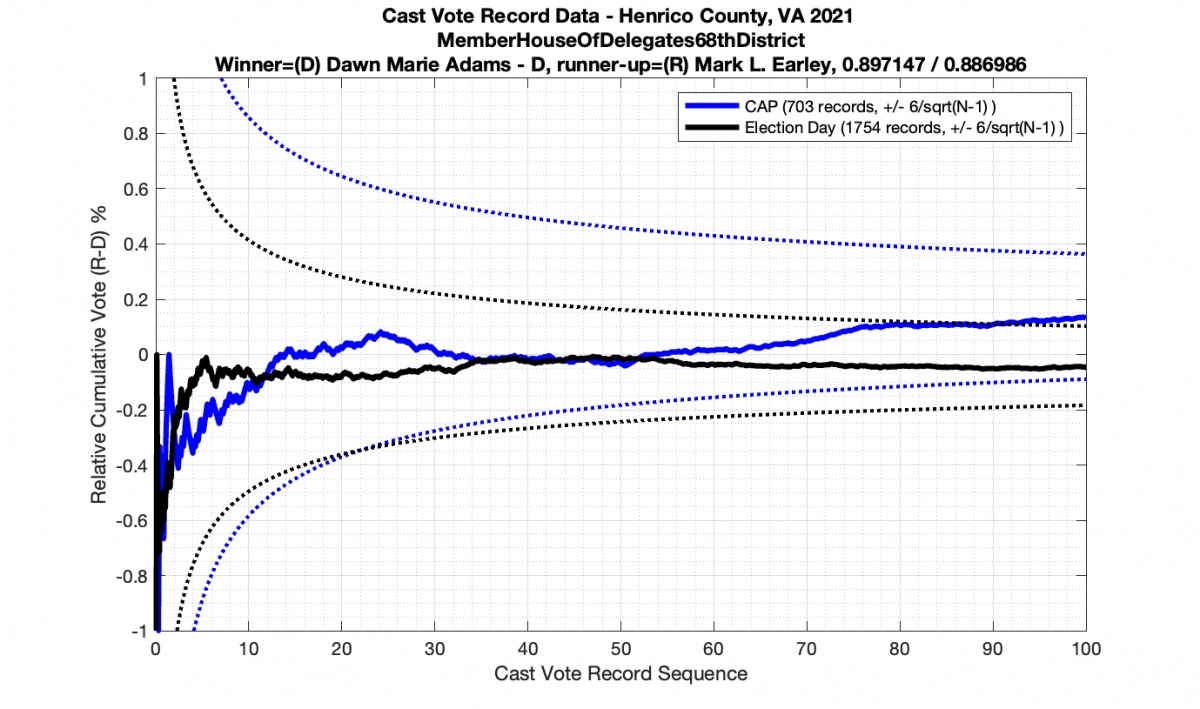
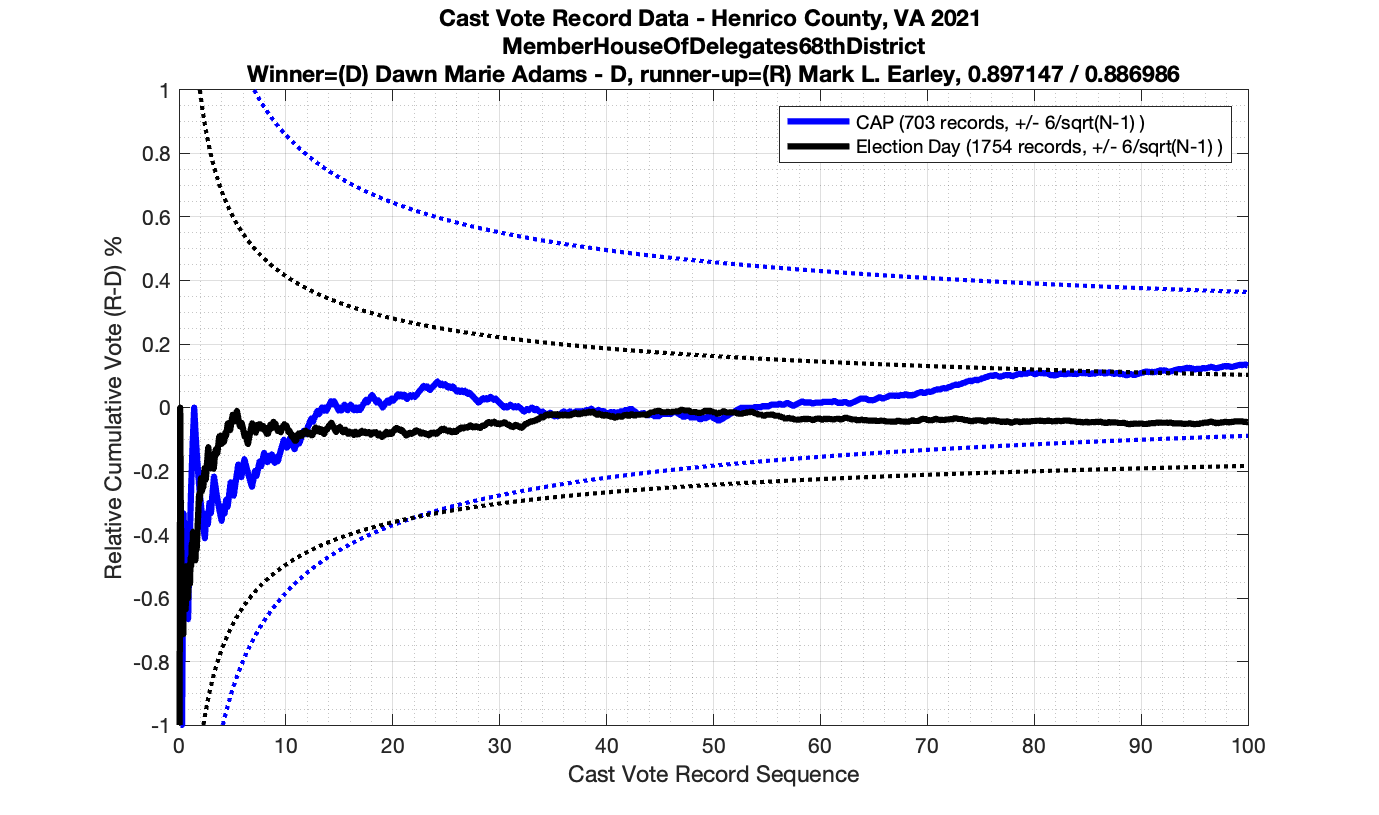
However the Henrico dataset could only be broken up by CAP, Non-CAP or Provisional. So be aware that the CAP curves presented below contain a combination of both early-vote and mail-in ballots.
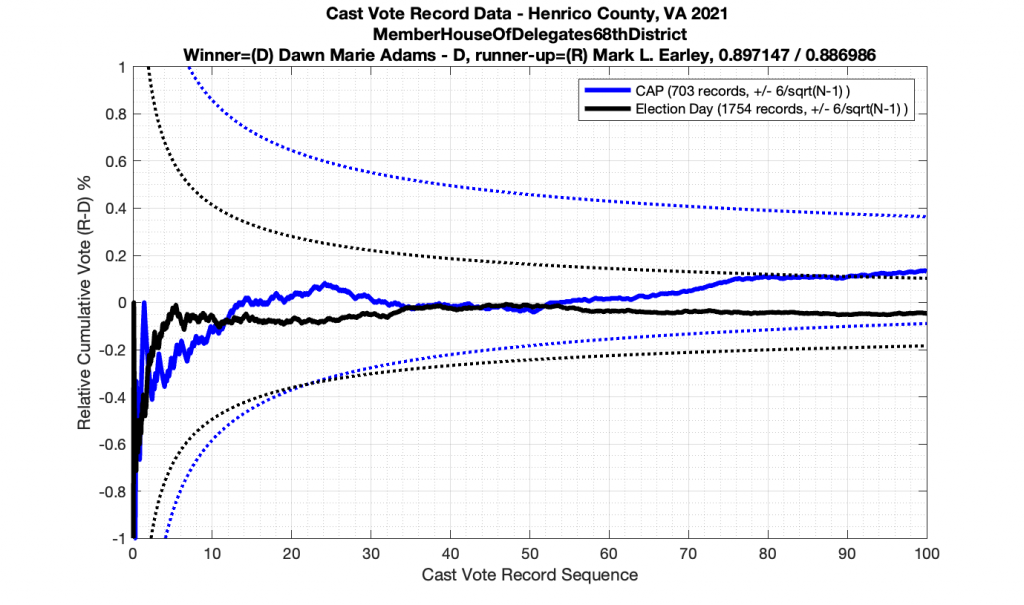
The good news is that I’ve at least found one race that seems to not have any issues with the CVR curves staying inside the error boundaries. MemberHouseOfDelegates68thDistrict did not have any parts of the curves that broke through the error boundaries.
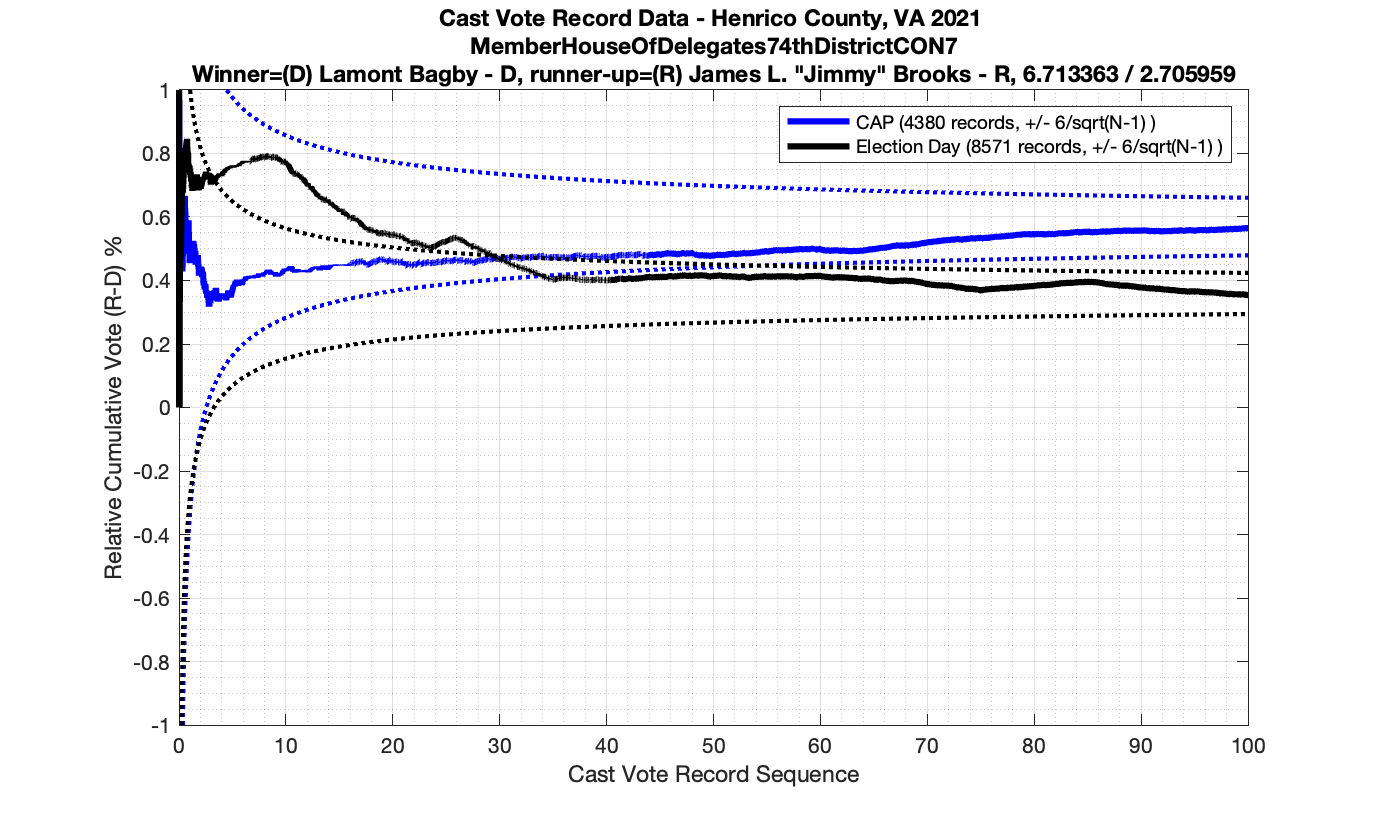
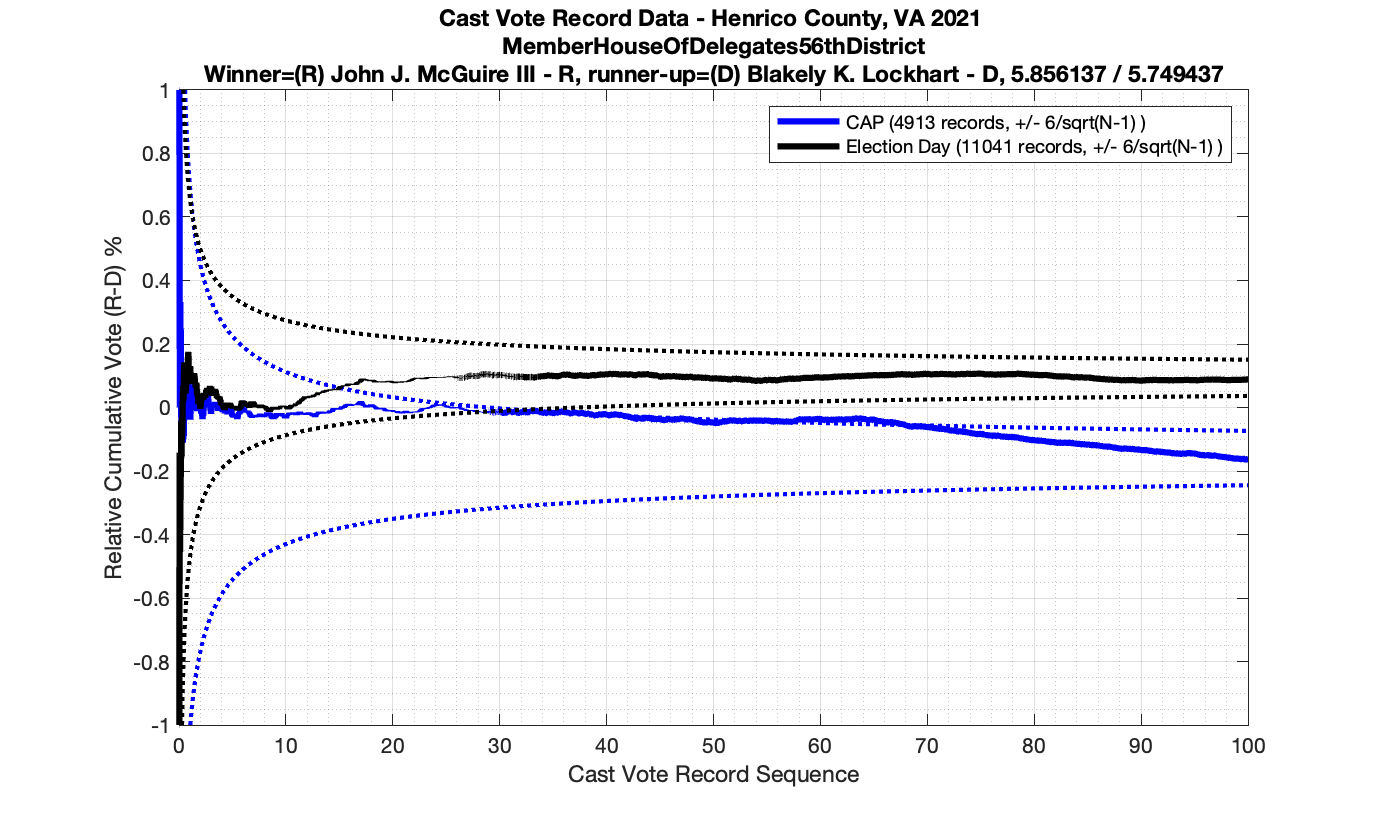
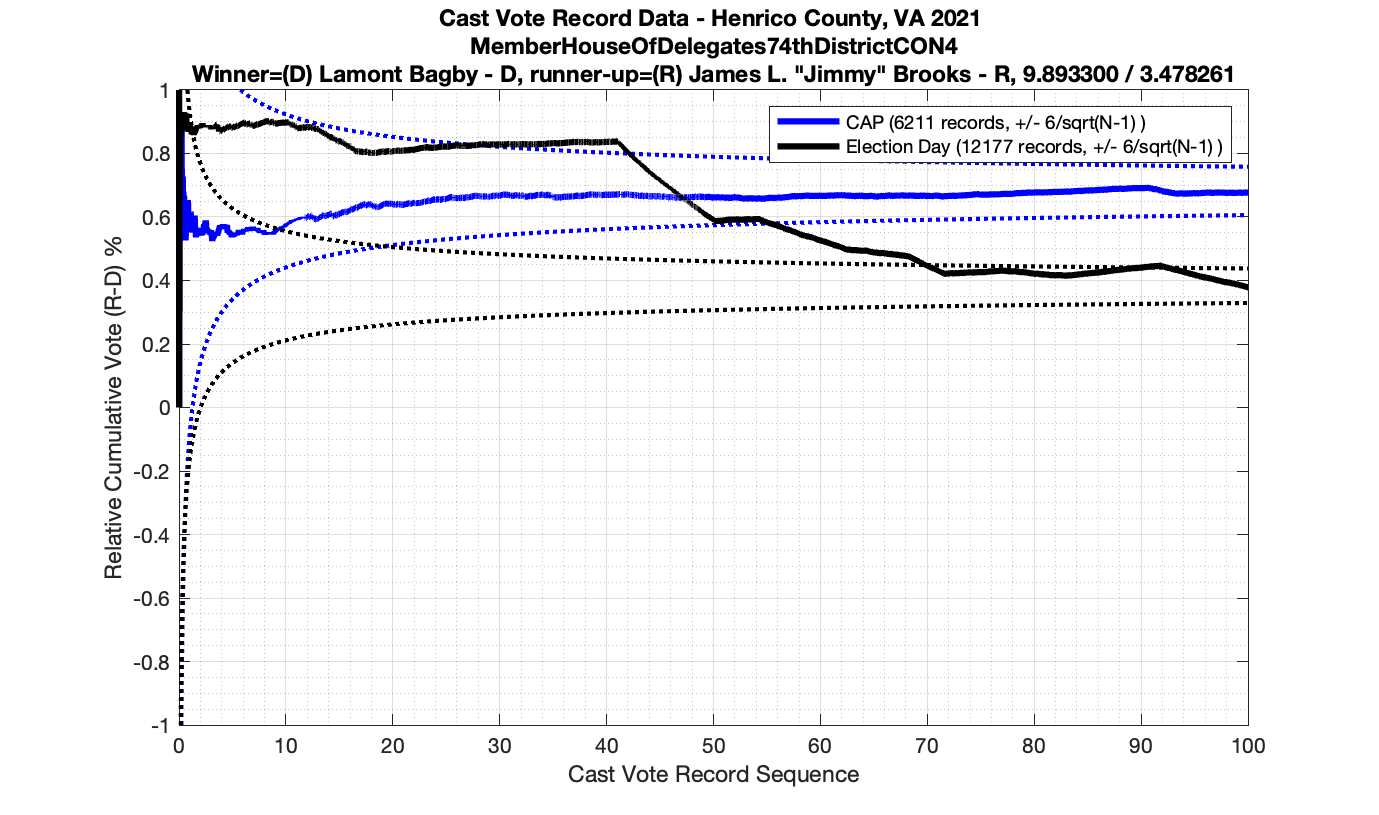
The bad news … is pretty much everything else doesn’t. I cannot tell you why these curves have such differences from statistical expectation, just that they do. We must have further investigation and analysis of these races to determine root cause. I’ve presented all of the races that had sufficient number of ballots below (1000 minimum for the race a whole, and 100 ballot minimum for each ballot type).
There has been a good amount of commotion regarding cast vote records (CVRs) and their importance lately. I wanted to take a minute and try and help explain why these records are so important, and how they provide a tool for statistical inspection of election data. I also want to try and dispel any misconceptions as to what they can or can’t tell us.
I have been working with other local Virginians to try and get access to complete CVRs for about 6 months (at least) in order to do this type of analysis. However, we had not had much luck in obtaining real data (although we did get a partial set from PWC primaries but it lacked the time-sequencing information) to evaluate until after Jeff O’Donnell (a.k.a. the Lone Raccoon) and Walter Dougherity did a fantastic presentation at the Mike Lindell Moment of Truth Summit on CVRs and their statistical use. That presentation seems to have broken the data logjam, and was the impetus for writing this post.
Just like the Election Fingerprint analysis I was doing earlier that highlighted statistical anomalies in election data, this CVR analysis is a statistics based technique that can help inform us as to whether or not the election data appears consistent with expectations. It only uses the official results as provided by state or local election authorities and relies on standard statistical principles and properties. Nothing more. Nothing less.
What is a cast vote record?
A cast vote record is part of the official election records that need to be maintained in order for election systems to be auditable. (see: 52 USC 21081 , NIST CVR Standard, as well as the Virginia Voting Systems Certification Standards) They can have many different formats depending on equipment vendor, but they are effectively a record of each ballot as it was recorded by the equipment. Each row in a CVR data table should represent a single ballot being cast by a voter and contain, at minimum, the time (or sequence number) when the ballot was cast, the ballot type, and the result of each race. Other data might also be included such as which precinct and machine performed the scanning/recording of the ballot, etc. Note that “cast vote records” are sometimes also called “cast voter records”, “ballot reports” or a number of other different names depending on the publication or locality. I will continue to use the “cast vote record” language in this document for consistency.
Why should we care?
The reason these records are so important, is based on statistics and … unfortunately … involves some math to fully describe. But to make this easier, let’s try first to walk through a simple thought experiment. Let’s pretend that we have a weighted, or “trick” coin, that when flipped it will land heads 53% of the time and land tails 47% of the time. We’re going to continuously flip this coin thousands of times in a row and record our results. While we can’t predict exactly which way the coin will land on any given toss, we can expect that, on average, the coin will land with the aforementioned 53/47 split.
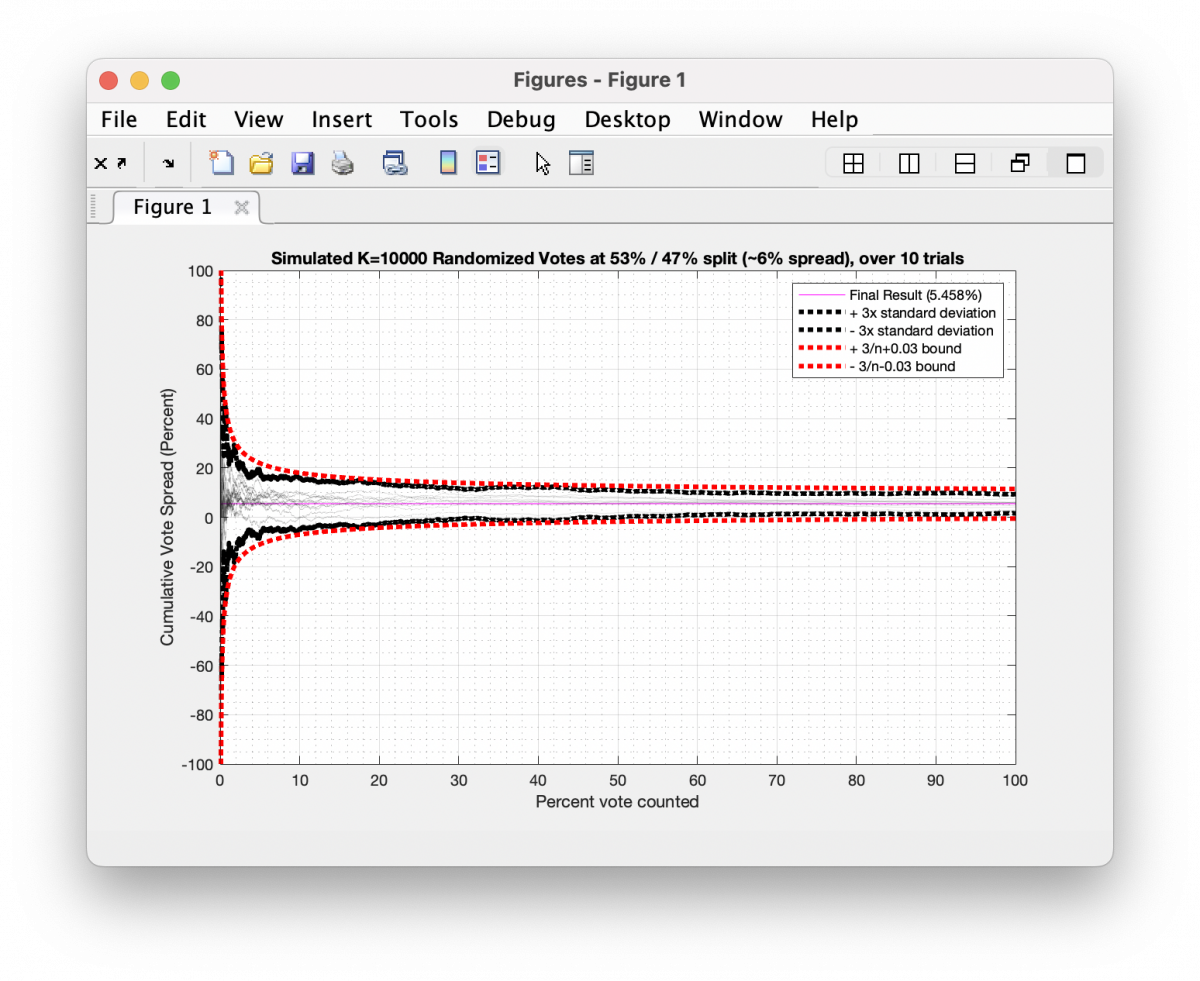
Now because each coin toss constitutes an independent and identically distributed (IID) probability function, we can expect this sequence to obey certain properties. If as we are making our tosses, we are computing the “real-time” statistics of the percentage of head/tails results, and more specifically if we plot the spread (or difference) of those percentage results as we proceed we will see that the spread has very large swings as we first begin to toss our coin, but very quickly the variability in the spread becomes stable as more and more tosses (data) are available for us to average over. Mathematically, the boundary on these swings is inversely proportional to the square root of how many tosses are performed. In the “Moment of Truth” video on CVRs linked above, Jeff and Walter refer to this as a “Cone of Probability”, and he generates his boundary curves experimentally. He is correct. It is a cone of probability as its really just a manifestation of well-known and well-understood Poisson Noise characteristic (for the math nerds reading this). In Jeff’s work he uses the ratio of votes between candidates, while I’m using the spread (or deviation) of the vote percentages. Both metrics are valid, but using the deviation has an easy closed-form boundary curve that we don’t need to generate experimentally.
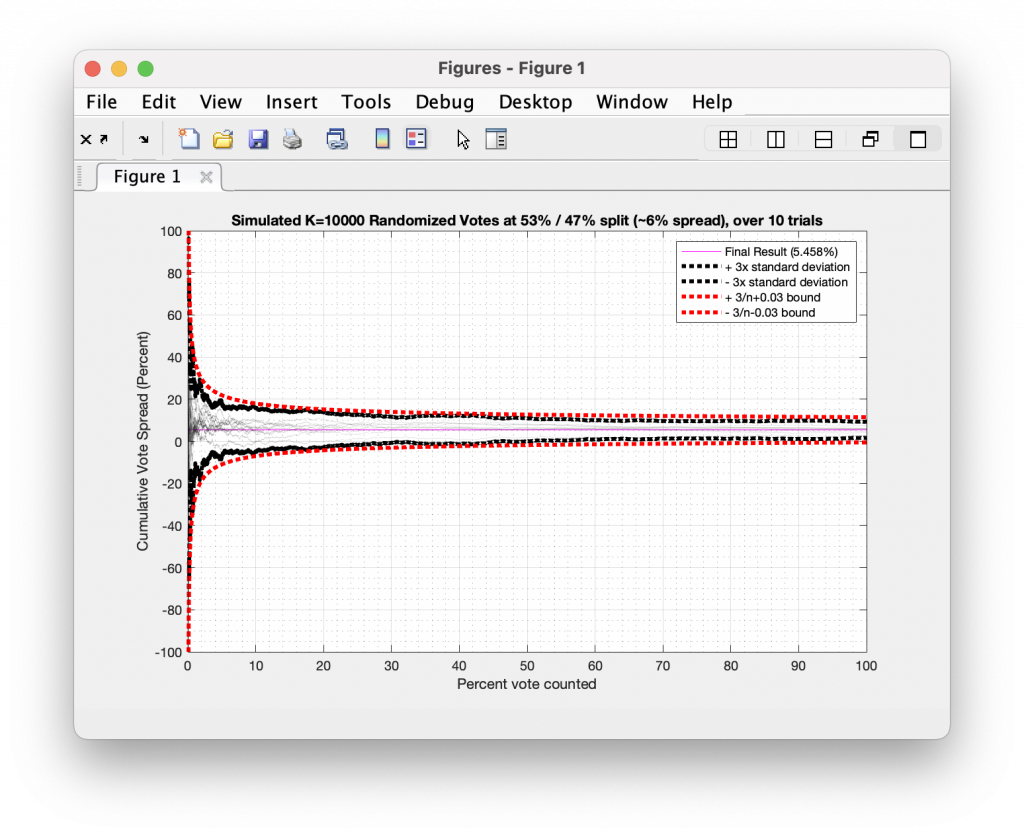
In the graphic below I have simulated 10 different trials of 10,000 tosses for a distribution that leans 53/47, which is equivalent to a 6% spread overall. Each trial had 10,000 random samples generated as either +1 or -1 values (a.k.a. a binary “Yes” or “No” vote) approximating the 53/47 split and I plotted the cumulative running spread of the results as each toss gets accumulated. The black dotted outline is the 95% confidence interval (or +/-3x the standard deviation) across the 10 trials for the Nth bin, and the red dotted outline is the 3/sqrt(n-1) analytical boundary.
So how does this apply to election data?
In a theoretically free and perfectly fair election we should see similar statistical behavior, where each coin toss is replaced with a ballot from an individual voter. In a perfect world we would have each vote be completely independent of every other vote in the sequence. In reality we have to deal with the fact that there can be small local regions of time in which perfectly legitimate correlations in the sequence of scanned ballots exist. Think of a local church who’s congregation is very uniform and they all go to the polls after Sunday mass. We would see a small trend in the data corresponding to this mass of similar thinking peoples going to the polls at the same time. But we wouldn’t expect there to be large, systematic patterns, or sharp discontinuities in the plotted results. A little bit of drift and variation is to be expected in dealing with real world election data, but persistent and distinct patterns would indicate a systemic issue.
Now we cannot isolate all of the variables in a real life example, but we should try as best as possible. To that effect, we should not mix different ballot types that are cast in different manners. We should keep our analysis focused within each sub-group of ballot type (mail-in, early-vote, day-of, etc). It is to the benefit of this analysis that the very nature of voting, and the procedures by which it occurs, is a very randomized process. Each sub-grouping has its own quasi-random process that we can consider.
While small groups (families, church groups) might travel to the in-person polls in correlated clusters, we would expect there to be fairly decent randomization of who shows up to in-person polls and when. The ordering of who stands in line before or after one another, how fast they check-in and fill out their ballot, etc, are all quasi-random processes.
Mail-in ballots have their own randomization as they depend on the timing of when individuals request, fill-out and mail their responses, as well as the logistics and mechanics of the postal service processes themselves providing a level of randomization as to the sequence of ballots being recorded. Like a dealer shuffling a deck of cards, the process of casting a mail-in vote provides an additional level of independence between samples.
No method is going to supply perfect theoretical independence from ballot to ballot in the sequence, but theres a general expectation that voting should at least be similar to an IID process.
Also … and I cannot stress this enough … while these techniques can supply indications of irregularities and discrepancies in elections data, they are not conclusive and must be coupled with in-depth investigations.
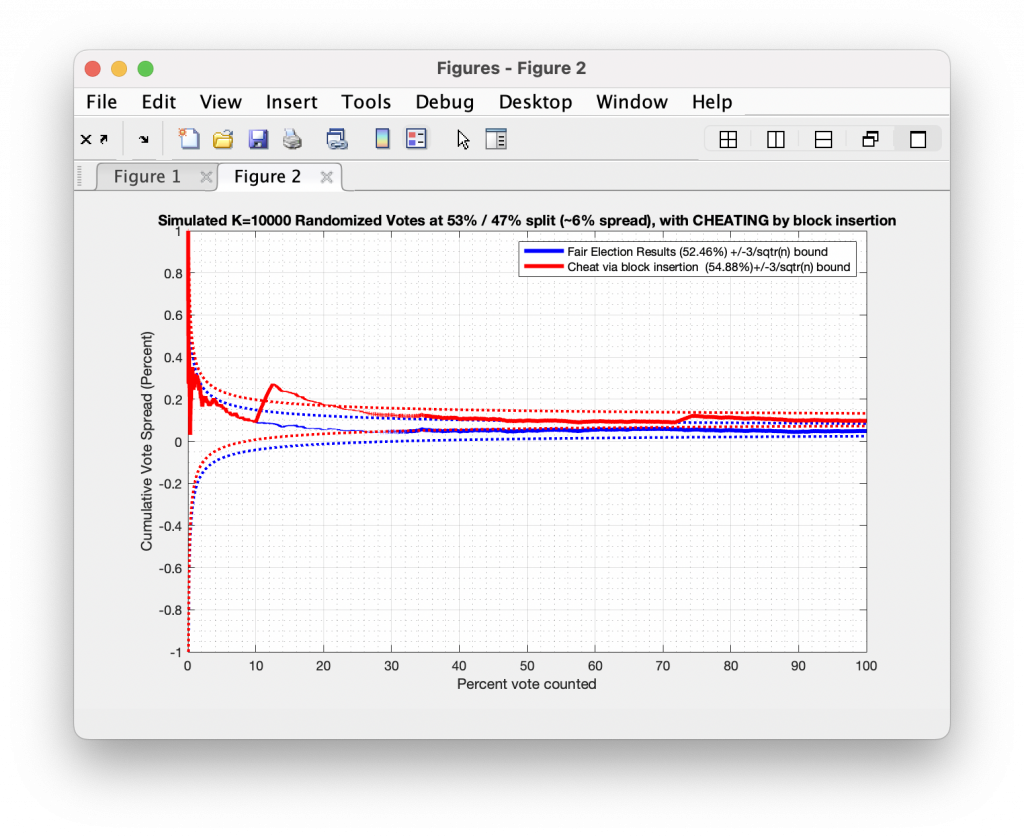
So going back to the simulation we generated above … what does a simulation look like when cheating occurs? Let’s take a very simple cheat from a random “elections” of 10,000 ballots, with votes being representative of either +1 (or “Yes”) or -1 (or “No”) as we did above. But lets also cheat by randomly selecting two different spots in the data stream to place blocks of 250 consecutive “Yes” results.
The image below shows the result of this process. The blue curve represents the true result, while the red curve represents the cheat. We see that at about 15% and 75% of the vote counted, our algorithm injected a block of “Yes” results, and the resulting cumulative curve breaks through the 3/sqrt(N-1) boundary. Now, not every instance or type of cheat will break through this boundary, and there may be real events that might explain such behavior. But looking for CVR curves that break our statistical expectations is a good way to flag items that need further investigation.
Computing the probability of a ballot run:
Section added on 2022-09-18
We can also a bit more rigor to the statistics outlier detection by computing the probability of the length of observed runs (e.g. how many “heads” did we get in a row?) occurring as we move through the sequential entries. We can compute this probability for K consecutive draws using the rules of statistical independence, which is P([a,a,a,a]) = P(a) x P(a) x P(a) x P(a) = P(a)^4. Therefore the probability of getting 4 “heads” in a row with a hypothetical 53/47 weighted coin would be .53^4 = 0.0789.
Starting with my updated analysis of 2021 Henrico County VA, I’ve started adding this computation to my plots. I have not yet re-run the Texas data below with this new addition, but will do so soon and update this page accordingly.
Real Examples
UPDATE 2022-09-18:
I have finally gotten my hands on some data for 2020 in VA. I will be working to analyze that data and will report what I find as soon as I can, but as we are approaching the start of early voting for 2022, my hands are pretty full at the moment so it might take me some time to complete that processing.
As noted in my updates to the Henrico County 2021 VA data, and in my section on computing the probability of given runs above, the Texas team noticed that we could further break apart the Travis county data into subgroups by USB stick. I will update my results below as soon as I get the time to do so.
So I haven’t gotten complete cast vote records from VA yet (… which is a whole other set of issues …), but I have gotten my Cheeto stained fingers on some data from the Travis County Texas 2020 race.
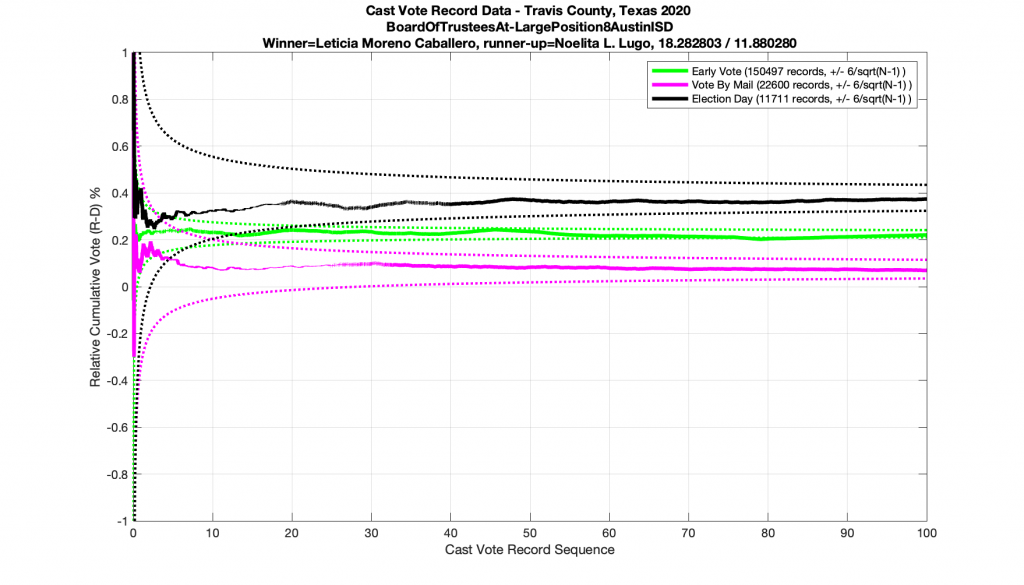
So let us first take a look at an example of a real race where everything seems to be obeying the rules as set out above. I’ve doubled my error bars from 3x to 6x of the inverse square standard (discussed above) in order to handle the quasi-IID nature of the data and give some extra margin for small fluctuating correlations.
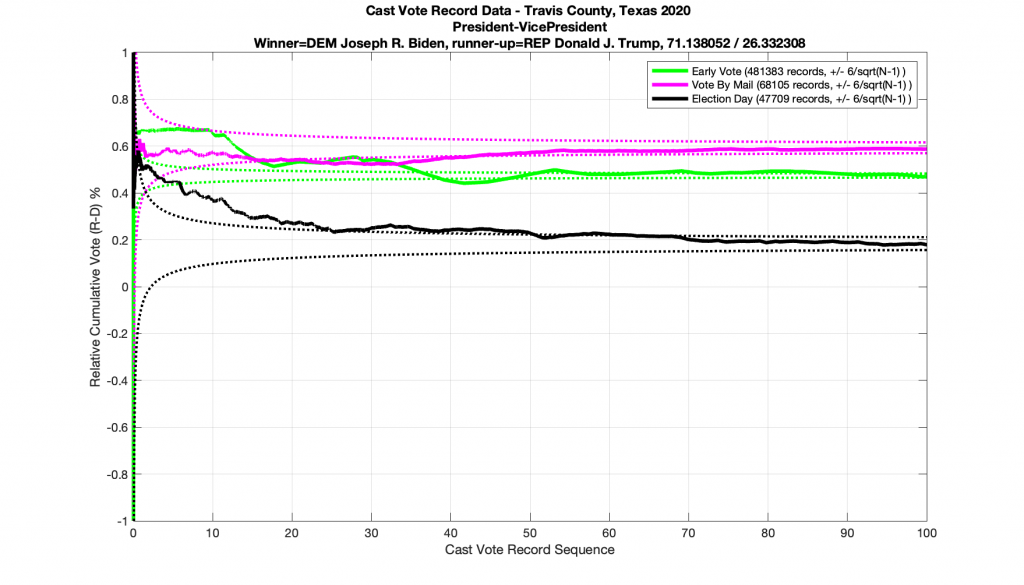
The plot below shows the Travis County Texas 2020 BoardOfTrusteesAt_LargePosition8AustinISD race, as processed by the tabulation system and stratified by ballot type. We can see that all three ballot types start off with large variances in the computed result but very quickly coalesce and approach their final values. This is exactly what we would expect to see.
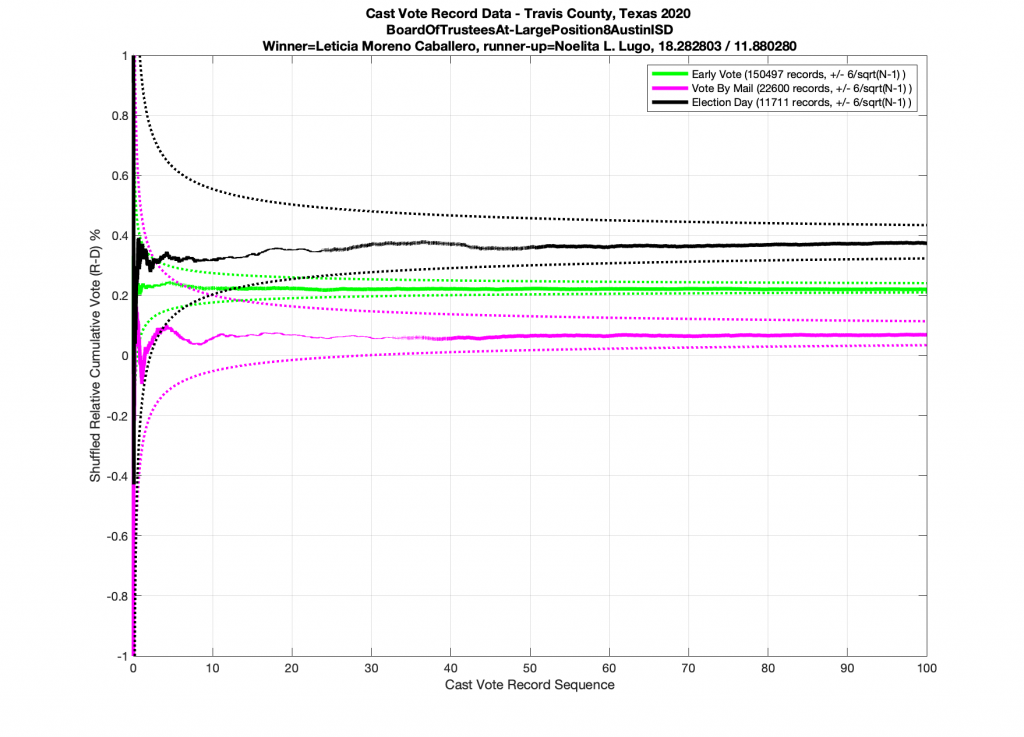
Now if I randomly shuffle the ordering of the ballots in this dataset and replot the results (below) I get a plot that looks unsurprisingly similar, which suggests that these election results were likely produced by a quasi-IID process.
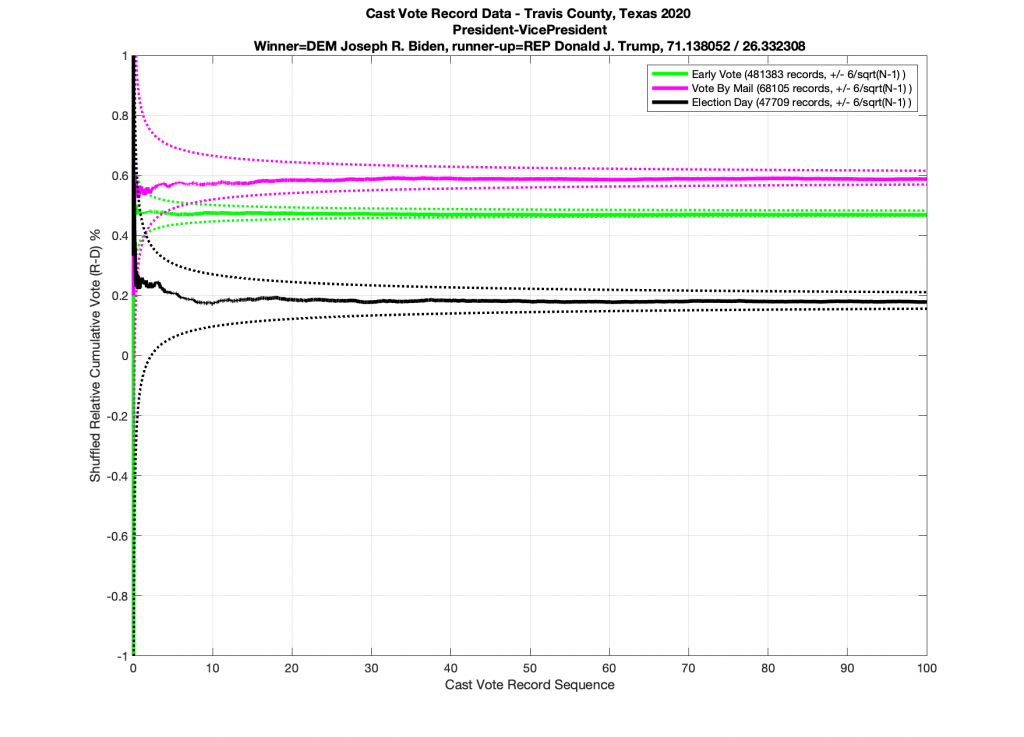
Next let’s take a look at a race that does NOT conform to the statistics we’ve laid out above. (… drum-roll please … as this the one everyone’s been waiting for). Immma just leave this right here and just simply point out that all 3 ballot type plots below in the Presidential race for 2020 go outside of the expected error bars. I also note the discrete stair step pattern in the early vote numbers. It’s entirely possible that there is a rational explanation for these deviations. I would sure like to hear it, especially since we have evidence from the exact same dataset of other races that completely followed the expected boundary conditions. So I don’t think this is an issue with a faulty dataset or other technical issues.
And just for completeness, when I artificially shuffle the data for the Presidential race, and force it to be randomized, I do in fact end up with results that conform to IID statistics (below).
I will again state that while these results are highly indicative that there were irregularities and discrepancies in the election data, they are not conclusive. A further investigation must take place, and records must be preserved, in order to discover the cause of the anomalies shown.
Running through each race that had at least 1000 ballots cast and automatically detecting which races busted the 6/sqrt(n-1) boundaries produces the following tabulated results. A 1 in the right hand column indicates that the CVR data for that particular race in Travis County has crossed the error bounds. A 0 in the right hand column indicates that all data stayed within the error bound limits.
[1] Forsberg, O.J. (2020). Understanding Elections through Statistics: Polling, Prediction, and Testing (1st ed.). Chapman and Hall/CRC. https://doi.org/10.1201/9781003019695
[2] Klimek, Peter & Yegorov, Yuri & Hanel, Rudolf & Thurner, Stefan. (2012). Statistical Detection of Systematic Election Irregularities. Proceedings of the National Academy of Sciences of the United States of America. 109. 16469-73. https://doi.org/10.1073/pnas.1210722109.
MAJOR CORRECTION (2022-07-17): The below analysis incorrectly computed the CSV totals for each of the 3 counties. I had an indexing error into my CSV file list and erroneously computed the 2020 totals from the CSV’s. I have since updated and recomputed all of the VHL and CSV results, and have additionally added a check against the Turnout report numbers as reported by ELECT. These new results will be forthcoming in an upcoming blog post. While there are still discrepancies between the VHL and CSV, their magnitude is not as large as was originally presented here. My apologies for the error. Corrected numbers for the 2020 CSV totals are shown in red below with my original estimates in strikethrough font.
(Edited 2022-07-10 17:31 EST to add better explanation of VHL and CSV files to first paragraph.)
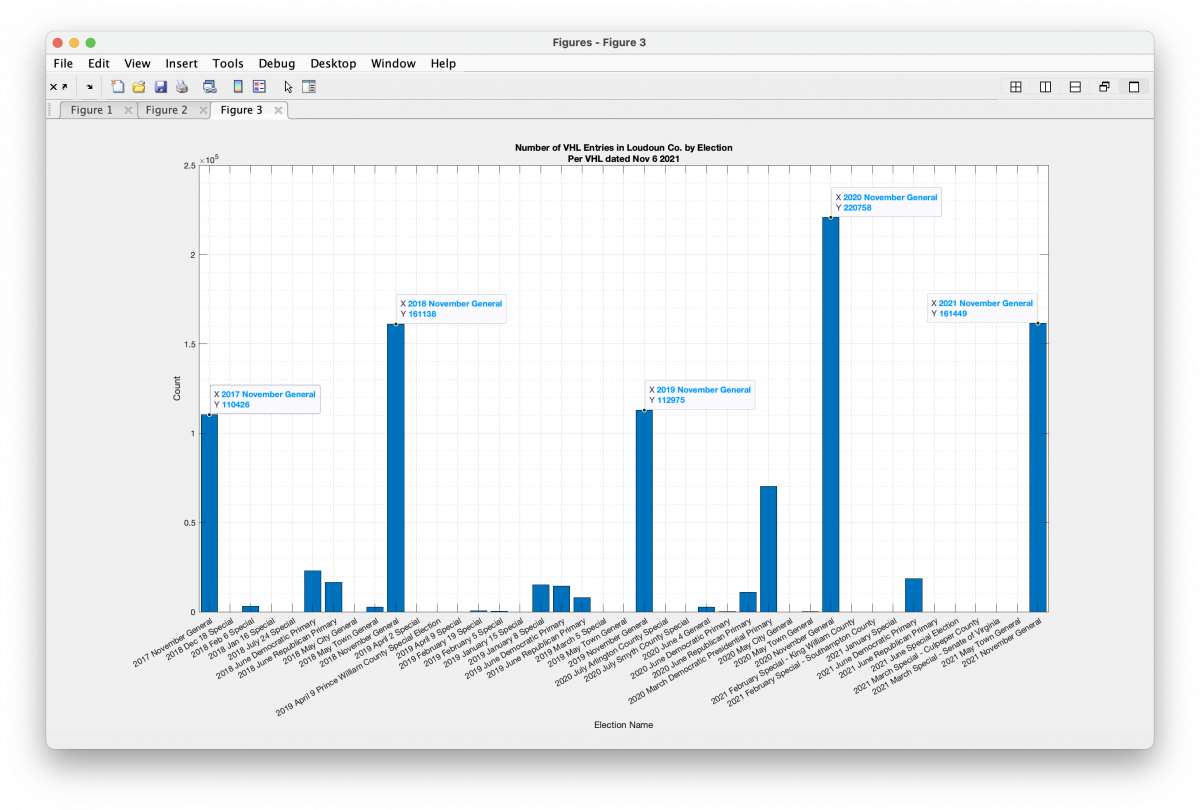
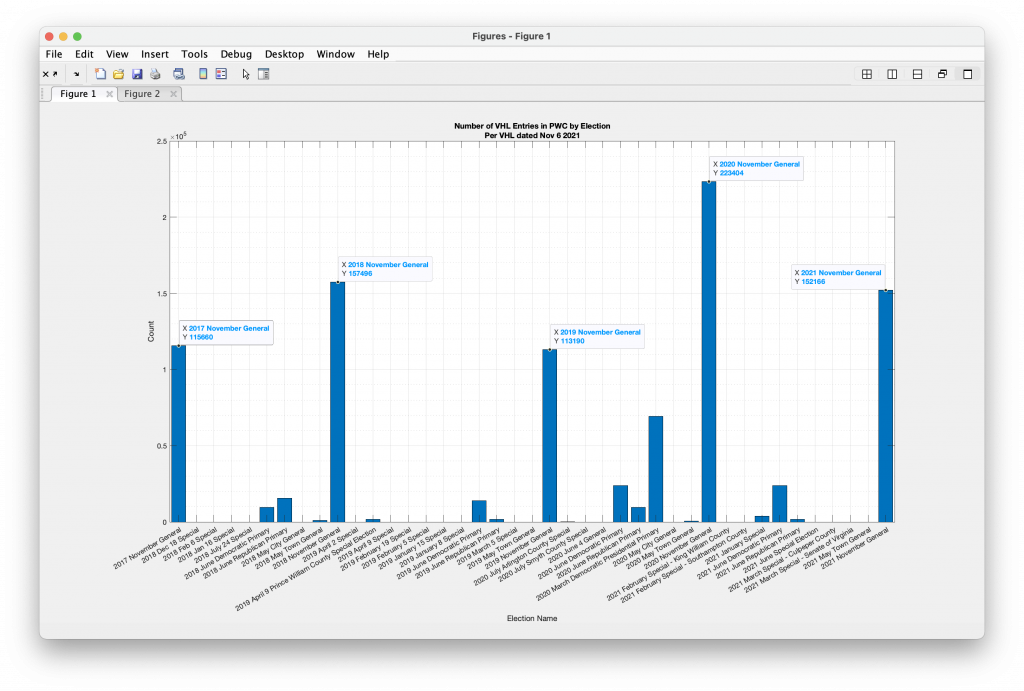
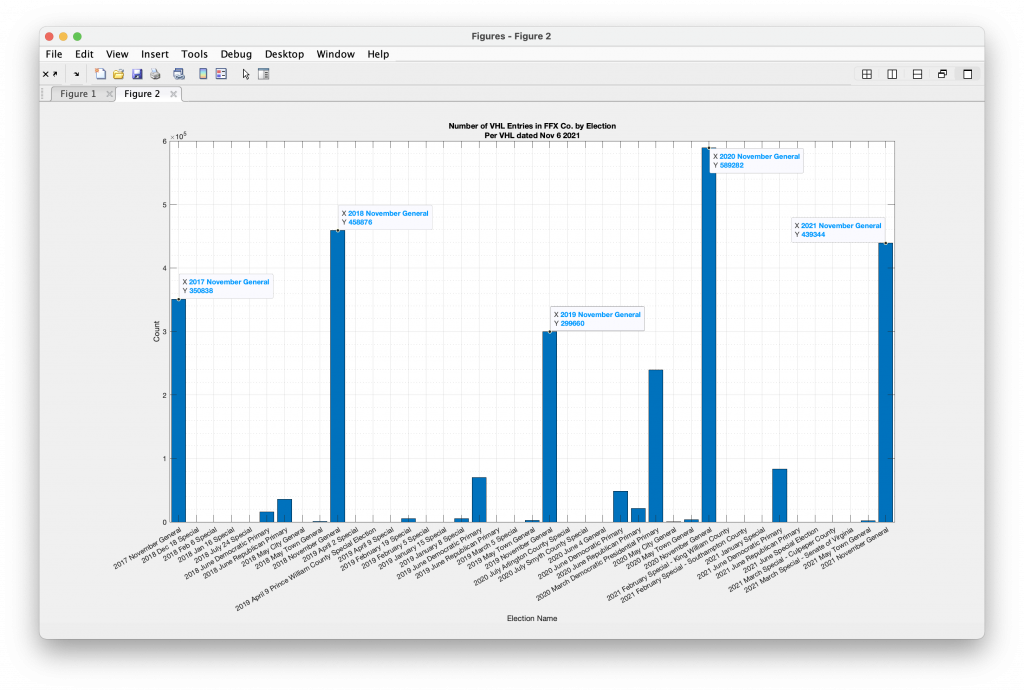
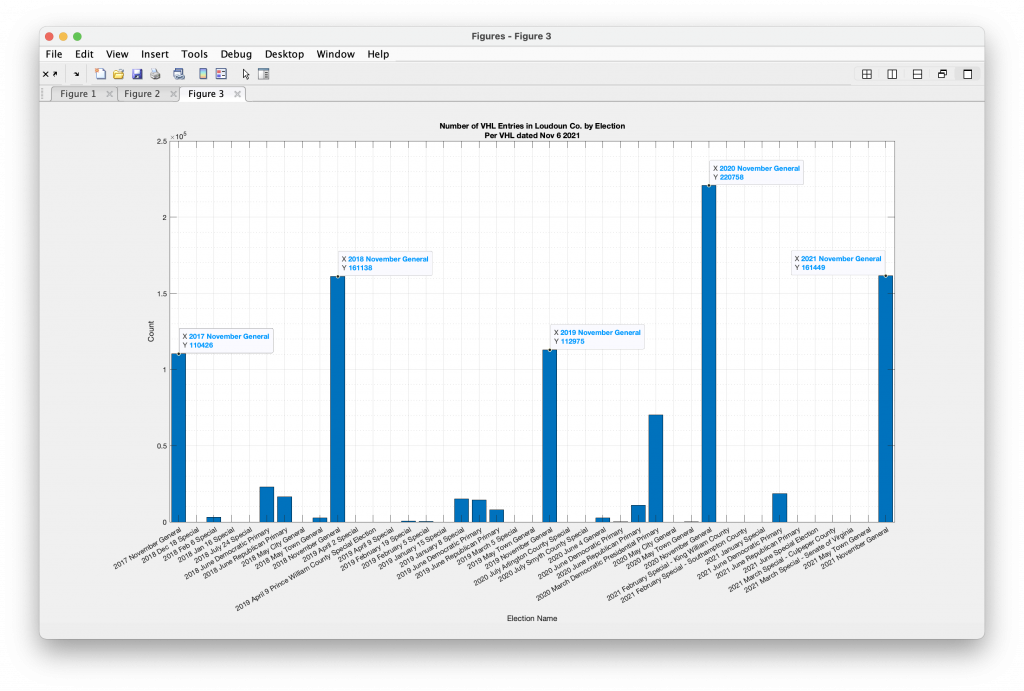
Per Request – Prince William, Fairfax and Loudoun County
According to the CSV file hosted on the ELECT servers and downloaded on 11-30-2020, the number of votes cast in Prince William County in 2020 Presidential race was 228,267 (corrected) 137,874, which is significantly different than the number of Voters that cast ballots (223,404) in 2020 as generated from the Voter History List (VHL). The 2021 CSV file, downloaded from ELECT on 12-11-2021, gives 153,218 voters as compared to 152,166 given by the VHL data. Why the discrepancies? Note that the VHL is counting people, and the CSV is counting votes cast in the races for President(2020)/Gov(2021), but the numbers should still be roughly similar between the two sources. Also the CSV “Total Vote” field should be including overvotes, write-ins, etc so that is not the source of the discrepancies. Furthermore, the 11-06-2021 VHL data file is identical to the VHL datafile downloaded on 12-14-2021, so there is no missing data from the VHL file for the 2021 election. Finally, note that by definition the Voter History List information will undercount the number of voters that participated in the 2020 election, because voters that have been removed from the registered voter list in between the end of the 2020 election period and when the file was downloaded (11-6-2021) will have had their corresponding records deleted from the VHL.
According to the CSV file hosted on the ELECT servers and downloaded on 11-30-2020, the number of votes cast in Fairfax County was 601,243 (corrected) 487232, which is significantly different than the number (589282) generated from the VHL. The 2021 CSV file, downloaded from ELECT on 12-11-2021, give 441262 voters as compared to 439344 given by the VHL data. Why the discrepancies?
According to the CSV file hosted on the ELECT servers and downloaded on 11-30-2020, the number of votes cast in Loudoun County was 224,976 (corrected) 111655, which is significantly different than the number (220758) generated from the VHL. The 2021 CSV file, downloaded from ELECT on 12-11-2021, give 161793 voters as compared to 161449 given by the VHL data. Why the discrepancies?