Last week I got asked a question as to what information is actually contained in the 2D barcode on VA drivers licenses. I didn’t know the answer, so I did some digging.
EPEC has identified at least 28 individual voter IDs in the 2024 VA March Primaries who, according to the Daily Absentee List (DAL) files purchased from the VA Department of Elections (a.k.a. “ELECT”), have a record showing they voted in both the Republican and Democratic primaries.
All of the records identified have the same voter ID and voter information appearing in both the Democratic and Republican DAL files and are recorded as having voted In-Person Early (a.k.a. an “On Machine” ballot). 26 of the individual voter IDs identified have nearly identical timestamps associated with their duplicated ballots, while 2 have significantly differing timestamps.
The number of identified records fall into a small handful of localities:
Hanover County had 1 identified record (different timestamps)
Northampton County had 1 identified record (different timestamps)
Bath County had 12 identified records
Norfolk County had 11 identified records
Franklin County had 1 identified record
Harrisonburg City had 1 identified record
Staunton City had 1 identified record
Note that the localities with identified records utilize differing poll-book or poll-pad vendors and optical scanners, so it is unlikely that these errors are due to being associated with a particular vendor.
It is not clear at this point if these records are simply errant due to technology, policy, and/or procedural issues, or if these records truly reflect individuals that cast ballots in both primaries, which is a felony according to VA law. Section 24.2-1004 of the VA code states:
B. Any person who intentionally (i) votes more than once in the same election, whether those votes are cast in Virginia or in Virginia and any other state or territory of the United States, (ii) procures, assists, or induces another to vote more than once in the same election, whether those votes are cast in Virginia or in Virginia and any other state or territory of the United States, (iii) votes knowing that he is not qualified to vote where and when the vote is to be given, or (iv) procures, assists, or induces another to vote knowing that such person is not qualified to vote where and when the vote is to be given is guilty of a Class 6 felony.
The VA Department of Elections (“ELECT”) also states:
Virginia will have a dual presidential primary election, which means both the Democratic Party and the Republican Party will have primaries on the same day.
In a dual primary, officers of election will ask voters if they want to cast their ballot in the Democratic Party Primary or the Republican Party Primary. All qualified voters may vote in either primary, but voters may not vote in both primaries.
Examining the Election Night Reporting data from the VA 2024 March Democratic and Republican primaries provides supporting evidence that the Republican primary was impacted and skewed by a large number of Democratic “crossover” voters, resulting in an irregular election fingerprint when the data is plotted.
Background
The US National Academy of Sciences (NAS) published a paper in 2012 titled “Statistical detection of systematic election irregularities.” [1] The paper asked the question, “How can it be distinguished whether an election outcome represents the will of the people or the will of the counters?” The study reviewed the results from elections in Russia and other countries, where widespread fraud was suspected. The study was published in the proceedings of the National Academy of Sciences as well as referenced in multiple election guides by USAID [2][3], among other citations.
The study authors’ thesis was that with a large sample sample of the voting data, they would be able to see whether or not voting patterns deviated from the voting patterns of elections where there was no suspected fraud. The results of their study proved that there were indeed significant deviations from the expected, normal voting patterns in the elections where fraud was suspected, as well as provided a number of interesting insights into the associated “signatures” of various electoral mechanism as they present themselves in the data.
Statistical results are often graphed, to provide a visual representation of how normal data should look. A particularly useful visual representation of election data, as utilized in [1], is a two-dimensional histogram of the percent voter turnout vs the percent vote share for the winner, or what I call an “election fingerprint”. Under the assumptions of a truly free and fair election, the expected shape of the fingerprint is of that of a 2D Gaussian (a.k.a. a “Normal”) distribution [4]. The obvious caveat here is that no election is ever perfect, but with a large enough sample size of data points we should be able to identify large scale statistical properties.
In many situations, the results of an experiment follow what is called a ‘normal distribution’. For example, if you flip a coin 100 times and count how many times it comes up heads, the average result will be 50. But if you do this test 100 times, most of the results will be close to 50, but not exactly. You’ll get almost as many cases with 49, or 51. You’ll get quite a few 45s or 55s, but almost no 20s or 80s. If you plot your 100 tests on a graph, you’ll get a well-known shape called a bell curve that’s highest in the middle and tapers off on either side. That is a normal distribution.
In a free and fair election, the plotted graphs of both the Turnout percentage and the percentage of Vote Share for Election Winner should (again … ideally) both resemble Gaussian “Normal” distributions; and their combined distribution should also follow a 2-dimensional Gaussian (or “normal”) distribution. Computing this 2 Dimensional joint distribution of the % Turnout vs. % Vote Share is what I refer to as an “Election Fingerprint”.
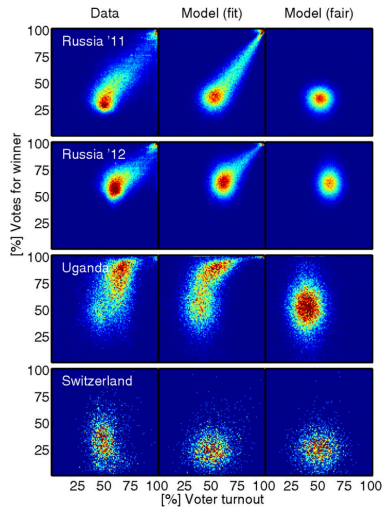
Figure 1 is reprinted examples from the referenced National Academy of Sciences paper. The actual election results in Russia, Uganda and Switzerland appear in the left column, the right column is the modeled expected appearance in a fair election with little fraud, and the middle column is the researchers’ model of the as-collected data, with any possible fraud mechanisms included.
Figure 1: NAS Paper Results (reprinted from [1])
As you can see, the election in Switzerland (assumed fair) shows a range of voter turnout, from approximately 30 – 70% across voting districts, and a similar range of votes for the winner. The Switzerland data is consistent across models, and does not show any significant irregularities.
What do the clusters mean in the Russia 2011 and 2012 elections? Of particular concern are the top right corners, showing nearly 100% turnout of voters, and nearly 100% of them voted for the winner.
Both of those events (more than 90% of registered voters turning out to vote and more than 90% of the voters voting for the winner) are statistically improbable, even for very contested elections. Election results that show a strong linear streak away from the main fingerprint lobe indicates ‘ballot stuffing,’ where ballots are added at a specific rate. Voter turnout over 100% indicates ‘extreme fraud’. [1][5]
Note that election results with ‘outliers’ – results that fall outside of expected normal voting patterns – while evidentiary indicators, are not in and of themselves definitive proof of outright fraud or malfeasance. For example, in rare but extreme cases, where the electorate is very split and the split closely follows the geographic boundaries between voting precincts, we could see multiple overlapping Gaussian lobes in the 2D image. Even in that rare case, there should not be distinct structures visible in the election fingerprint, linear streaks, overly skewed or smeared distributions, or exceedingly high turnout or vote share percentages. Additional reviews of voting patterns and election results should be conducted whenever deviations from normal patterns occur in an election.
Additionally it should be noted that “the absence of evidence is not the evidence of absence”: Election Fingerprints that look otherwise normal might still have underlying issues that are not readily apparent with this view of the data.
Results on 2024 VA March Primaries:
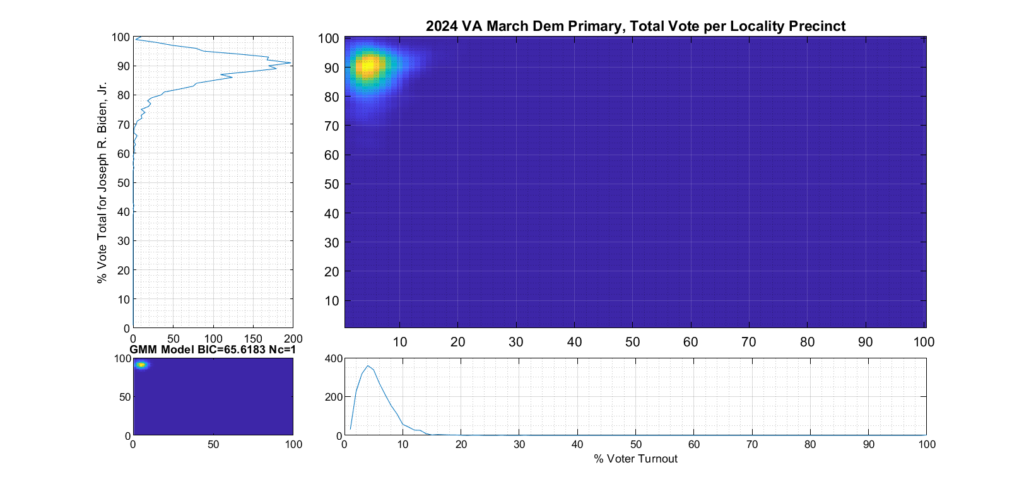
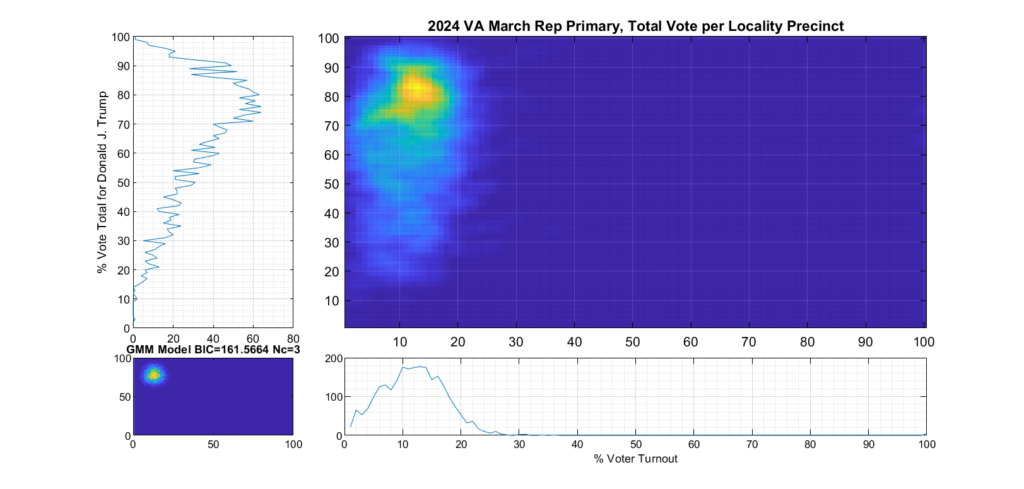
Figure 2 and Figure 3 are the computed election fingerprints for the Democratic and Republican VA 2024 March Primaries, respectively. They were computed according to the NAS paper and using official state reported voter turnout and votes for the statewide winner and reported per voting Locality with combined In-Person Early, Election Day, Absentee and Provisional votes. Figures 4 and 5 perform the same process, except each data point is generated per individual precinct in a locality. The color scale moves from precincts with low counts as deep blue, to precincts with high numbers represented as bright yellow. Note that a small blurring filter was applied to the computed image for ease of viewing small isolated Locality or Precinct results.
The upper right inset in each graphic image was computed per the NAS paper; the bottom left inset shows what an idealized model of the data could or should look like, based on the reported voter turnout and vote share for the winner. This ideal model is allowed to have up to 3 Gaussian lobes based on the peak locations and standard deviations in the reported results. The top-left and bottom-right inset plots show the sum of the rows and columns of the fingerprint image. The top-left graph corresponds to the sum of the rows in the upper right image and is the histogram of the vote share for the winner across precincts. The bottom right graph shows the sum of the columns of the upper right image, and is the histogram of the percentage turnout across voting localities.
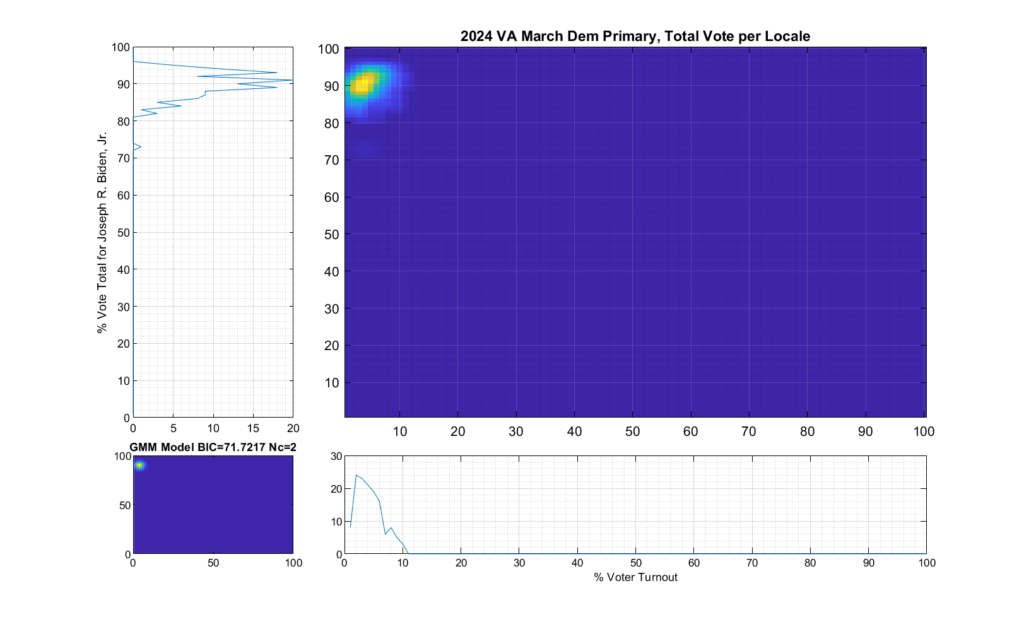
Figure 2 Democratic primary, accumulated per Locality:
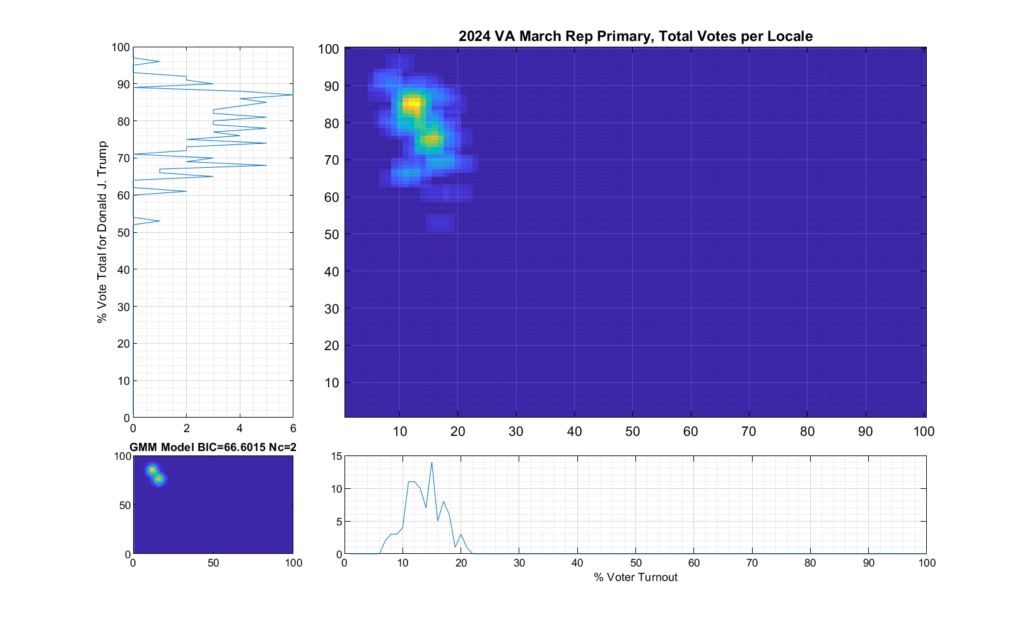
Figure 3 Republican primary, accumulated per Locality:
Figure 4 Democratic primary, accumulated per Precinct:
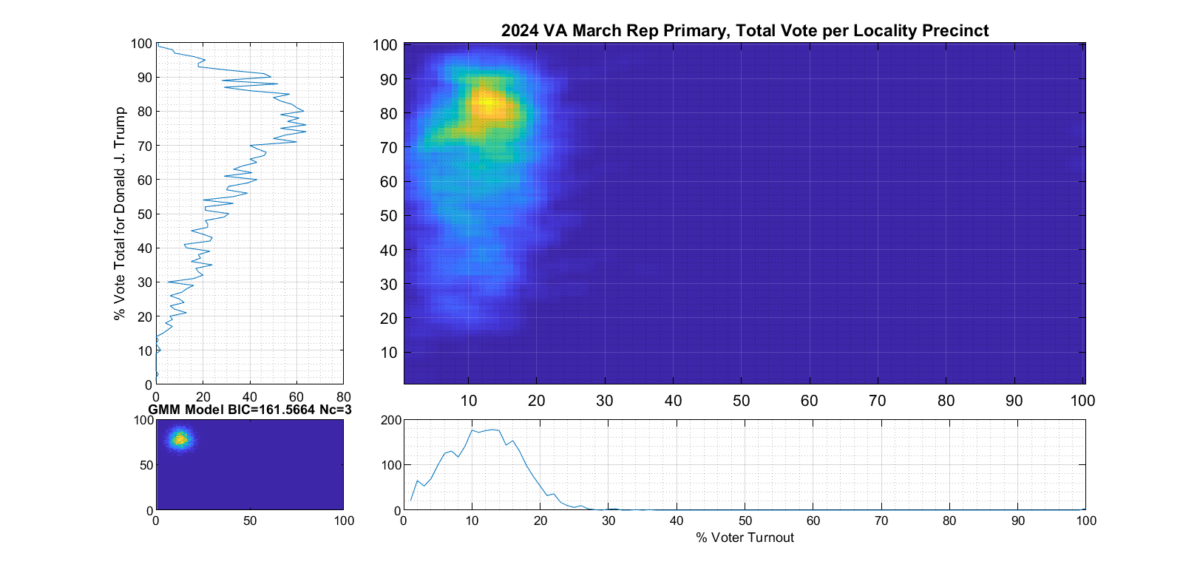
Figure 5 Republican primary, accumulated per Precinct:
Analysis:
As can be seen in Figure 2 and 4, the Democratic primary fingerprint looks to fall within expected normal distribution. Even though the total vote share for the winner (Biden) is up around 90%, this was not unexpected given the current set of contestants and the fact that Biden is the incumbent.
The Republican primary results, as shown in Figure 3 and 5, show significant “smearing” of the percent of total vote share for the winner. The percent of voter turnout (x-axis) does however show a near Gaussian distribution, which is what one would expect. The republican primary data does not show the linear streaking pattern that the authors in [1] correlate with extreme fraud, but significant smearing of the distribution is observed.
A consideration that might partially explain this smearing of the histogram, is that there was at least 17% of “crossover voters” who historically lean Democrat but voted in the Republican primary (see here for more information). Multiple news reports and exit polling suggest that this was due in part to loosely organized efforts by the opposing party to cast “Protest Votes” and artificially inflate the challenger (Haley) and dilute the expected (Trump) margin of victory for the winner, with no intention of supporting a Republican candidate in the General Election. (This is completely legal in VA, by the way, as VA does not require by-party voter registration.)
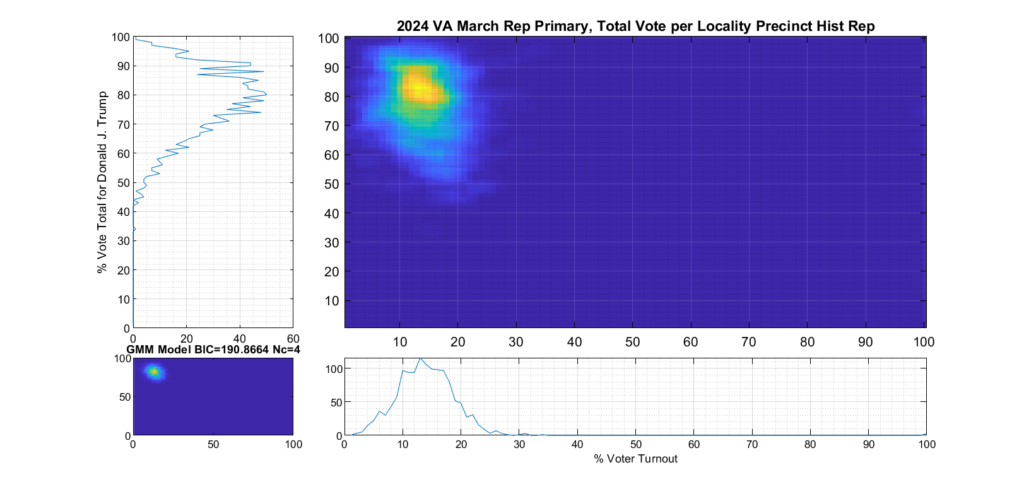
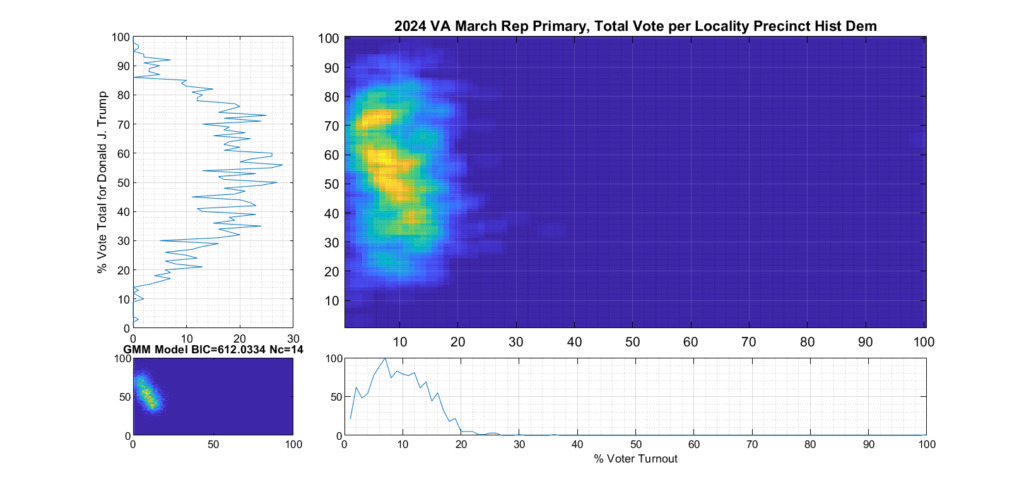
If we categorize each locality as being either Democratic or Republican leaning based on the average results of the last four presidential elections, and then split the computation of the per precinct results into separate parts accordingly, we can see this phenomenon much clearer.
Figure 6 shows the per-precinct results for only those locality precincts that belong to historic Republican leaning localities. It depicts a much tighter distribution and has much less smearing or blurring of the distribution tails. We can see from the data that Republican base in historically Republican leaning localities seems solidly behind candidate Trump.
Figure 7 shows the per-precinct results for only those locality precincts that belong to historic Democratic leaning localities. It can clearly be seen by comparing the two plots that the major contributor to the spread of the total republican primary distribution is the votes from historically Democratic leaning localities.
Figure 6 Republican primary, accumulated per Precinct in Republican leaning localities:
Figure 7 Republican primary, accumulated per Precinct in Democratic leaning localities:
References:
[1] “Statistical detection of election irregularities” Peter Klimek, Yuri Yegorov, Rudolf Hanel, Stefan Thurner Proceedings of the National Academy of Sciences Oct 2012, 109 (41) 16469-16473; DOI: 10.1073/pnas.1210722109 (https://www.pnas.org/content/109/41/16469)
[5] Mebane, Walter R. and Kalinin, Kirill, Comparative Election Fraud Detection (2009). APSA 2009 Toronto Meeting Paper, Available at SSRN: https://ssrn.com/abstract=1450078
As I was going through and processing the (new) VA election night reporting data provided by Enhanced Voting, I noticed a number of technical issues with the data feed. I’ve tried to capture them here in the attempt to help assist the VA Department of Elections in correcting bugs and implementation issues with their new reporting format.
While the new ENR data feed is commendable in that it presents the data for the state in an easily obtainable JSON formatted file, the following issues were observed in my processing of the data. I am happy to provide specific examples of these issues to the Enhanced Voting development team in order to help address them.
Inconsistent JSON formats being returned. Sometimes locality group results information is a cell of structures, sometimes an array.
Occasional mal-formed JSON, missing opening or closing parentheses or brackets causing the file to not be able to be parsed by JSON importing functions in python, MATLAB, etc.
Occasional duplicated locality precinct group result information
There are currently two completely separate but simultaneous primary elections being held in VA, with actual Election Day coming up fast on March 5th. As part of EPEC’s data analysis on the ongoing Democrat and Republican primaries, I took some time to look at the distribution of voter participation. VA does not have voter registration by party, but participation in primary elections is often used as a surrogate method to try and estimate a voter leaning.
I was specifically interested as to how many “cross-over” voters were participating in each parties primary. There have been multiple news articles (here, for example) discussing the potential for democrats to cross-vote in the 2024 Primaries, and I wanted to see if I could observe evidence of that behavior in the data.
Results:
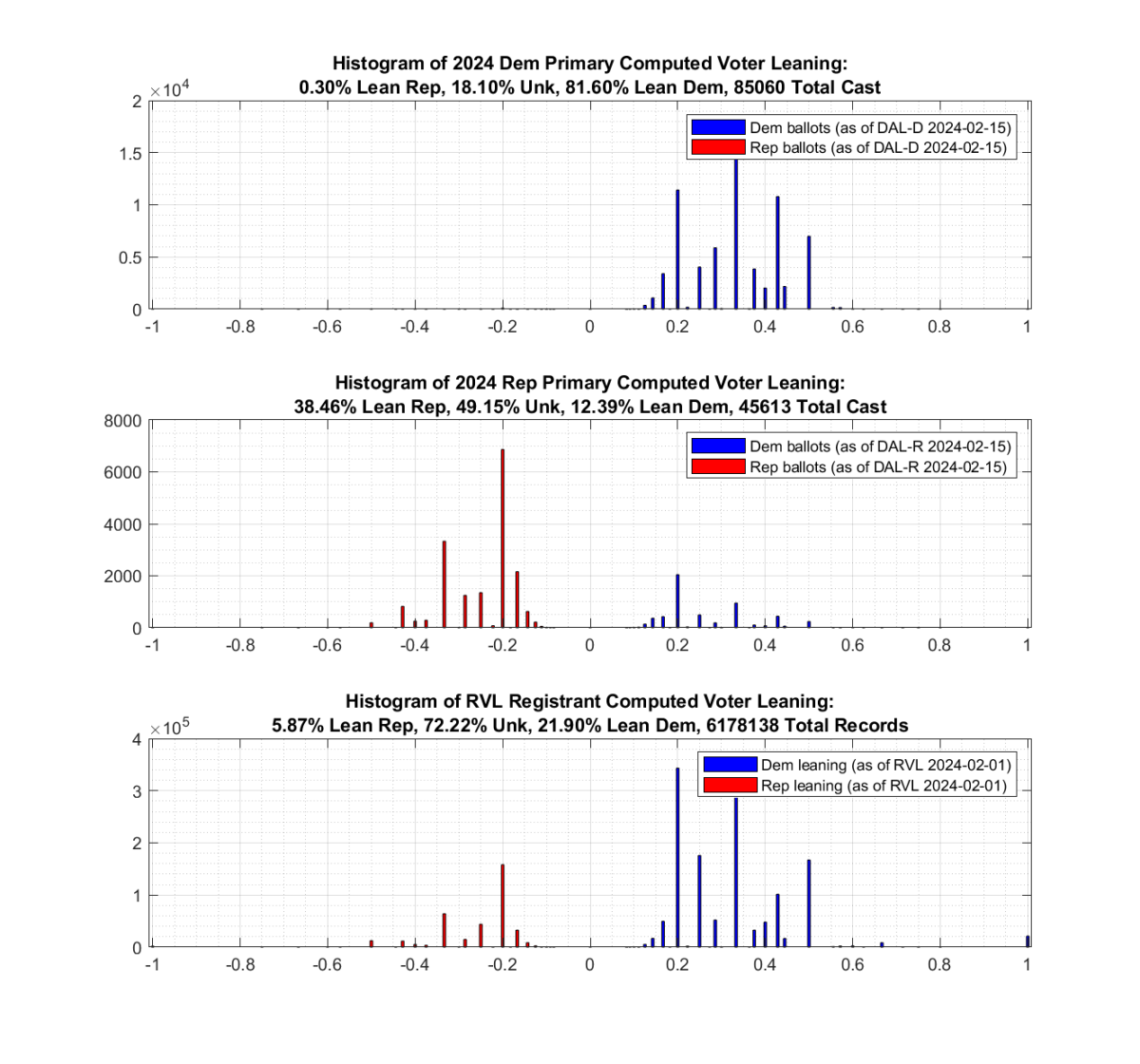
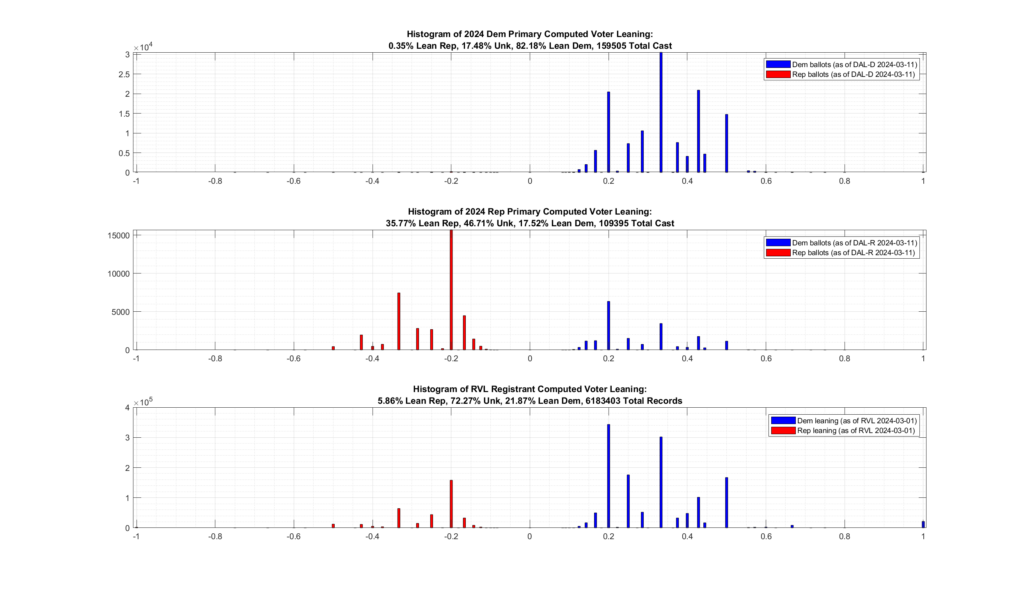
As can be seen from the image below, there is definitely evidence of crossover voting occurring, with historically democratic primary voters crossing over and voting in this years (2024) Republican primary.
Approximately 17.5% of the 109,395 ballots cast in the 2024 VA Republican primary are associated with historically Democrat leaning registrants. Only 0.35% of the 159,505 ballots cast in the 2024 VA Democratic primary are associated with historically Republican leaning registrants. [Note this plot was updated on 2024-03-11 to reflect the latest values. The previous results from mid-February had the number of crossover D->R voters at ~12%]
Method:
Step 1: Compute an estimate of voter leaning.
The data utilized in this analysis all comes directly from the VA Dept of Elections (“ELECT”) and includes the statewide Registered Voter List (“RVL”) and Voter History List (“VHL”) files dated 03/11/2024, as well as the Daily Absentee List (“DAL”) files corresponding to each of the ongoing Democrat and Republican primaries.
An estimation of each party leaning is first computed by going through the VHL and for each unique voter in the VHL summing the number of Democrat or Republican primaries that voter has participated in historically. We then take the difference of these two fields and divide by the total number of election contests the voter has participated in. This gives us a resultant estimate of the “leaning” for each unique voter.
leaning = (# Dem Primaries – # Rep Primaries) / (# of Total Contests)
A leaning < 0 indicates a Republican lean, and > 0 indicates a Democratic lean. A voter might have a lean == 0 if they had a balanced participation in previous primaries, or if there is no voter history for that particular voter.
Step 2: Plot the histogram of voter leaning for ballots cast so far in both the Democratic and Republican primaries. Additionally plot the Computed voter leaning for the entire RVL as a reference.
Below you will find the current summary data and graphics from the VA 2024 Republican Primary Election Daily Absentee List files. We pull the DAL file everyday and track the count of each specific ballot category in each daily file.
Note: Page may take a moment to load the graphics objects.
Place your cursor over the series name in the legend at right to see the series highlighted in the graphic. Place your cursor over a specific data point to see that data points value.
The logarithmic plot is the same underlying data as the linear scale plot, except with a logarithmic y-scale in order to be able to compress the dynamic range and see the shape of all of the data curves in a single graphic. Place your cursor over the series name in the legend at right to see the series highlighted in the graphic. Place your cursor over a specific data point to see that data points value.
The underlying data for the graphics above is provided in the summary data table.
Additional Data:
Additional CSV datasets stratified by Locality, City, Congressional District, State House District, State Senate District, and Precinct are available here.
Data column descriptions:
“ISSUED” := Number of DAL file records where BALLOT_STATUS= “ISSUED”
“NOT_ISSUED” := Number of DAL file records where BALLOT_STATUS= “NOT ISSUED”
“PROVISIONAL” := Number of DAL file records where BALLOT_STATUS= “PROVISIONAL” and APP_STATUS=”APPROVED”
“DELETED” := Number of DAL file records where BALLOT_STATUS= “DELETED”
“MARKED” := Number of DAL file records where BALLOT_STATUS= “MARKED” and APP_STATUS=”APPROVED”
“ON_MACHINE” := Number of DAL file records where BALLOT_STATUS= “ON_MACHINE” and APP_STATUS=”APPROVED”
“PRE_PROCESSED” := Number of DAL file records where BALLOT_STATUS= “PRE-PROCESSED” and APP_STATUS=”APPROVED”
“FWAB” := Number of DAL file records where BALLOT_STATUS= “FWAB” and APP_STATUS=”APPROVED”
“MAIL_IN” := The sum of “MARKED” + “PRE_PROCESSED”
“COUNTABLE” := The sum of “PROVISIONAL” + “MARKED” + “PRE_PROCESSED” + “ON_MACHINE” + “FWAB”
“MILITARY” := Number of DAL file records where VOTER_TYPE= “MILITARY”
“OVERSEAS” := Number of DAL file records where VOTER_TYPE= “OVERSEAS”
“TEMPORARY” := Number of DAL file records where VOTER_TYPE= “TEMPORARY”
“MILITARY_COUNTABLE” := Number of DAL file records where VOTER_TYPE= “MILITARY” and where COUNTABLE is True
“OVERSEAS_COUNTABLE” := Number of DAL file records where VOTER_TYPE= “OVERSEAS” and where COUNTABLE is True
“TEMPORARY_COUNTABLE” := Number of DAL file records where VOTER_TYPE= “TEMPORARY” and where COUNTABLE is True
All data purchased by Electoral Process Education Corp. (EPEC) from the VA Dept of Elections (ELECT). All processing performed by EPEC.
If you like the work that EPEC is doing, please support us with a donation.
Below you will find the current summary data and graphics from the VA 2024 Democratic Primary Election Daily Absentee List files. We pull the DAL file everyday and track the count of each specific ballot category in each daily file.
Note: Page may take a moment to load the graphics objects.
Place your cursor over the series name in the legend at right to see the series highlighted in the graphic. Place your cursor over a specific data point to see that data points value.
The logarithmic plot is the same underlying data as the linear scale plot, except with a logarithmic y-scale in order to be able to compress the dynamic range and see the shape of all of the data curves in a single graphic. Place your cursor over the series name in the legend at right to see the series highlighted in the graphic. Place your cursor over a specific data point to see that data points value.
The underlying data for the graphics above is provided in the summary data table.
Additional Data:
Additional CSV datasets stratified by Locality, City, Congressional District, State House District, State Senate District, and Precinct are available here.
Data column descriptions:
“ISSUED” := Number of DAL file records where BALLOT_STATUS= “ISSUED”
“NOT_ISSUED” := Number of DAL file records where BALLOT_STATUS= “NOT ISSUED”
“PROVISIONAL” := Number of DAL file records where BALLOT_STATUS= “PROVISIONAL” and APP_STATUS=”APPROVED”
“DELETED” := Number of DAL file records where BALLOT_STATUS= “DELETED”
“MARKED” := Number of DAL file records where BALLOT_STATUS= “MARKED” and APP_STATUS=”APPROVED”
“ON_MACHINE” := Number of DAL file records where BALLOT_STATUS= “ON_MACHINE” and APP_STATUS=”APPROVED”
“PRE_PROCESSED” := Number of DAL file records where BALLOT_STATUS= “PRE-PROCESSED” and APP_STATUS=”APPROVED”
“FWAB” := Number of DAL file records where BALLOT_STATUS= “FWAB” and APP_STATUS=”APPROVED”
“MAIL_IN” := The sum of “MARKED” + “PRE_PROCESSED”
“COUNTABLE” := The sum of “PROVISIONAL” + “MARKED” + “PRE_PROCESSED” + “ON_MACHINE” + “FWAB”
“MILITARY” := Number of DAL file records where VOTER_TYPE= “MILITARY”
“OVERSEAS” := Number of DAL file records where VOTER_TYPE= “OVERSEAS”
“TEMPORARY” := Number of DAL file records where VOTER_TYPE= “TEMPORARY”
“MILITARY_COUNTABLE” := Number of DAL file records where VOTER_TYPE= “MILITARY” and where COUNTABLE is True
“OVERSEAS_COUNTABLE” := Number of DAL file records where VOTER_TYPE= “OVERSEAS” and where COUNTABLE is True
“TEMPORARY_COUNTABLE” := Number of DAL file records where VOTER_TYPE= “TEMPORARY” and where COUNTABLE is True
All data purchased by Electoral Process Education Corp. (EPEC) from the VA Dept of Elections (ELECT). All processing performed by EPEC.
If you like the work that EPEC is doing, please support us with a donation.
The below is based on the discussion of “Single Transferrable Vote” (“STV”) methods in [1], published in 1977. STV has more recently been called “Ranked Choice Voting” (RCV) or “Instant Runoff Voting” (IRF), among other names, by lobbying groups that are currently pushing for its incorporation into our voting systems. Irrespective of the name used, it represents a family of voting methods, with slightly different variants depending on how votes are removed and/or redistributed in each successive round of voting. [2][5]
What does STV/RCV/IRV entail, in general:
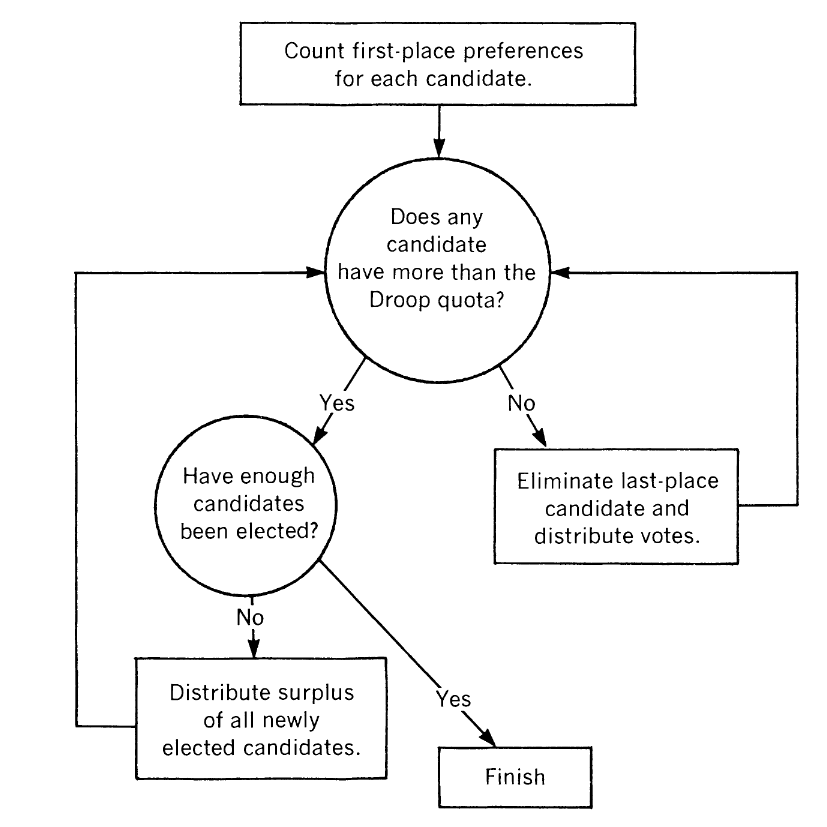
The core system is a proportional voting system, where voters are required to rank order their preferred candidate selections and all ballots are collected and centralized tabulation is performed in multiple rounds until winner(s), or candidates that have support above a specified quota (or “threshold”), are allocated.
A common definition of the quota utilized in STL/RCV/IRV systems is the “Droop quota”, and is defined as:
q = FLOOR( # of Voters / (# of Seats + 1) + 1)
In a given round the candidate with the least support is eliminated from further evaluation. Surplus votes from candidates that go over the droop threshold and votes from eliminated candidates can be distributed amongst remaining candidates for subsequent rounds. Surplus vote distribution is only applicable when multiple winners are allowed in a contest.
Vote allocation procedure for STV/RCV/IRV. Reprinted from [1].
The arguments used to support and push for RCV have not significantly changed since the time that the original paper was published, but the terms and language utilized have been modified. The authors note that much of the rationale in pushing for STV was centered around the ideas of inclusivity and making sure voters are able to cast “effective” ballots.
“Modem proponents emphasize the system’s effective representation of minorities, its sensitivity and accuracy in ‘measuring changes in popular will,’ and its tendency to encourage independent (nonparty line) voting.”
Doron, G., & Kronick, R. (1977) [1]
The same arguments have been recently repeated and pushed to legislators and the media. The name has changed from “Single Transferrable Vote” to “Ranked Choice Voting” or “Instant Runoff Voting”, but the argument remains largely the same, as can be seen by simply visiting the websites and promotional material for any of the current groups that are lobbying for RCV to be incorporated [3][4].
The issue pointed out by Doron & Kronick:
The authors in [1] note that the STV/RCV/IRV system allows for a “perversion” (their words, not mine) whereby a candidates chances to be selected as a winner can potentially be negatively impacted even when receiving increased support.
“… a function that permitted an increased vote for a candidate to cause a decline in that candidate’s rank in the social ordering-would probably strike most of us as a rather absurd, even perverse, method of arriving at a social choice. Consequently, some writers refer to this condition as the ‘Non-Perversity’ condition. All of the democratic social choice functions that have been considered in the literature were assumed to guarantee this condition, but the Single Transferrable Vote system does not.”
Doron, G., & Kronick, R. (1977) [1]
The authors present a hypothetical example to demonstrate the issue. Suppose we have 3 candidates (Candidate X, Candidate Y, Candidate Z) and two different voting groups, which we will refer to as group D and D’. Both D and D’ are fairly similar and only disagree on the relative ranking of two specific candidates.
In the tables below, recreated from [1], the only difference in the two voting group selections is that candidate X receives more support than candidate Y in group D’. However, if using the voting rules as described above candidate X wins in D, and loses in D’ even though X has increased support in D’.
# of Voters
First Choice
Second Choice
Third Choice
6
X
Y
Z
2
Y
X
Z
4
Y
Z
X
5
Z
X
Y
Voting group D selections. Reprinted from [1].
# of Voters
First Choice
Second Choice
Third Choice
6
X
Y
Z
2
X
Y
Z
4
Y
Z
X
5
Z
X
Y
Voting group D’ selections. Reprinted from [1].
There are 17 voters in each case, and only 1 seat available. Therefore, the Droop quota/threshold is 9 votes required in order to declare a winner.
In group D it is candidate Z that has the least amount of votes in the first round and is eliminated, therefore advancing 5 second-choice votes for X into the next round. Candidate X passes the threshold and wins in the second round.
In group D’, where candidate X received more support than candidate Y, it is candidate Y that has the least amount of votes in the first round and is eliminated, therefore advancing 4 second-choice votes for Z into the next round. Candidate Z then passes the threshold and wins in the second round.
Bibliography:
Doron, G., & Kronick, R. (1977). Single Transferrable Vote: An Example of a Perverse Social Choice Function. American Journal of Political Science, 21(2), 303–311. https://doi.org/10.2307/2110496
Brandt F, Conitzer V, Endriss U, Lang J, Procaccia AD, eds. Handbook of Computational Social Choice. Cambridge: Cambridge University Press; 2016. https://doi.org/10.1017/CBO9781107446984
Update (2023-12-14 12:00:00 EST) : Special thank you to Rick Michael of the Chesterfield Electoral board for checking their records on issues #1 and #2 below. There were 3 x Issue #1 records and 9 x Issue #2 records identified in Chesterfield County.
According to Rick, the records in question were populated and visible when looking via the electronic VERIS (the states election database) login available to the Registrar. The 3 x Issue #1 records can be found and are Active records in the electronic system, and the 9 x Issue #2 records had an update that moved the records from Inactive to Active that were not reflected in the data supplied to us.
That implies that the data that we purchased (for approximately $12,000) directly from the department of elections is inaccurate and incomplete. Our initial purchase and download of the June 30 Registered Voter List (RVL) database does not show the registrants identified in Issue #1, even though the Registrar can see them in their electronic terminal. And our Monthly Update Subscription (MUS) we receive is missing the updates showing the registrant records identified in Issue #2 being moved from Inactive to Active status.
The department of elections is required by federal law (NVRA, HAVA) to keep and maintain accurate election records AND to make those records accessible for inspection and verification, and for use by candidates and political parties. Additionally, we have paid (twice!) for this data; once as taxpayers, and once again as a 501c3 entity. If the data we, and other campaigns and candidates are receiving is not representative of the actual records in the database, incomplete and inaccurate … that needs to be addressed and fixed.
Summary:
Issue #1: There are 99 records of ballots cast, according to the VA Department of Elections (ELECT) Daily Absentee List (DAL) data file that do not have corresponding voter ID listed in Registered Voter List (RVL) data.
Issue #2: There are 380 records of ballots cast in the DAL where the corresponding RVL record has been listed as “Inactive” since June-30-2023 and no modification to the RVL record has taken place.
Issue #3: There are 18 records of ballots cast in the DAL where the corresponding RVL record is listed as “Inactive” as of Dec-01-2023, but there has been previous modifications to the RVL record since June-30-2023.
We are currently reaching out in attempts to contact the VA AG’s office and to provide them the details of this analysis in order to have these anomalies further investigated.
Data files utilized for this analysis:
Our 501c3 EPEC purchased and downloaded the full statewide VA RVL on June-30-2023 from ELECT. We additionally purchased the Monthly Update Service (MUS) package from ELECT, where on the 1st of each month we are provided a list of all of the changes that have occurred to the RVL in the previous month. By applying these changes to our baseline data file, we are able to update our copy of the RVL to reflect the latest state as per ELECT. We can also create a cumulative record of all entries associated with a particular voter ID by simply concatenating all of these datafiles.
Additionally, during the VA 2023 General Election, we purchased access to the Daily Absentee List (DAL) file generated by ELECT that documents all of the transactions associated with early mail-in or in-person voting during the 45 day early voting period. The DAL file we utilized for this analysis was downloaded from ELECT on Nov-13-2023 at 6am EST.
Identification of ballots cast via the DAL file can be performed by checking for rows of the DAL data table that have the APP_STATUS field set to “Approved” and have the BALLOT_STATUS field set to any of the following: “Marked” | “Pre-Processed” | “On Machine” | “FWAB” | “Provisional”.
Once cast ballots are identified in the DAL, the Voter Identification Number can be used to lookup all of the corresponding records in our cumulative RVL data. The data issues summarized above can be directly observed using this process. Due to VA law, we cannot publish the full specific records here in this blog but have summarized, captured and described our process and results.
For Issue #1: If there does not exist a corresponding registration record for cast ballots, then the voter should not have been able to have their mail-in ballot approved or issued, or been able to check-in to an early voting precinct to vote on-machine. If the voter record actually does exists, then why is it not reflected in the data that we purchased from ELECT. Note that all provisional and Same Day Registration (SDR) ballots were required to be entered into the states database (“VERIS”) by the Friday after the election (Fri Nov-10-2023). We specifically waited until we received the Dec-01-2023 MUS data update from ELECT to attempt to perform this or similar analysis in order to ensure that we would not be missing any last minute registrations or RVL updates.
For Issue #2: There are 380 records of ballots being cast in the DAL where the baseline June-30-2023 RVL data file shows the registrant as inactive, and there has been no modifications or adjustments to the record presented in the MUS data files. Therefore these registrants should still have been listed as “Inactive” during the early voting period which started in September through Election Day (Nov 7).
For issue #3: There are 18 records that show the cast ballot is from a registrant that is currently listed as “Inactive” but there has been adjustments to the registration record over the last 6 months. An example of such is below. Note that I have captured the MUS data file generation dates in the 5th column to note when the file was generated and received by us.
In the example given below, the first invalidation operation on the registration record appears in the MUS file dated Sep-01, with the earliest transaction date listed as Aug-29-2023. The ballot application was not received until Sept 26 according to the DAL, so the application should never have been approved or the ballot issued as the registrant status should have been “Invalid” according to the states own data.
(Also … yes … I know there is a typo in the spelling of “APP_RECIEPT_DATE” in the tables below … but this is the data as it comes from ELECT).
APP_RECIEPT_DATE
APP_STATUS
BALLOT_RECEIPT_DATE
BALLOT_STATUS
“2023-09-26 00:00:00”
Approved
“2023-10-19 00:00:00”
Pre-Processed
Example Extract of a DAL data record for a mail-in ballot cast during early voting.
TRANSACTIONDATE
TRANSACTIONTIME
Trans_Type
NVRAReasonCode
File Source
30-June-2023
12:12:00
BASELINE
BASELINE
Baseline RVL
28-Jul-2023
09:34:03
MODIFY
Change Out
MUS 08/01/2023
28-Jul-2023
09:34:04
MODIFY
Address Change
MUS 08/01/2023
28-Jul-2023
09:34:04
MODIFY
Change In
MUS 09/01/2023
28-Jul-2023
09:34:03
MODIFY
Change Out
MUS 09/01/2023
28-Jul-2023
09:34:04
MODIFY
Address Change
MUS 09/01/2023
28-Jul-2023
09:34:04
MODIFY
Change In
MUS 09/01/2023
29-Aug-2023
11:55:49
MODIFY
Inactivate
MUS 09/01/2023
29-Aug-2023
11:55:49
MODIFY
Inactivate
MUS 10/01/2023
Extract of RVL Cumulative Data Records for Voter ID in above DAL entry
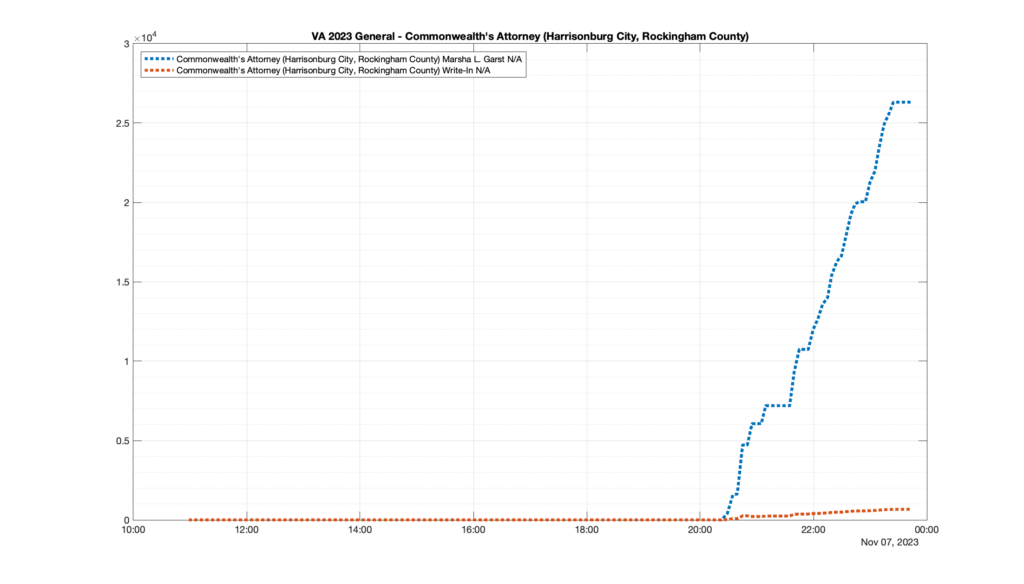
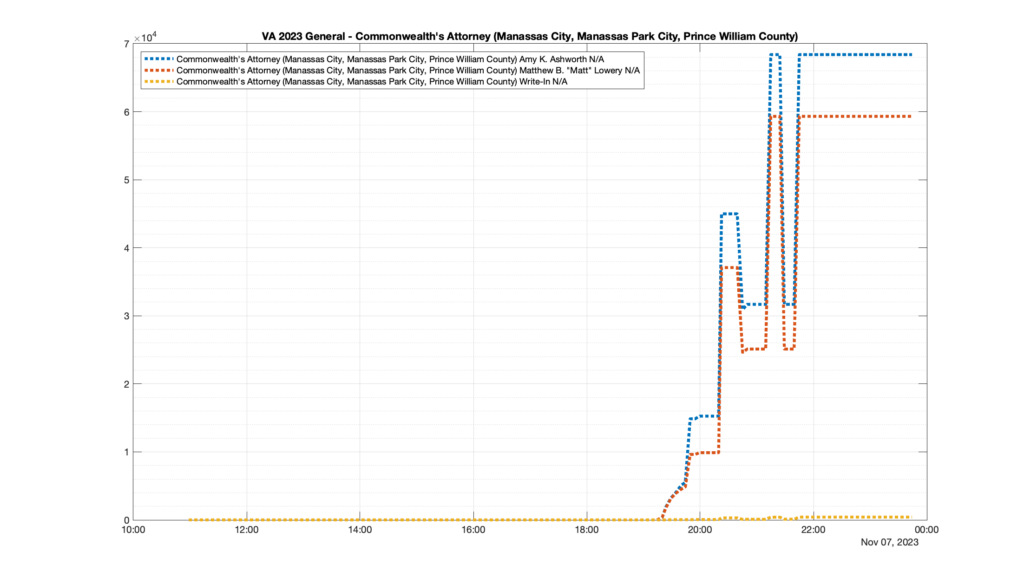
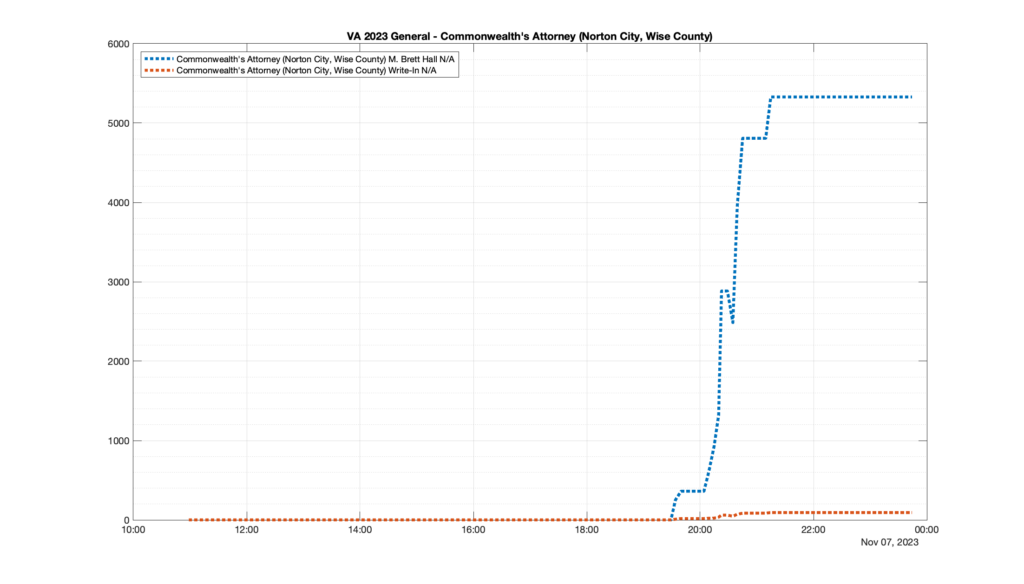
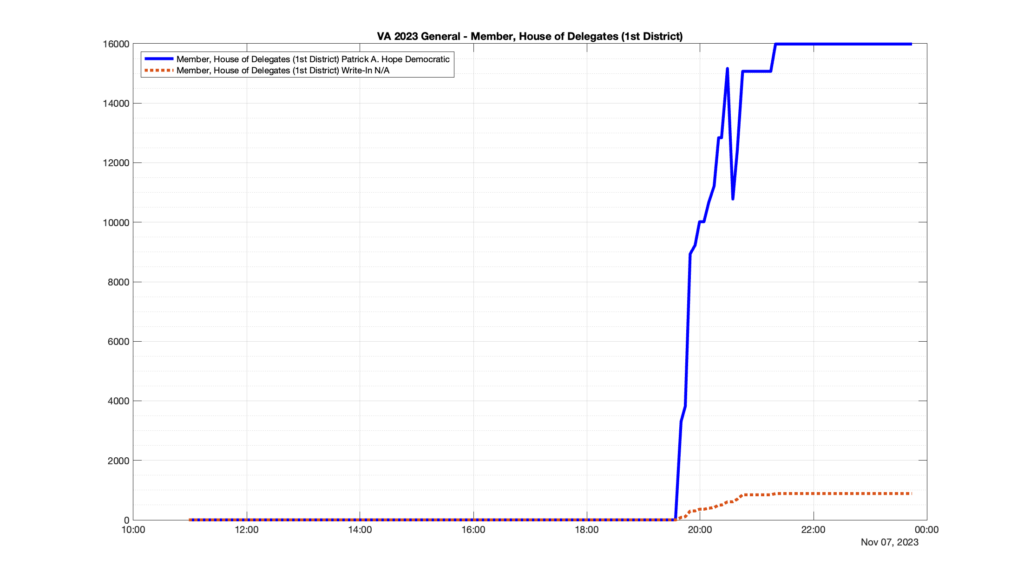
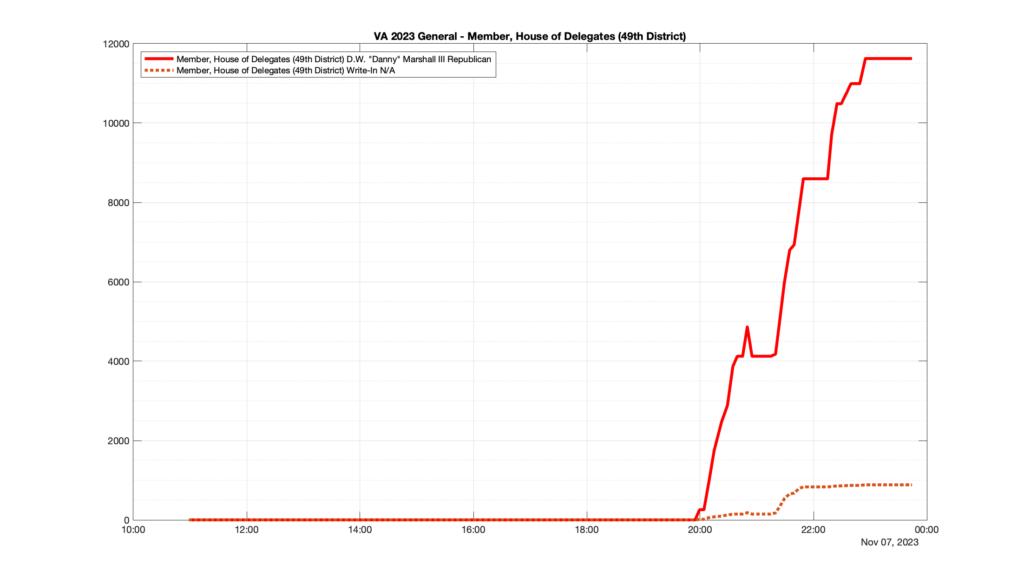
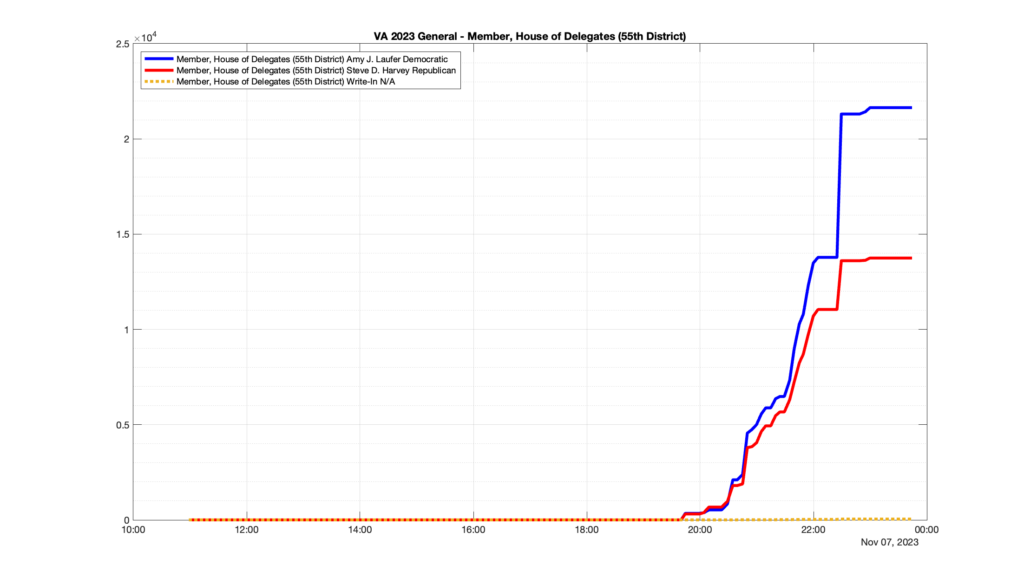
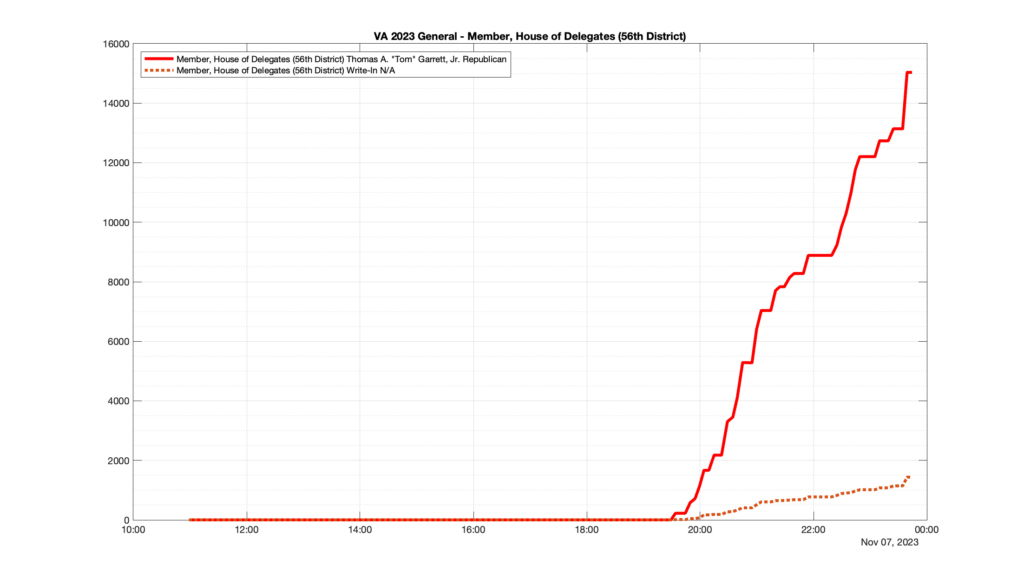
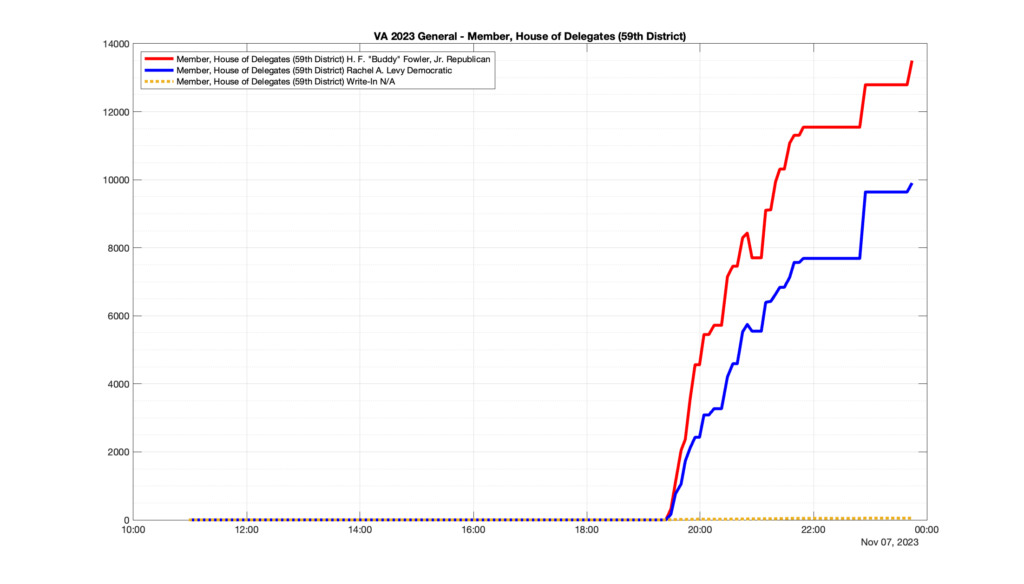
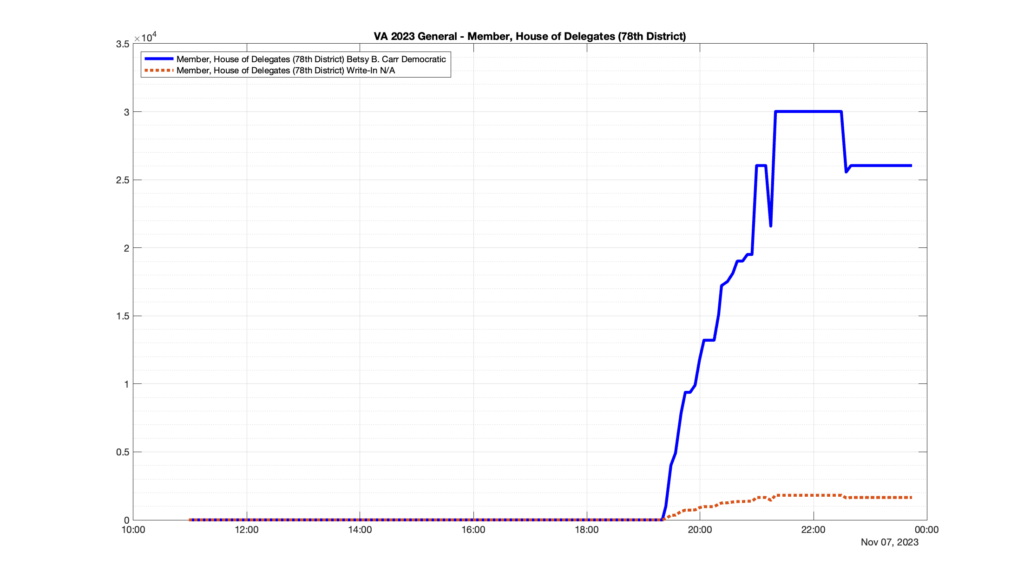
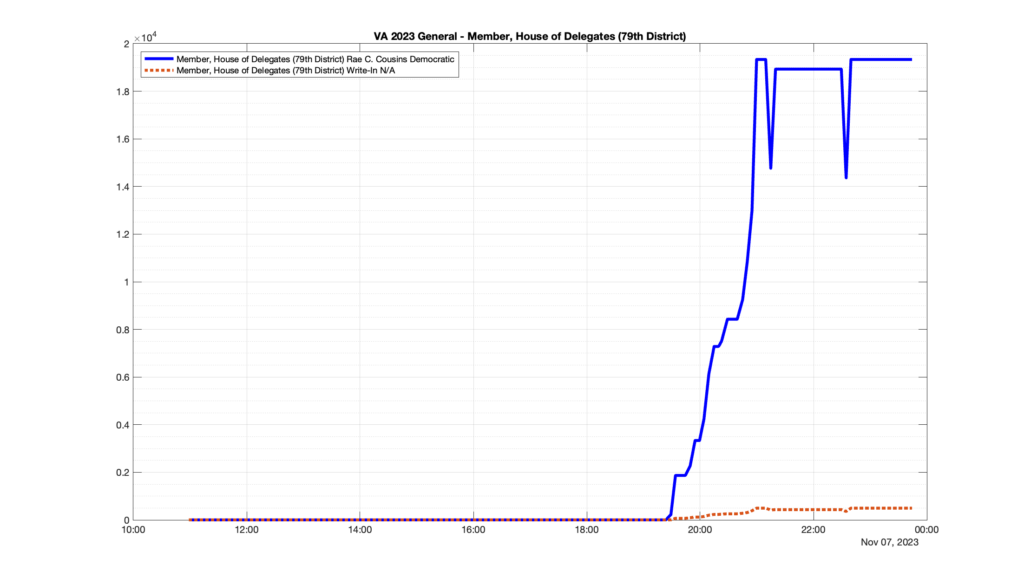
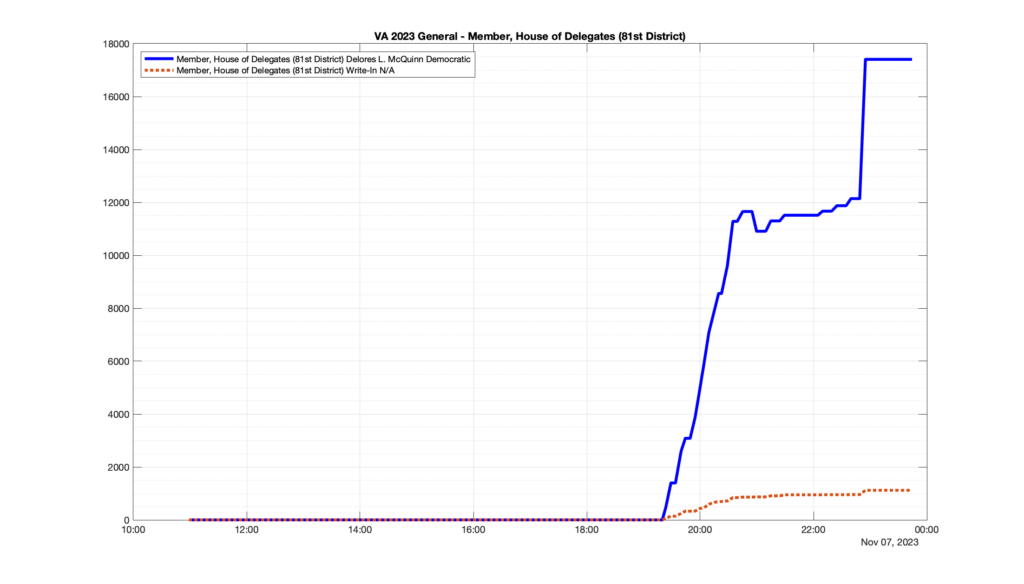
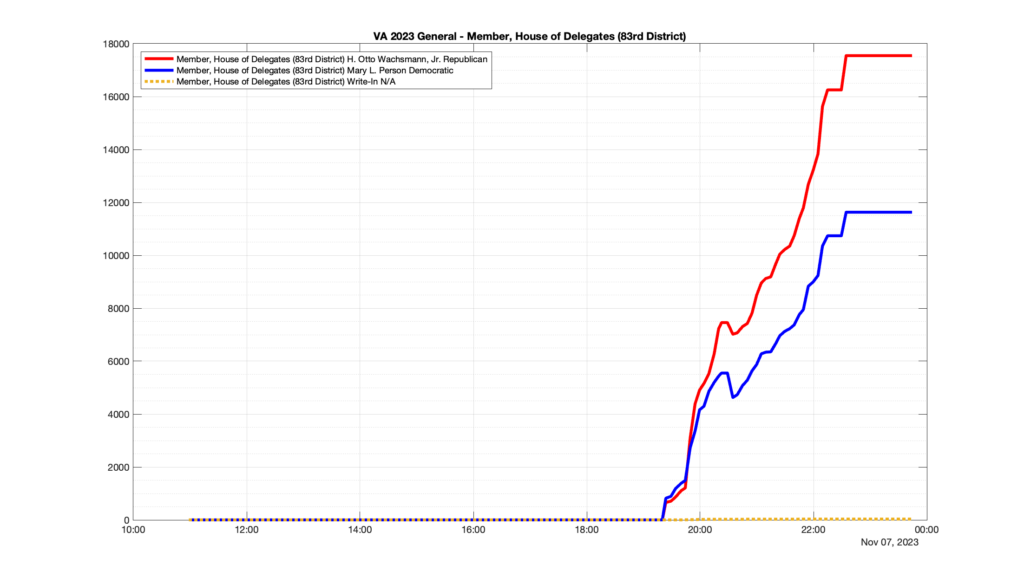
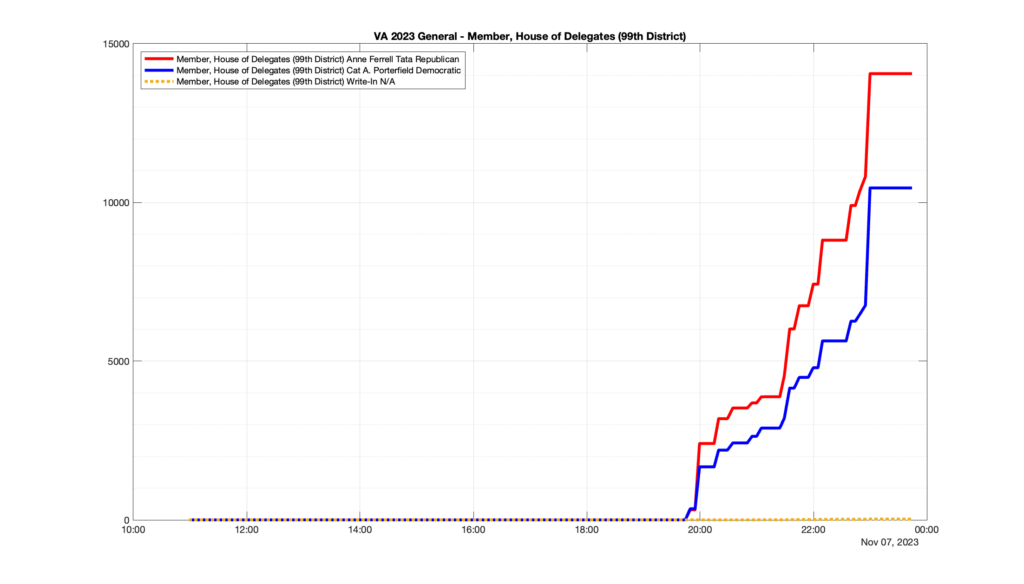
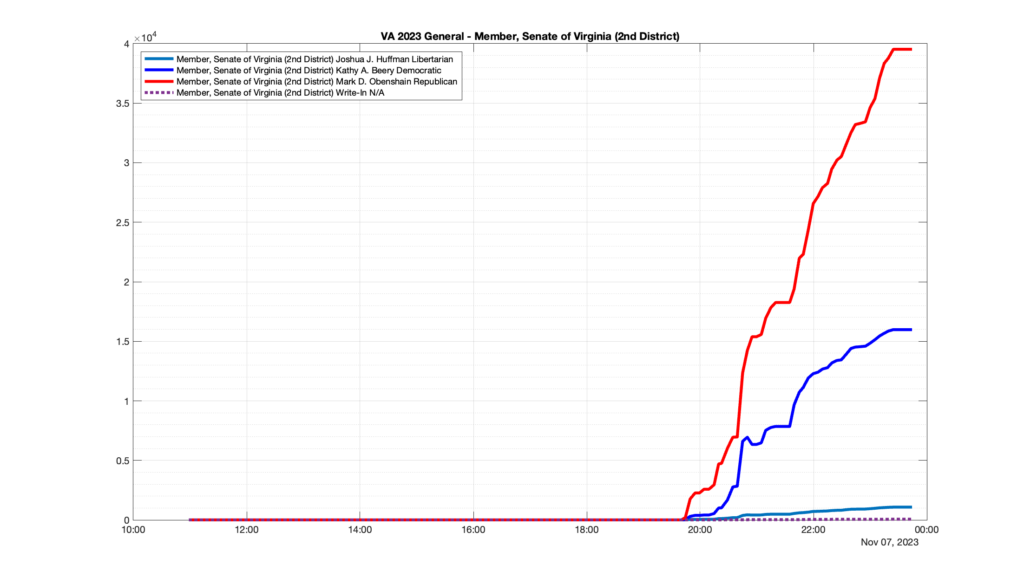
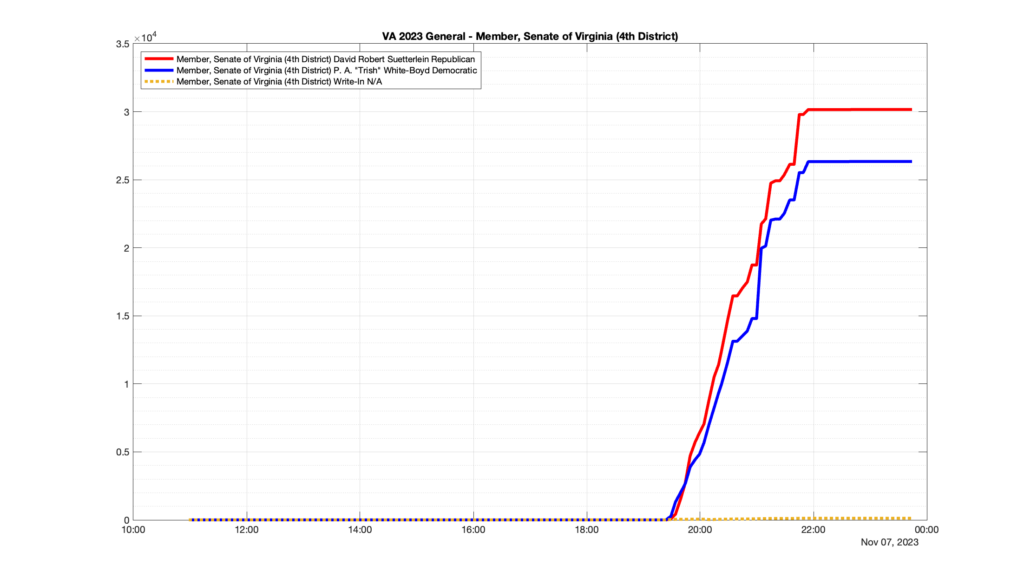
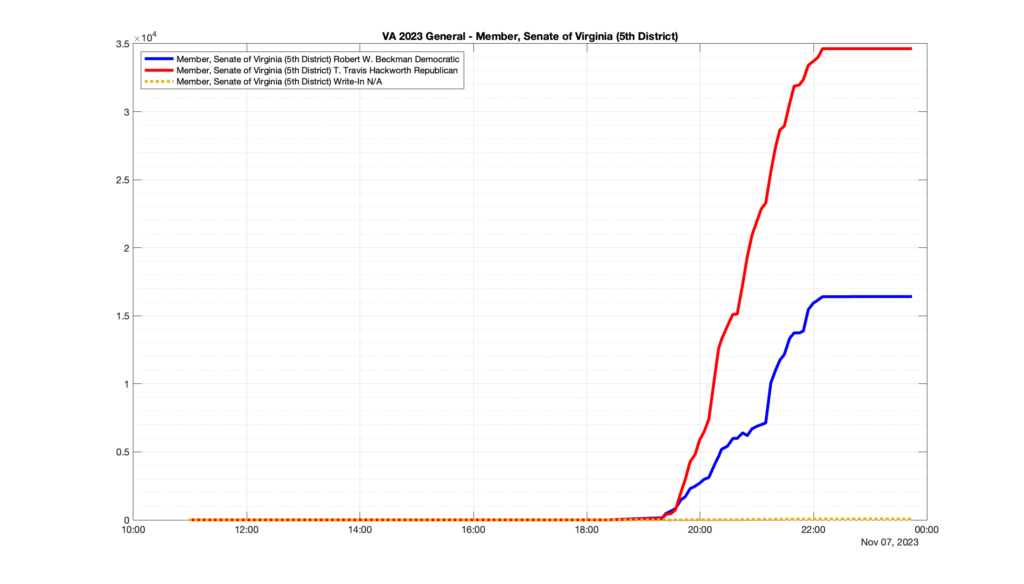
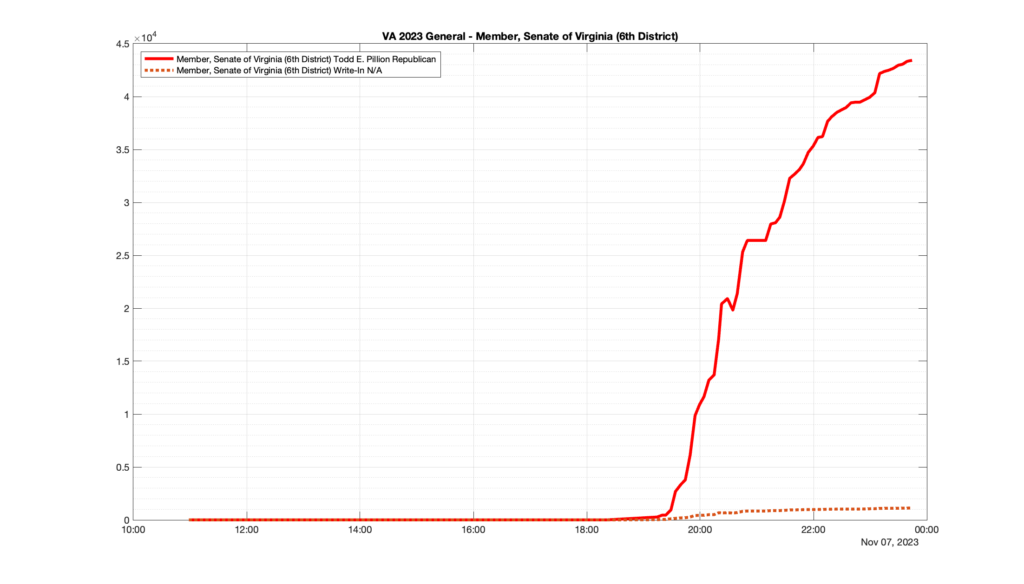
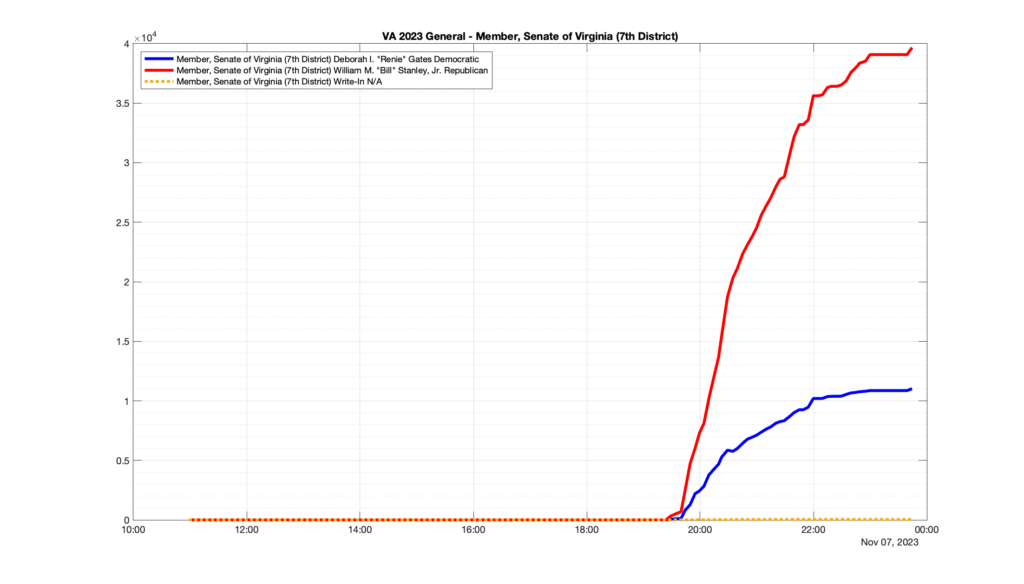
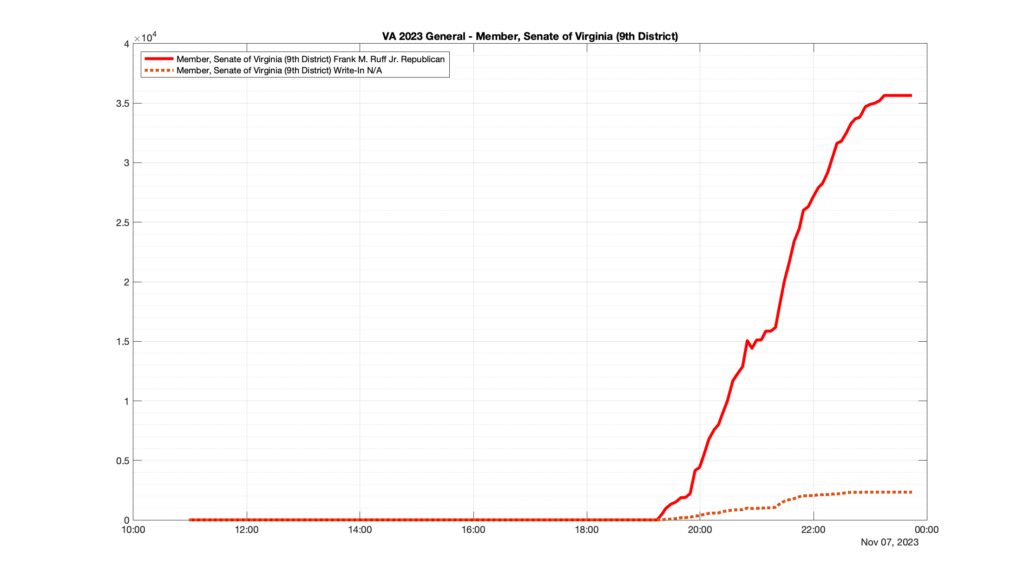
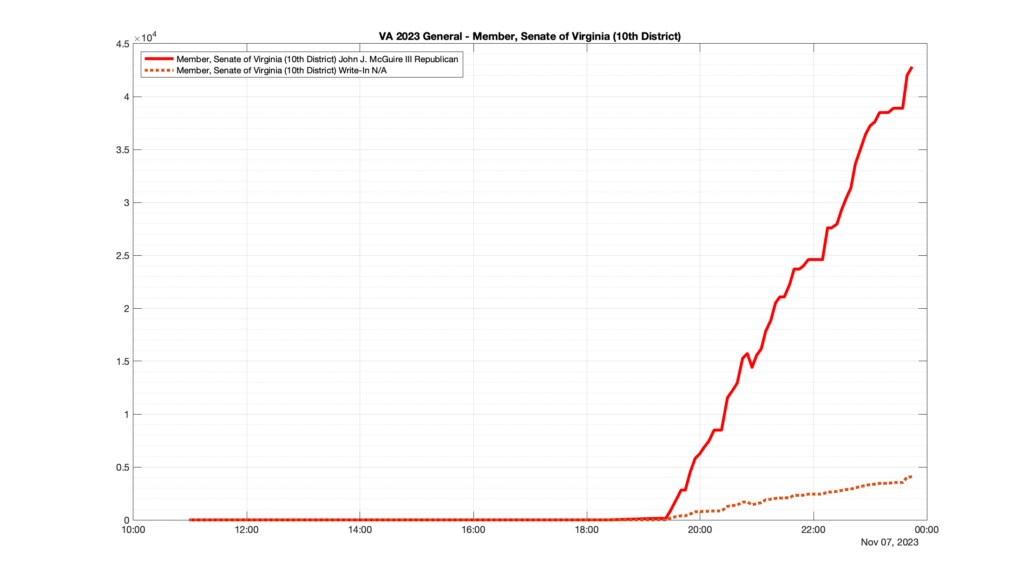
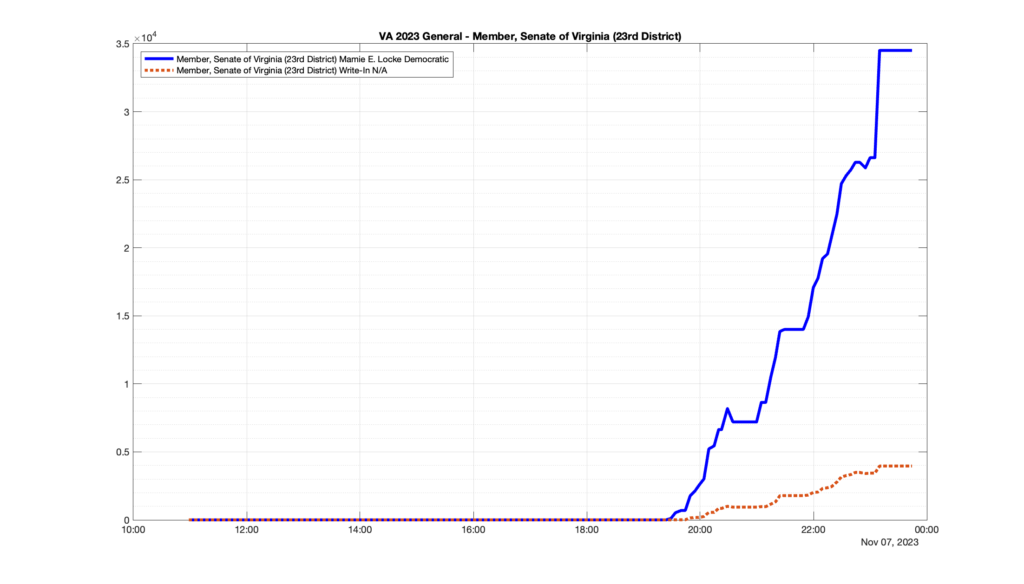
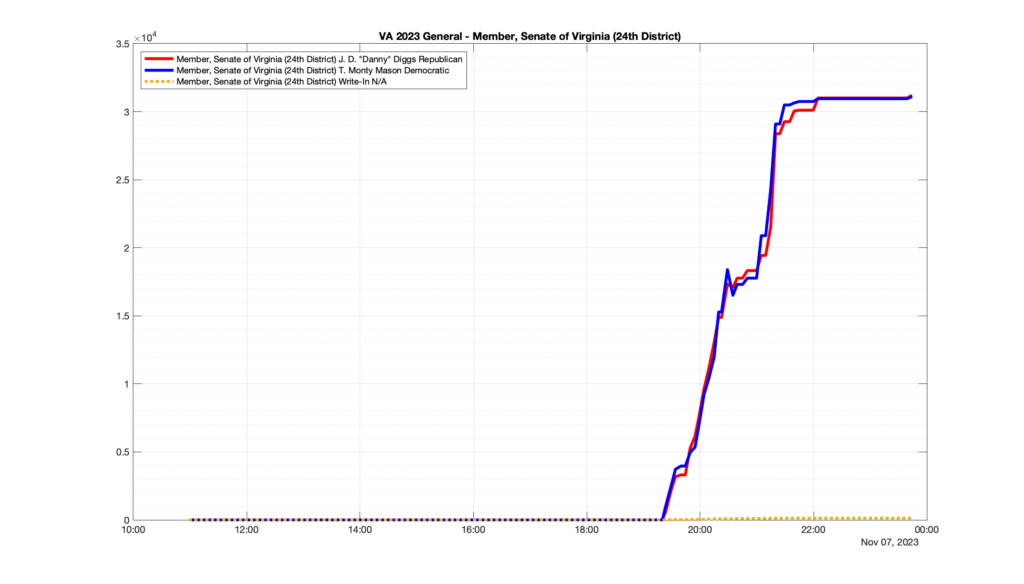
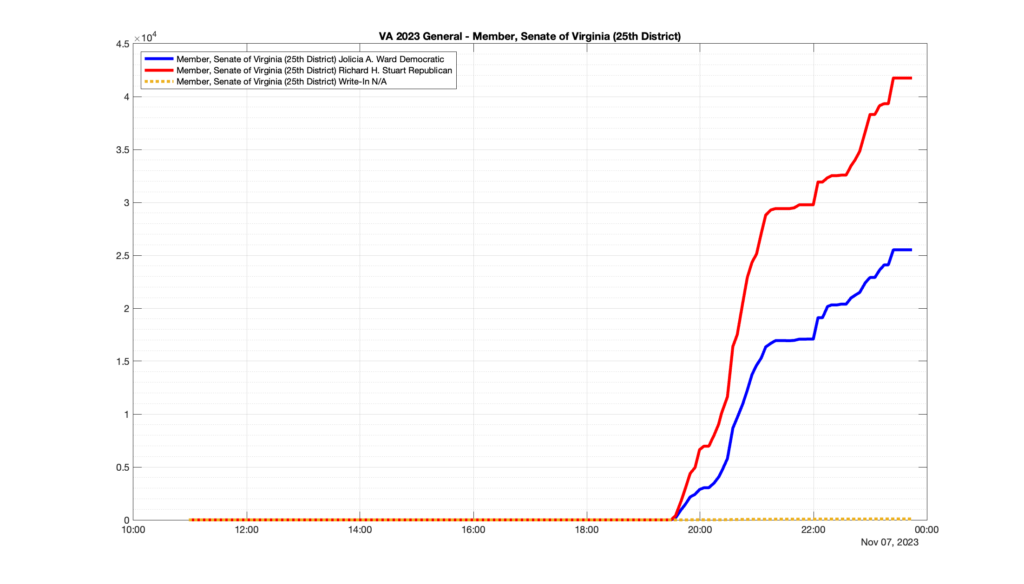
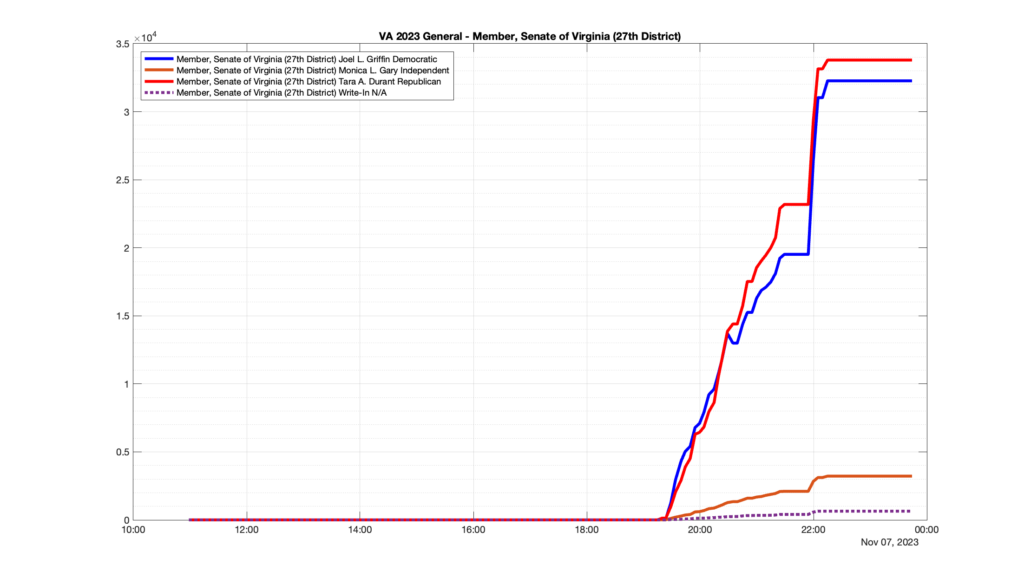
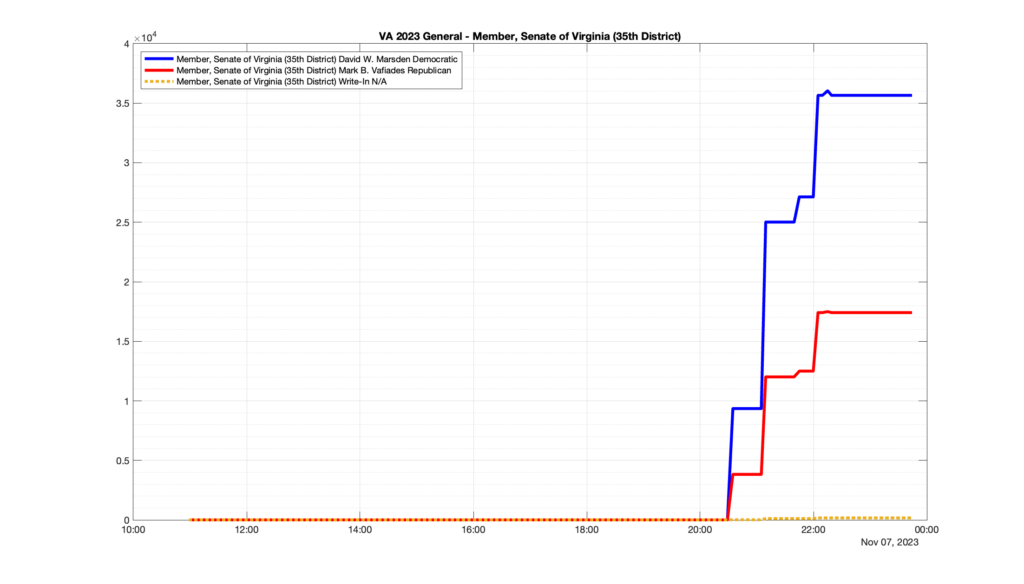
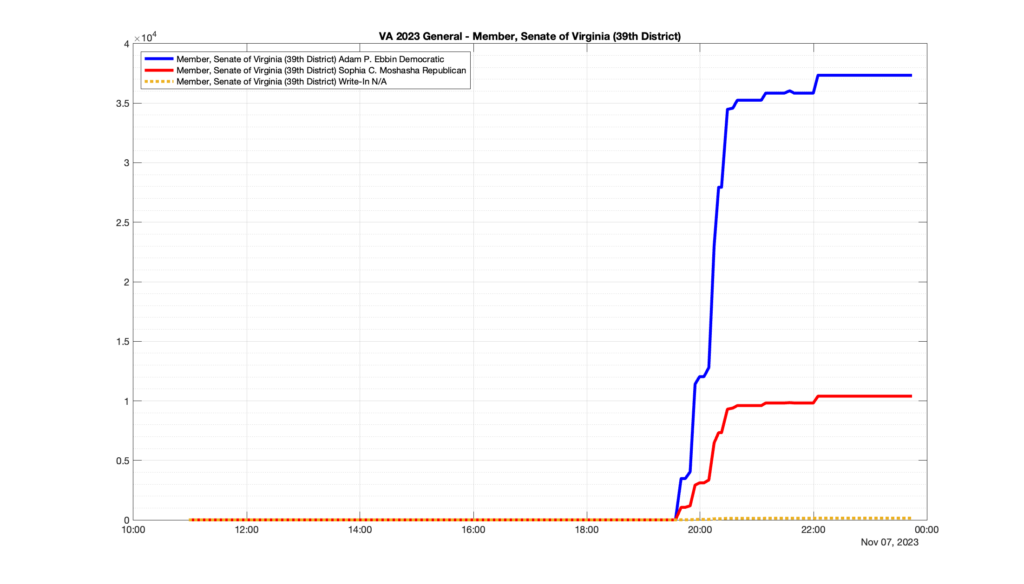
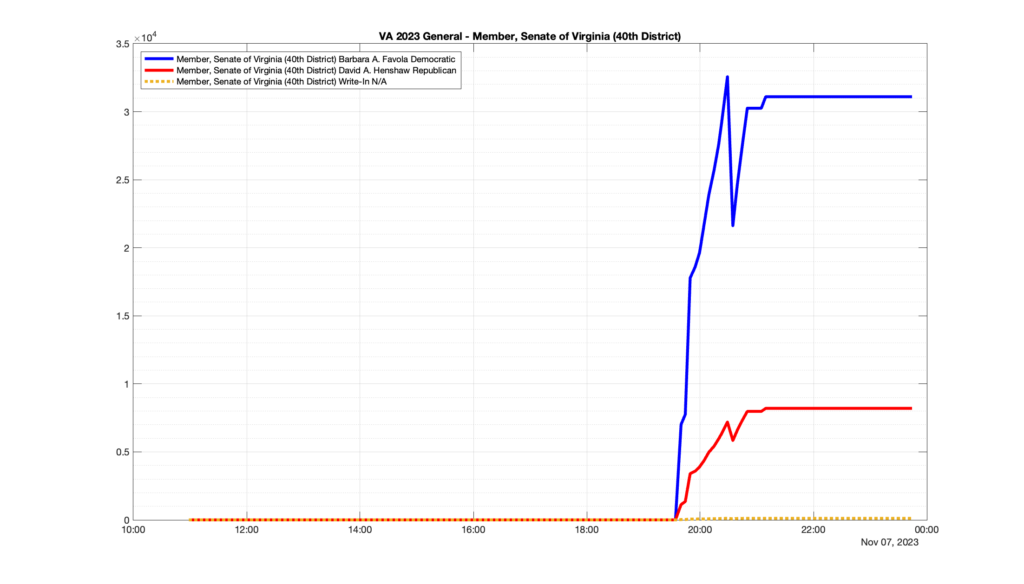
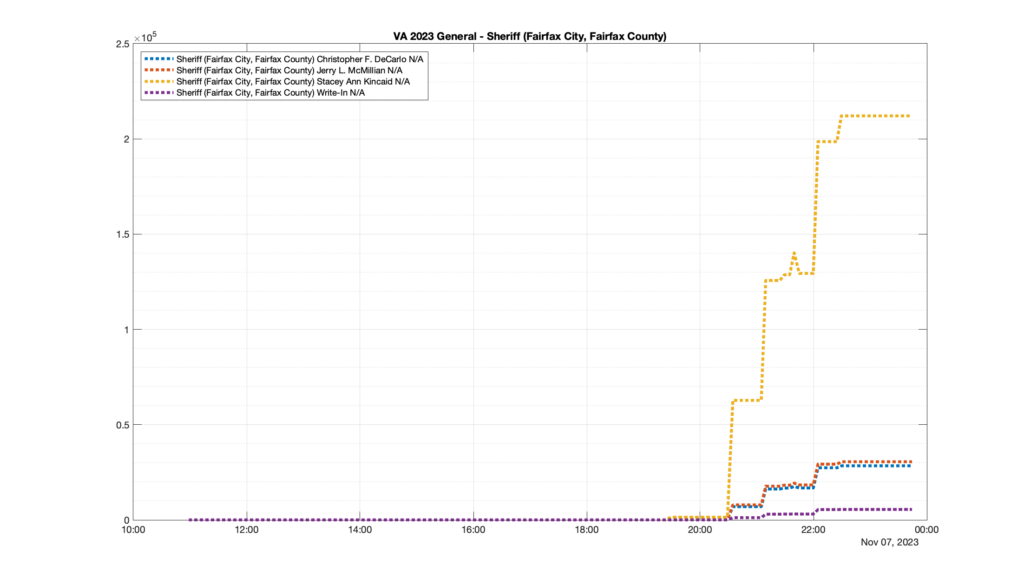
Well, election day came and went and everyone was glued to the internet to find out the results.
I took the extra step of logging all of the election night return files posted by the VA department of elections (“ELECT”) at 5 minute increments, as I wanted to plot the results over time as the numbers came in.
I used a simple wget script to grab this file once every 5 minutes (approximately).
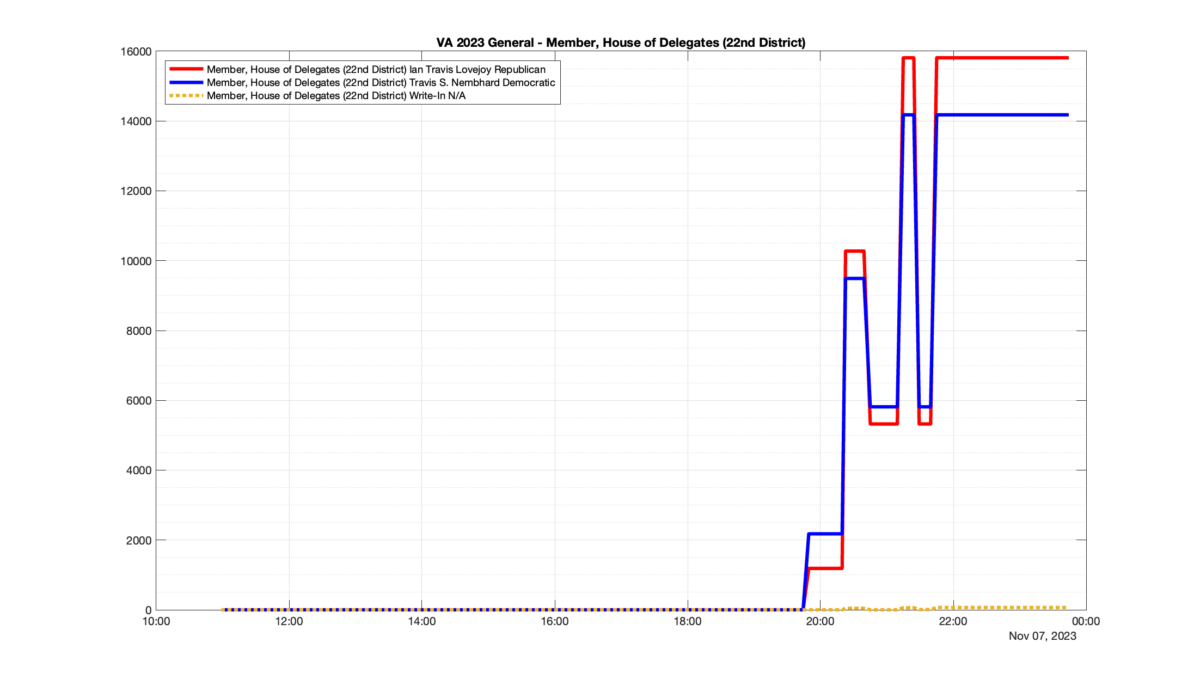
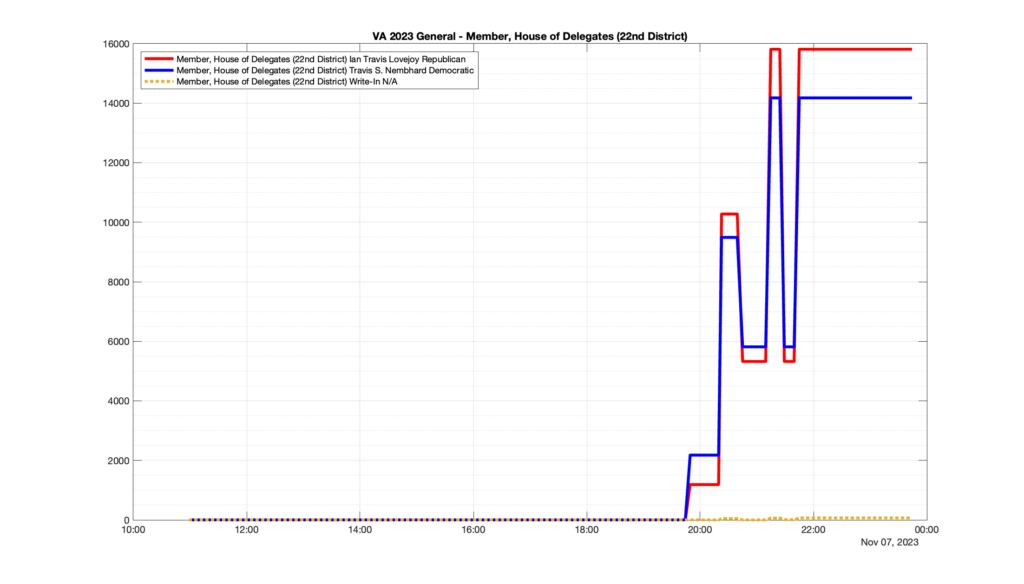
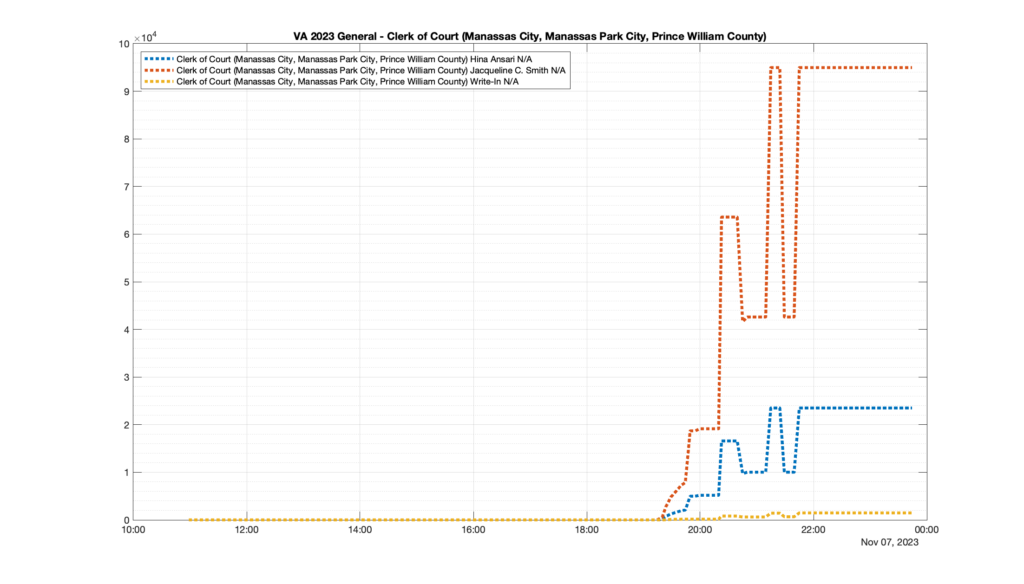
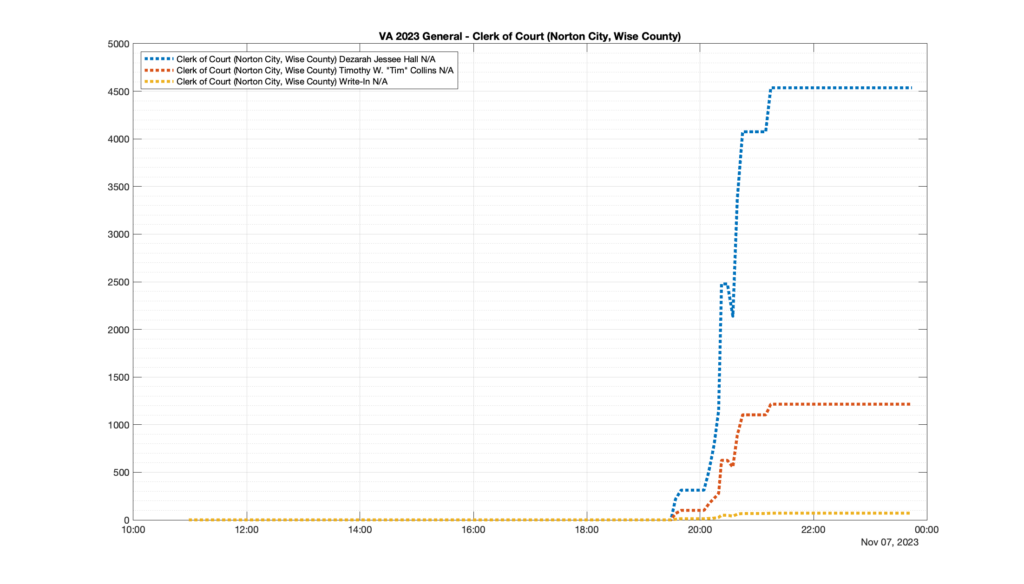
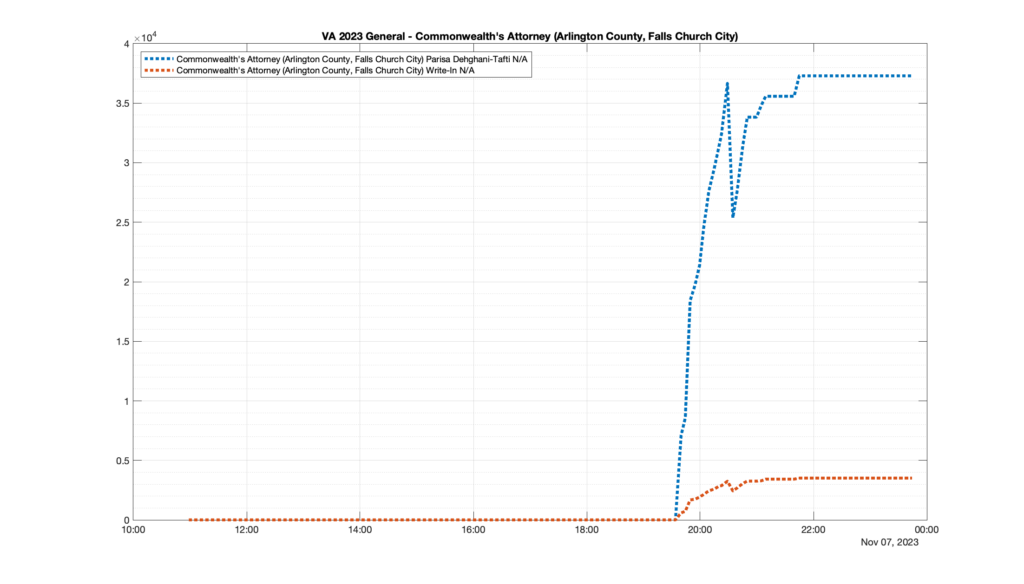
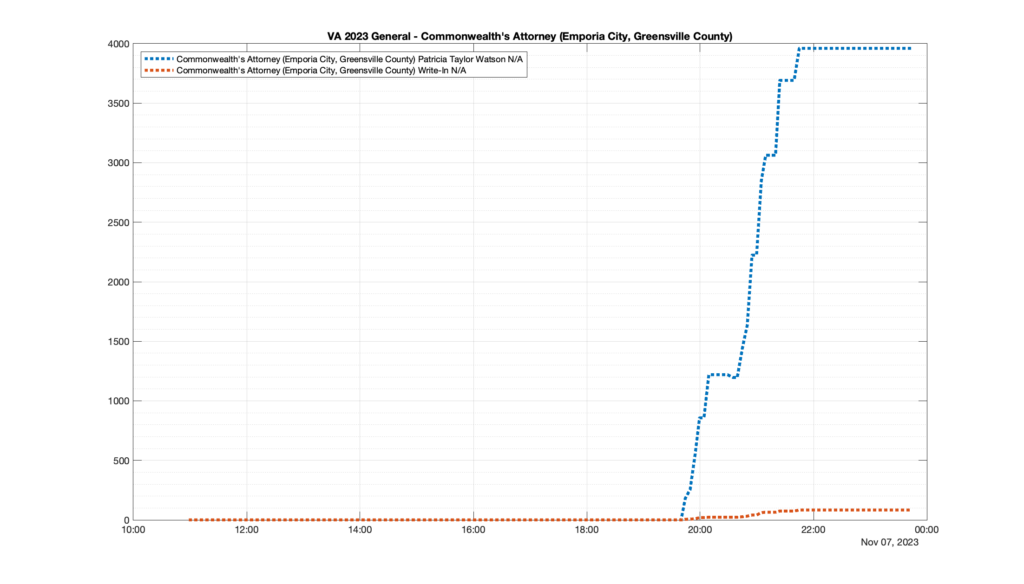
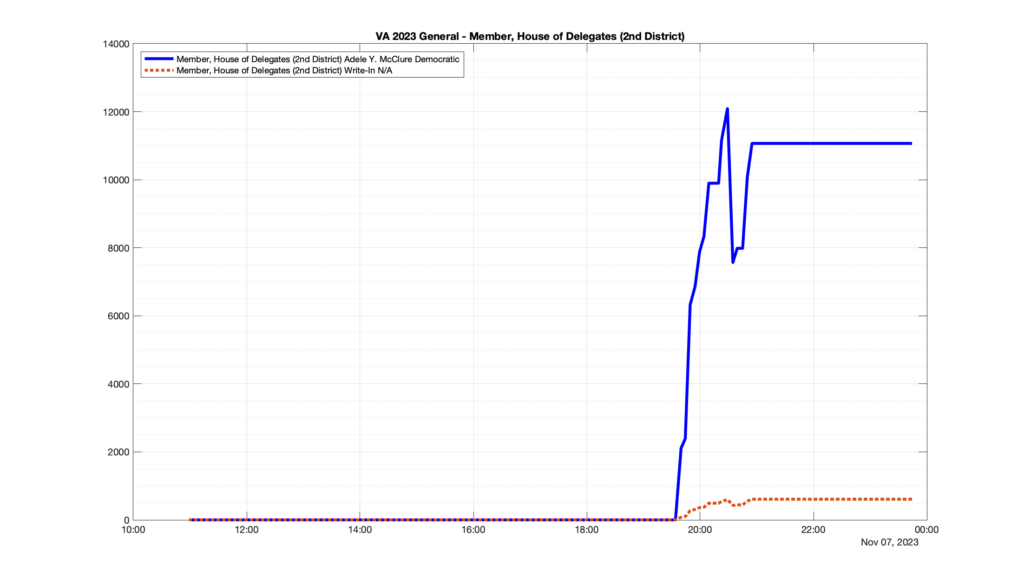
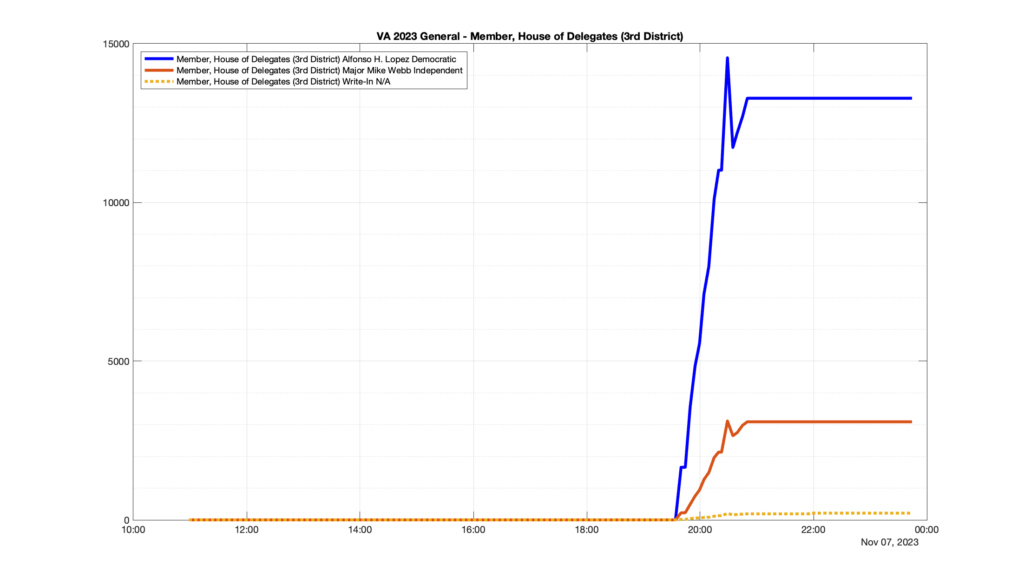
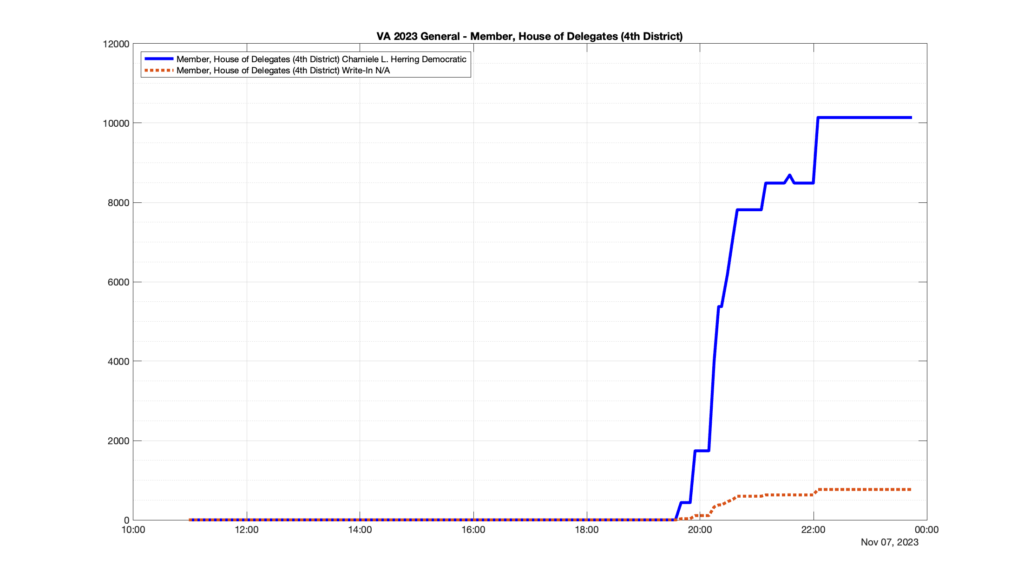
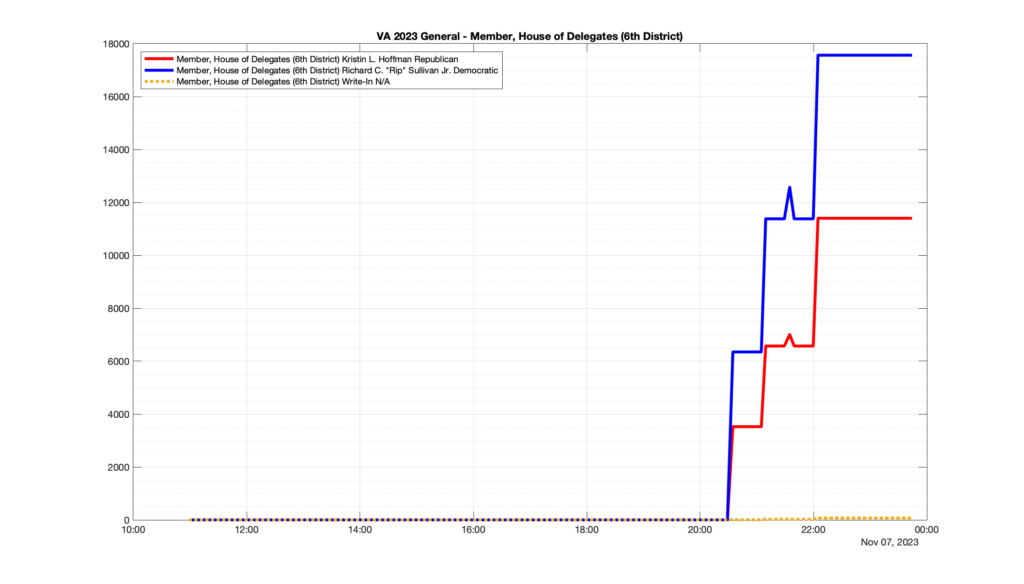
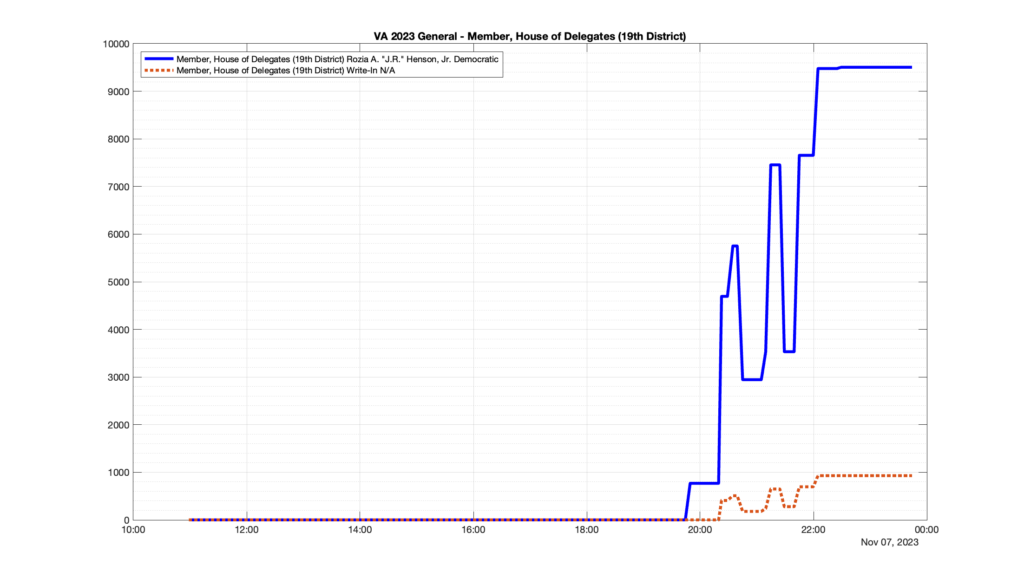
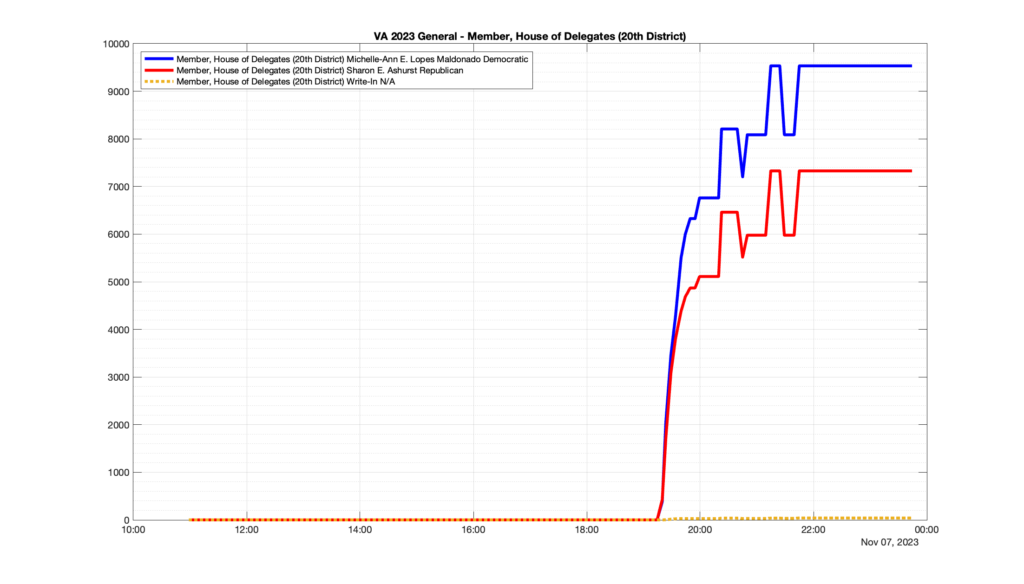
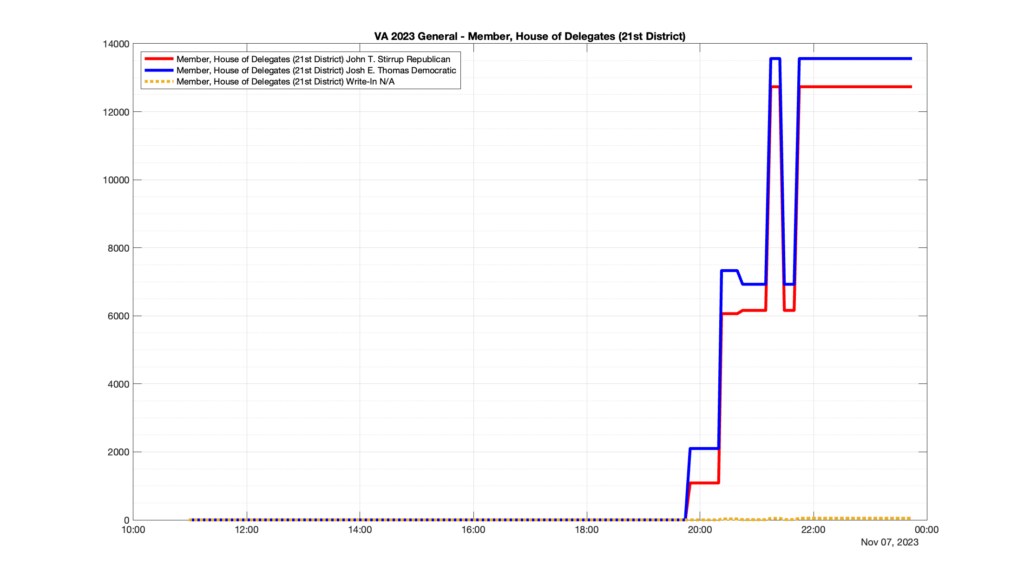
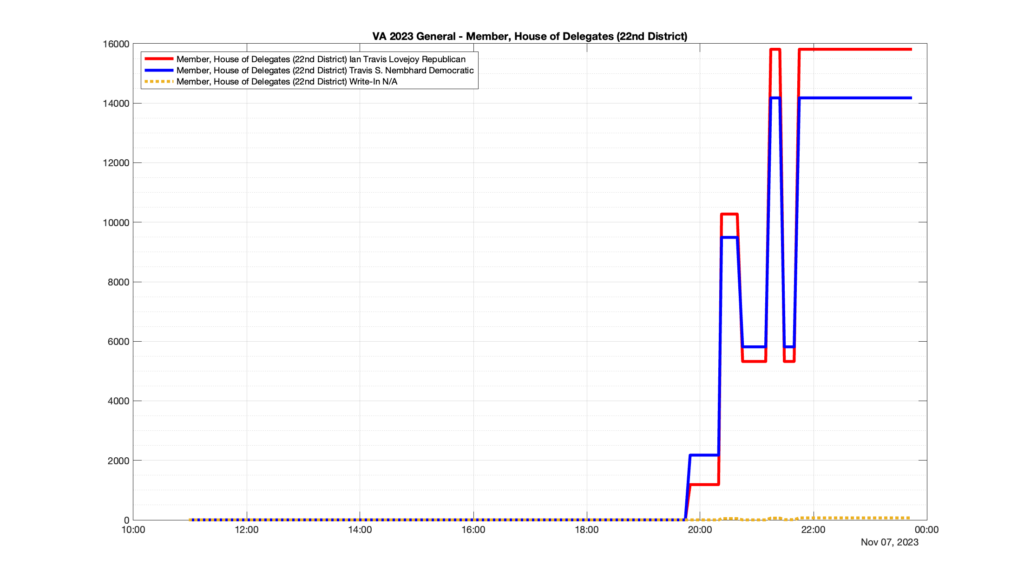
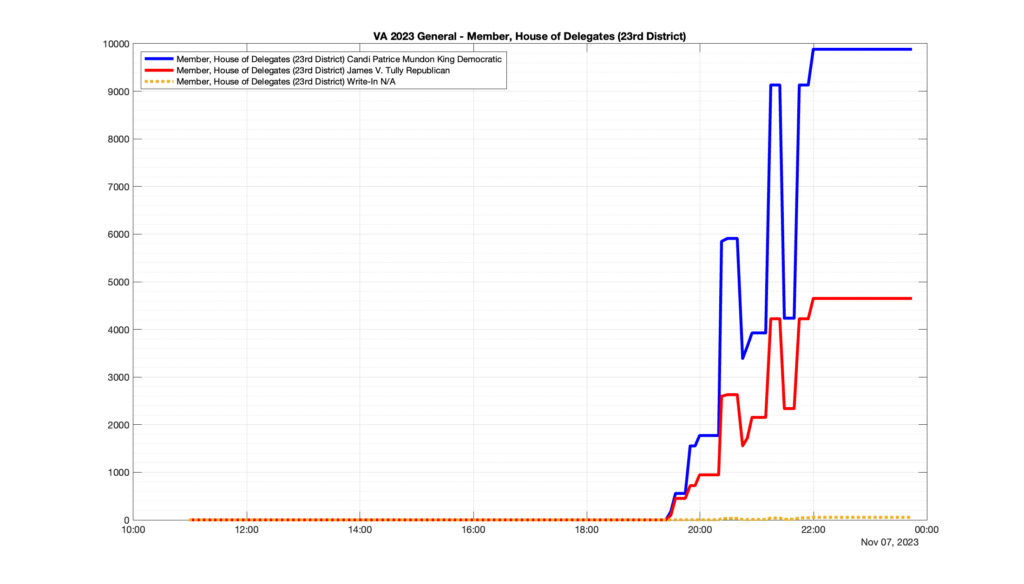
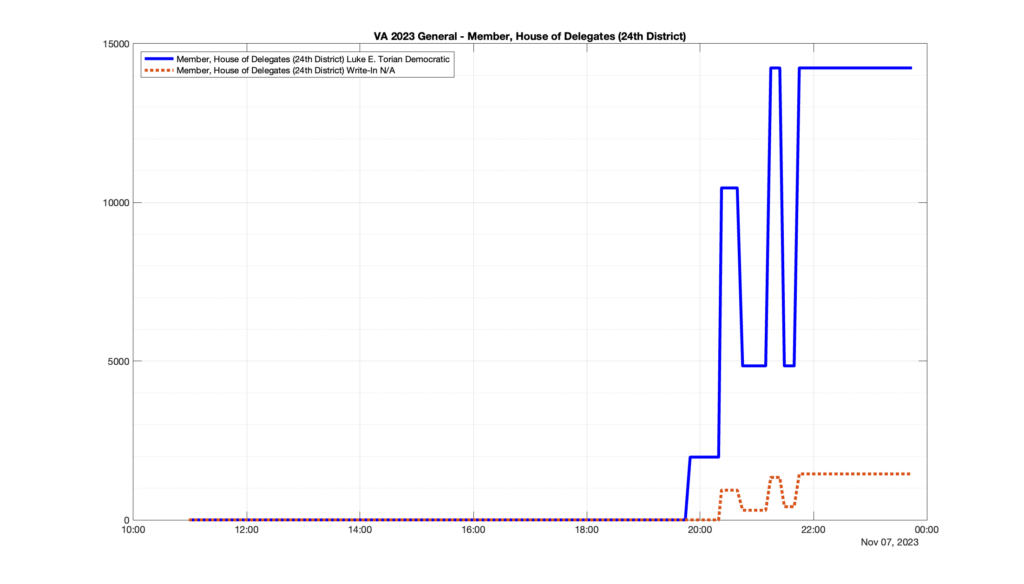
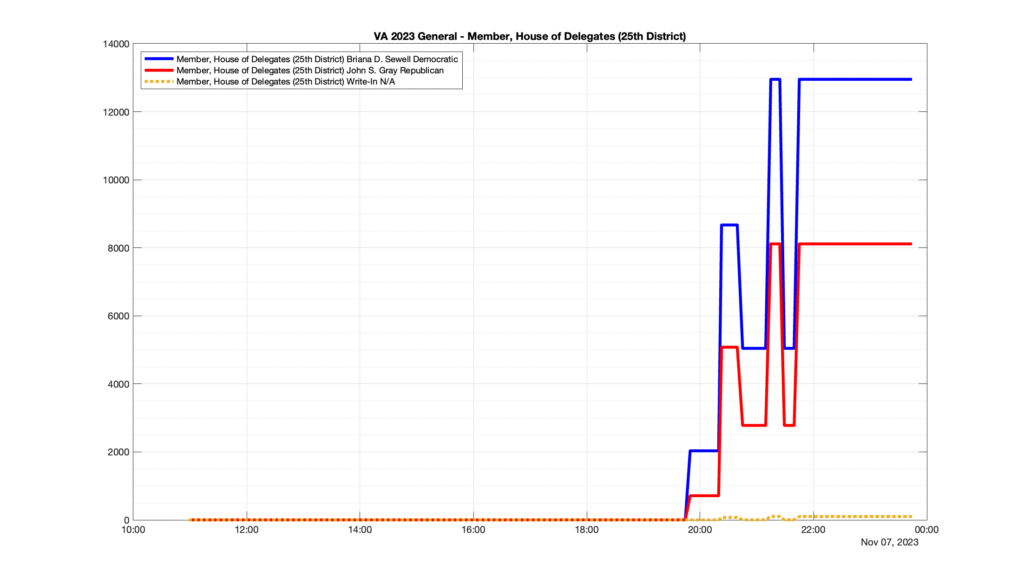
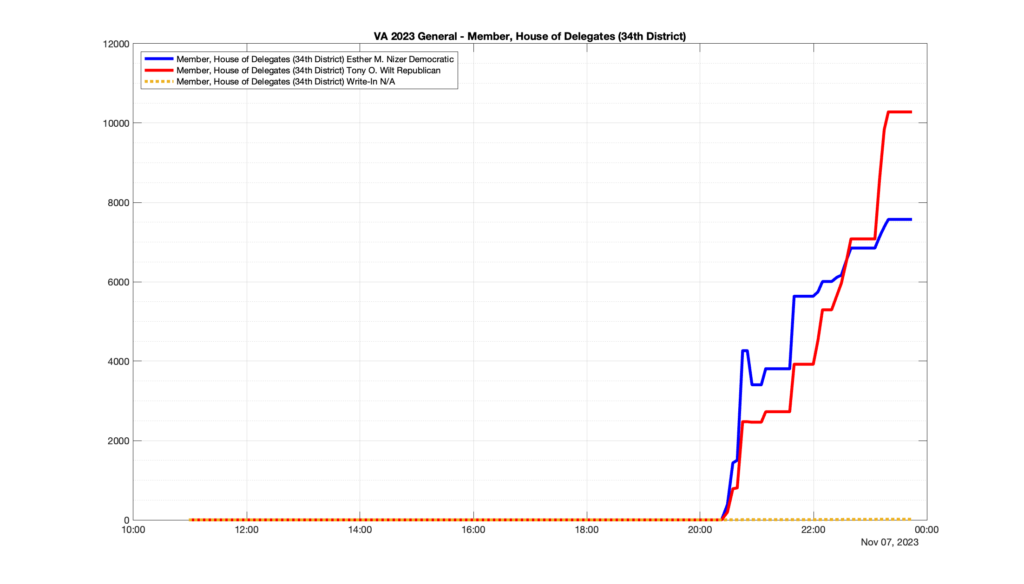
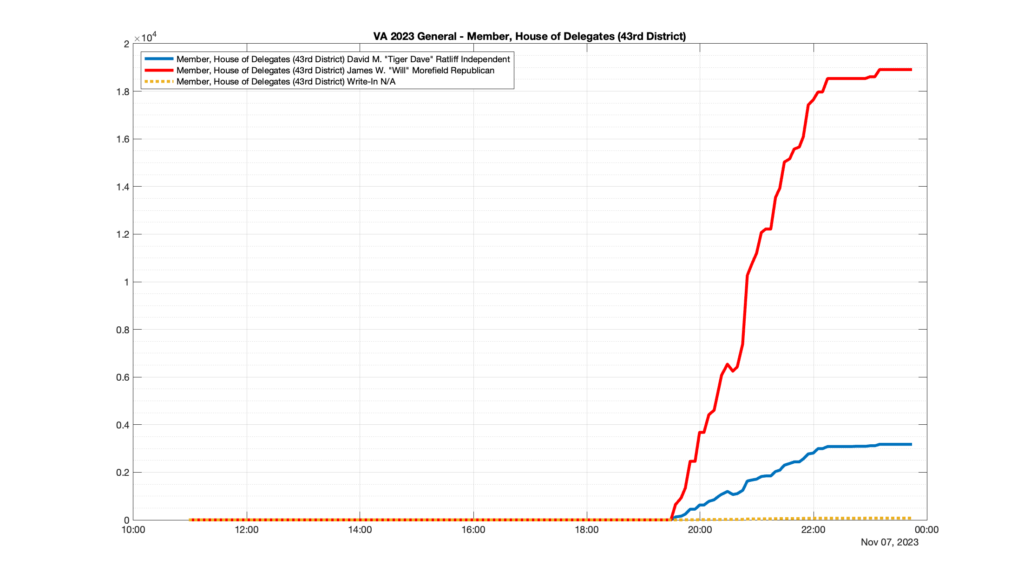
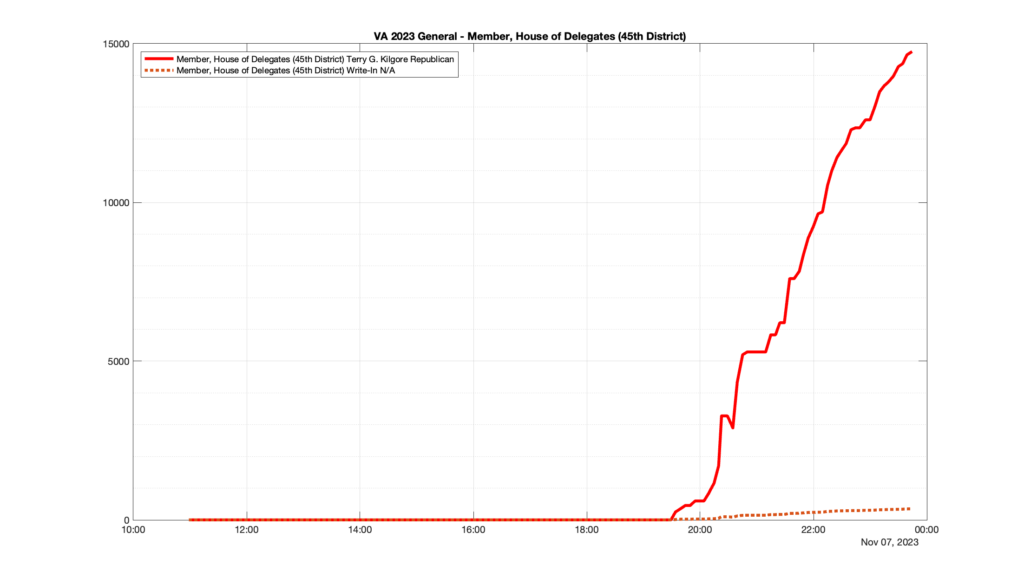
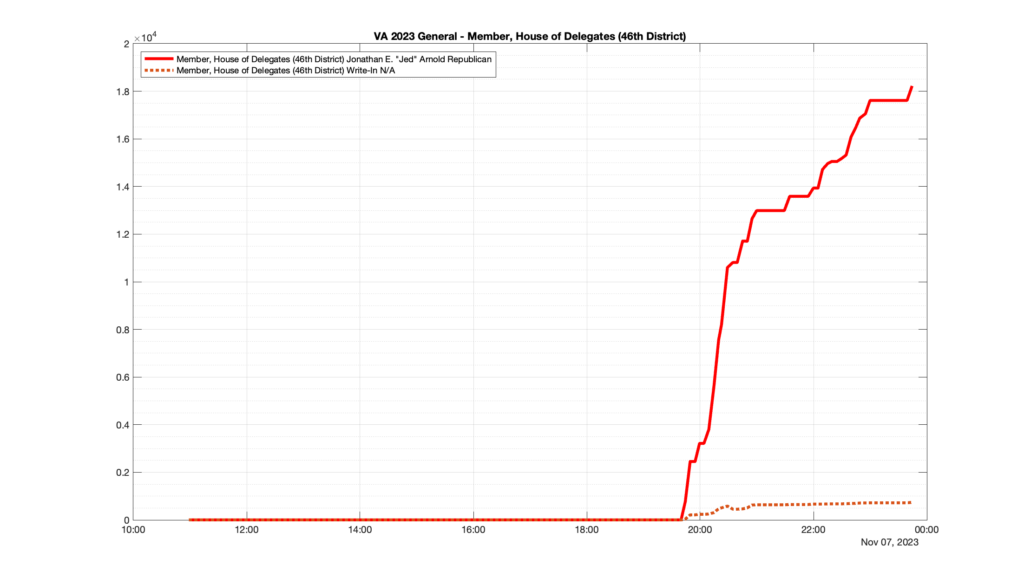
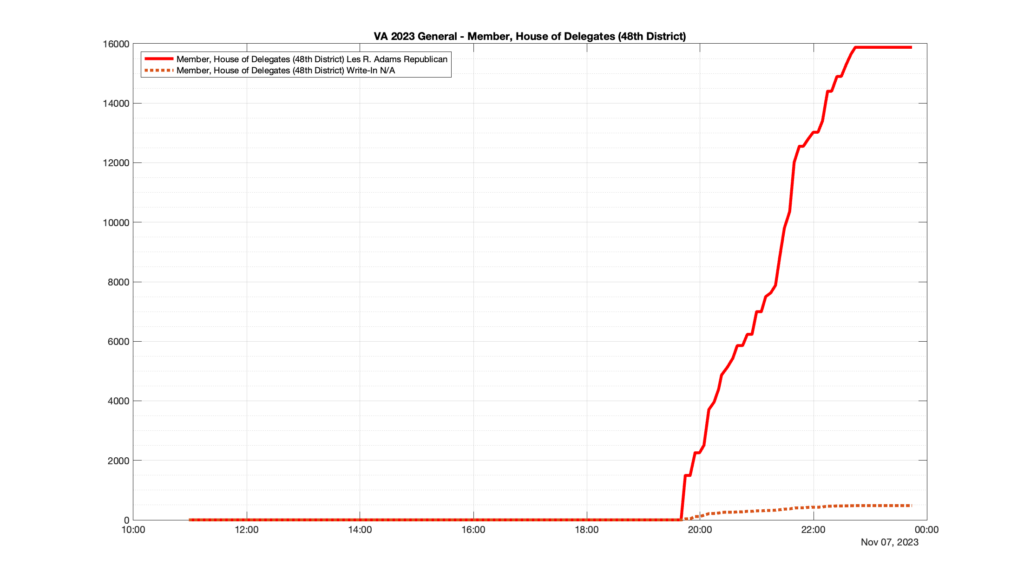
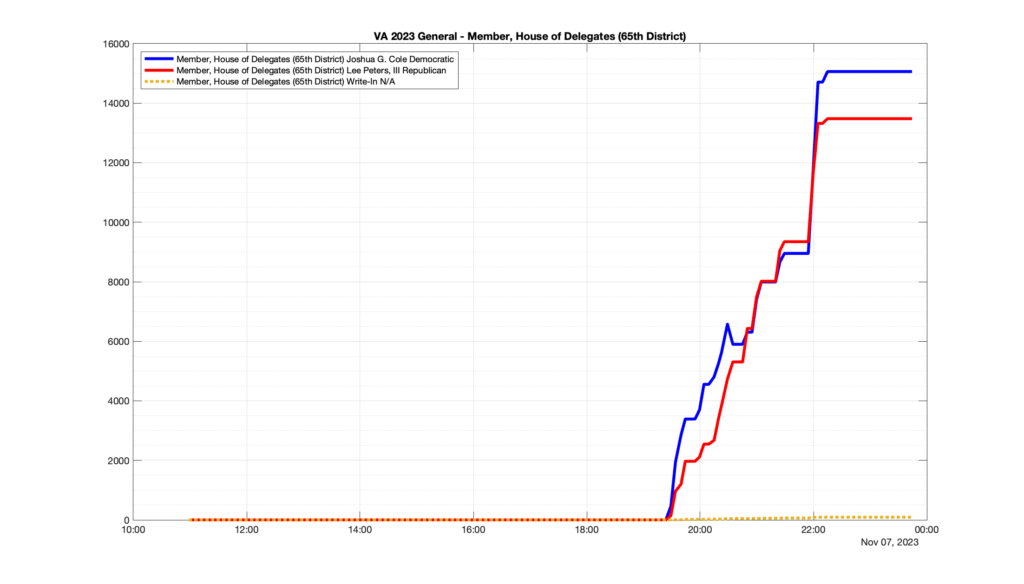
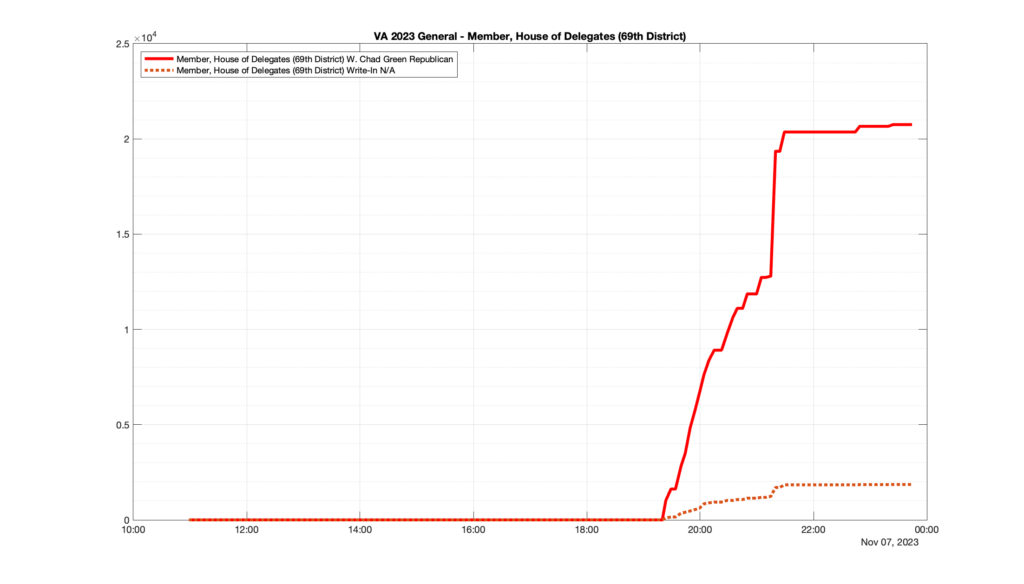
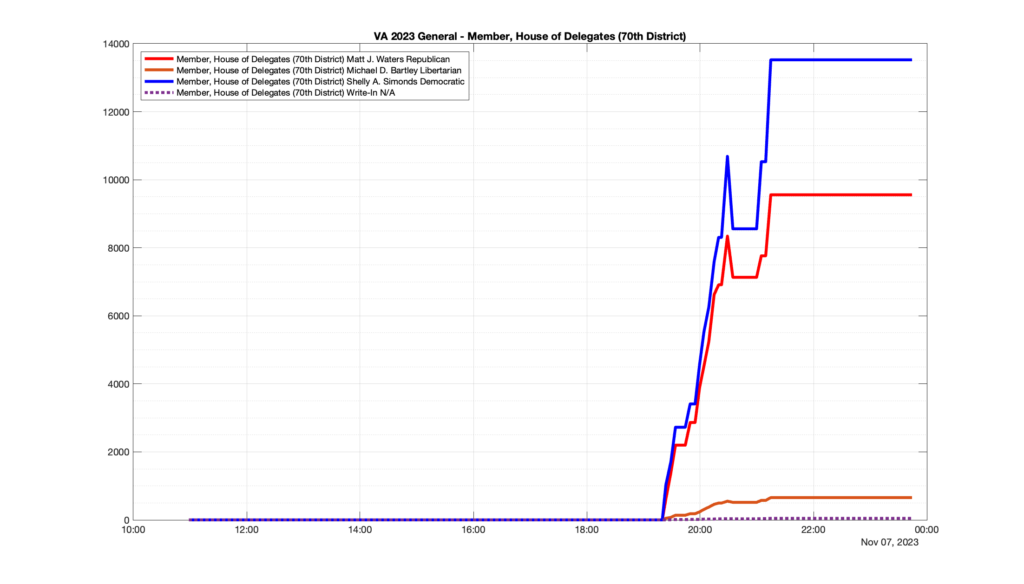
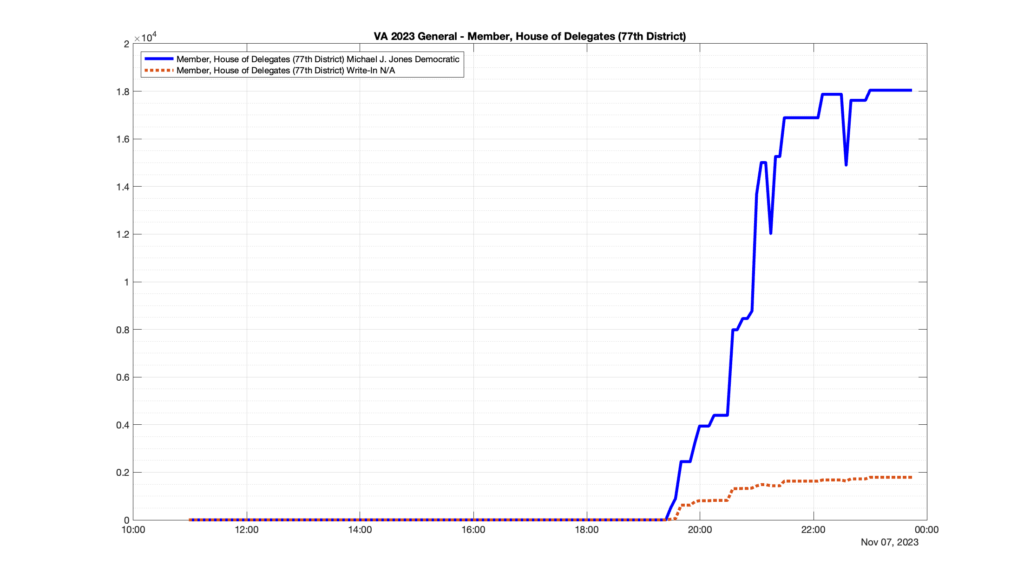
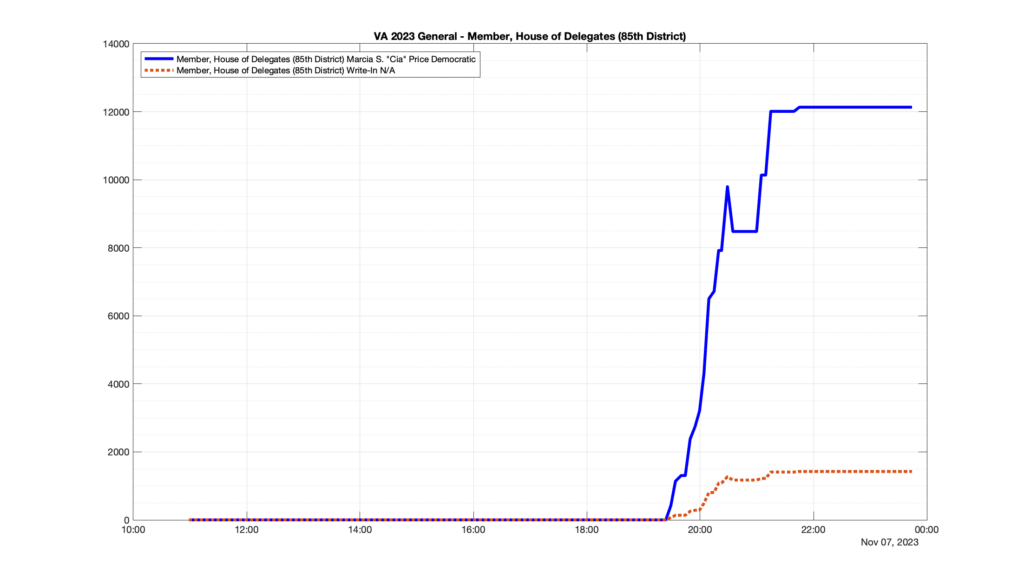
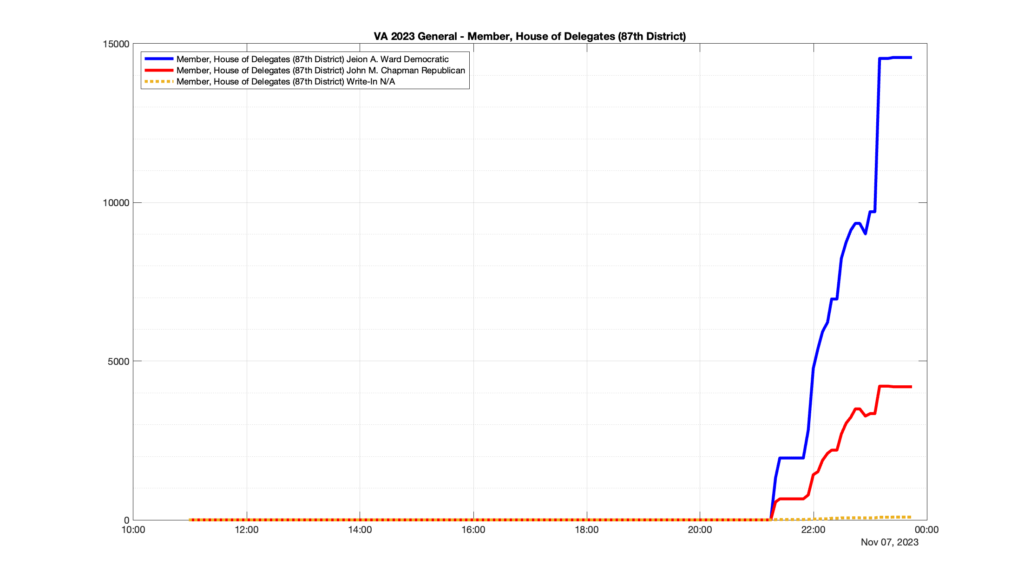
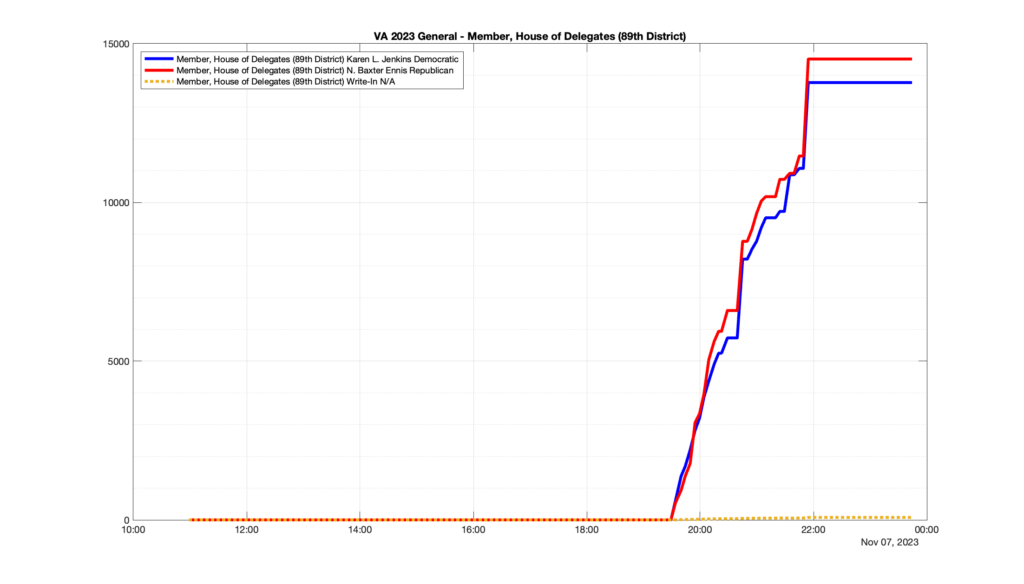
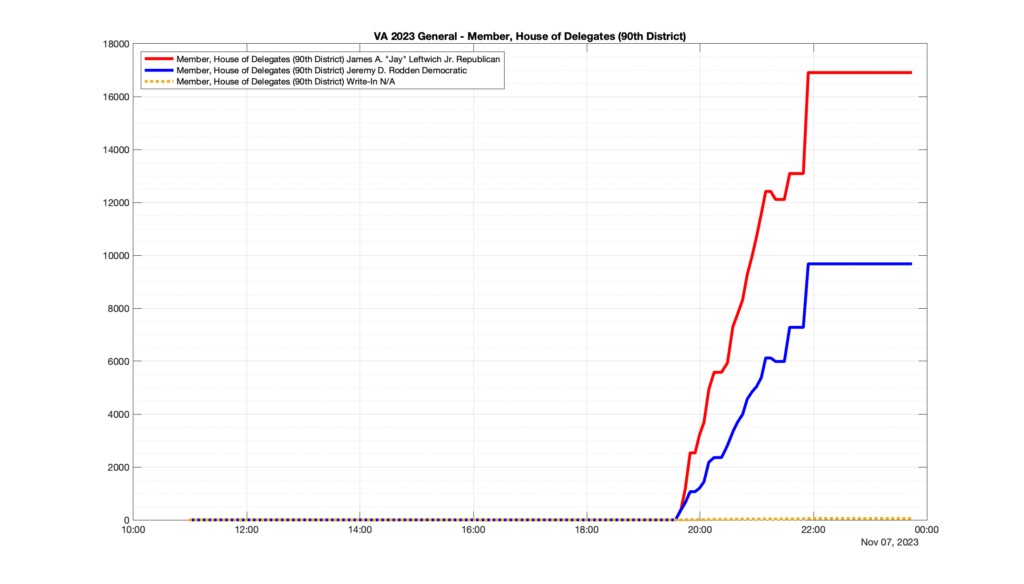
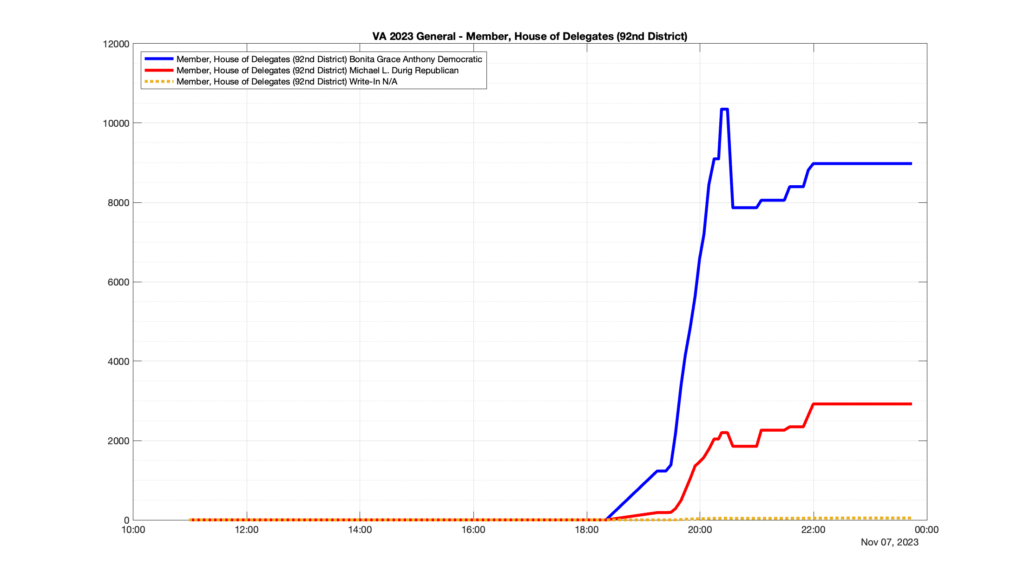
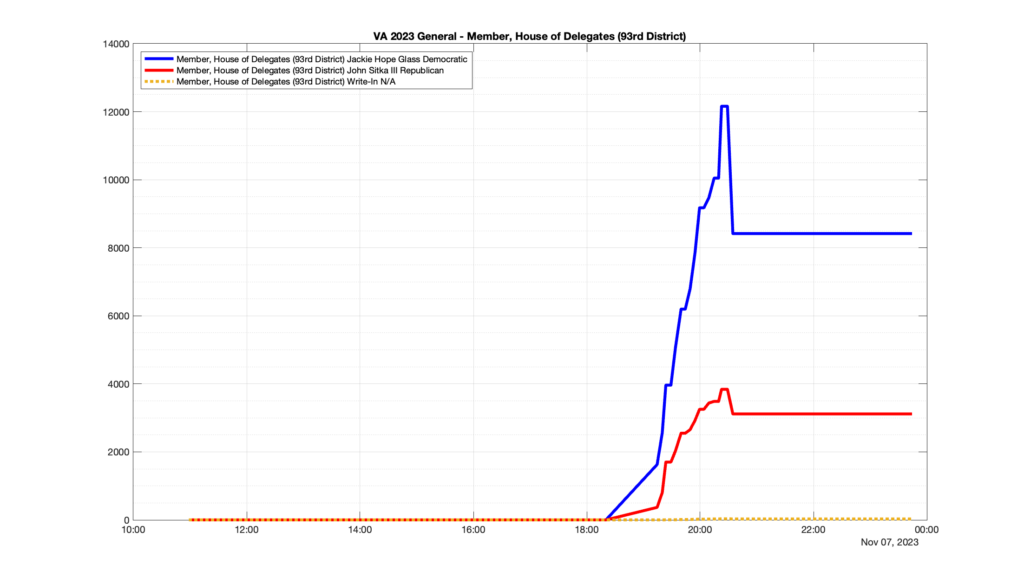
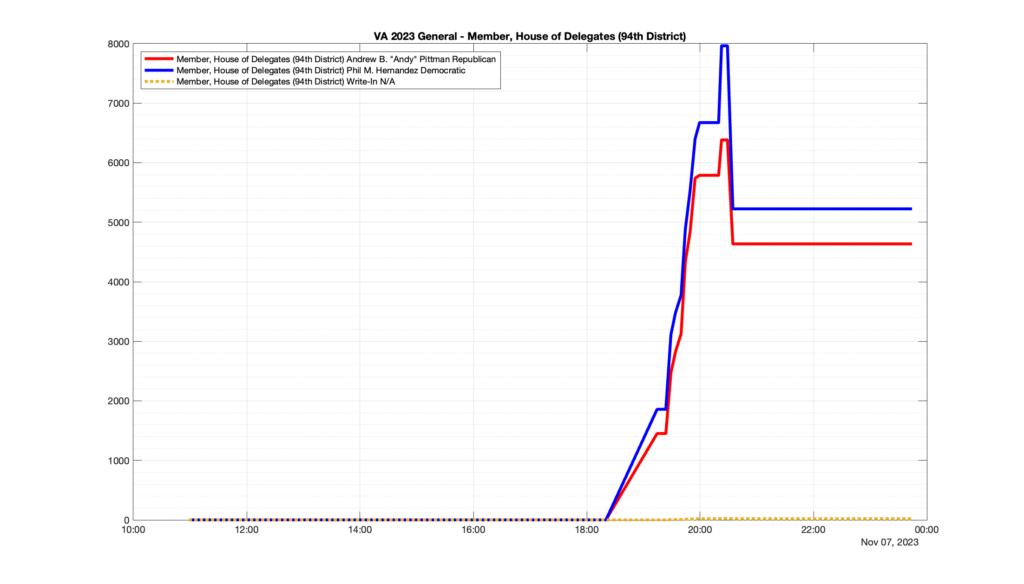
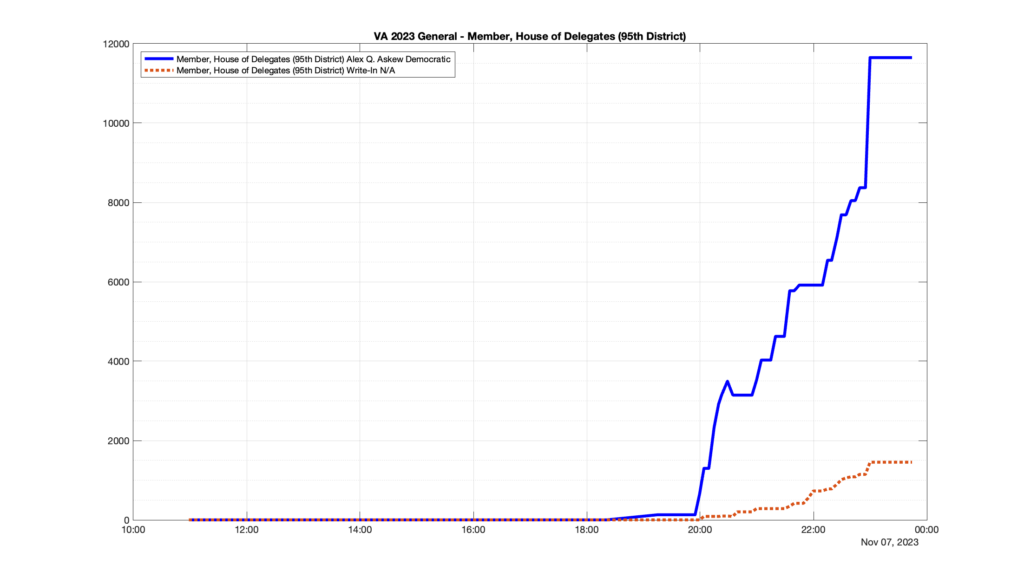
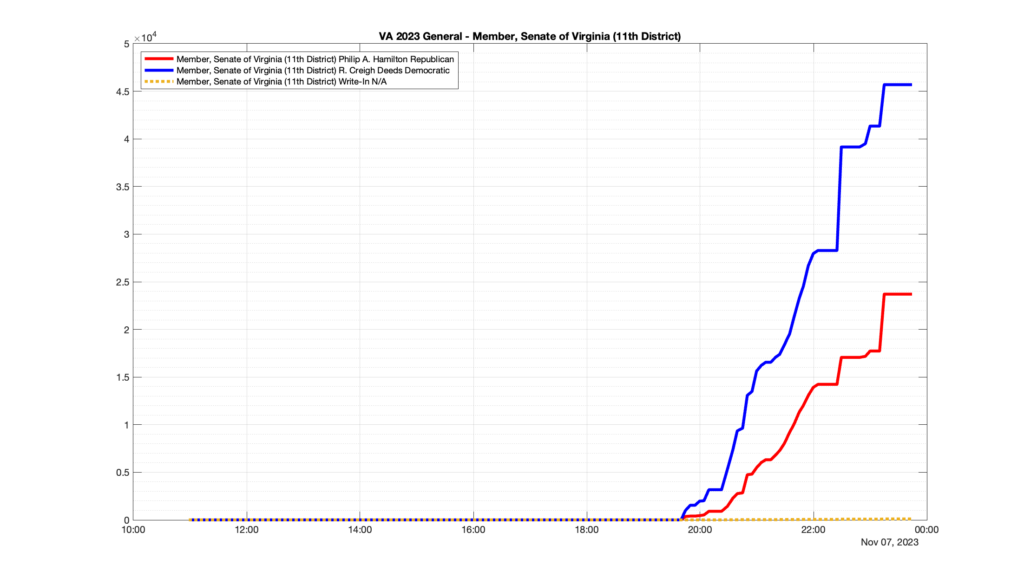
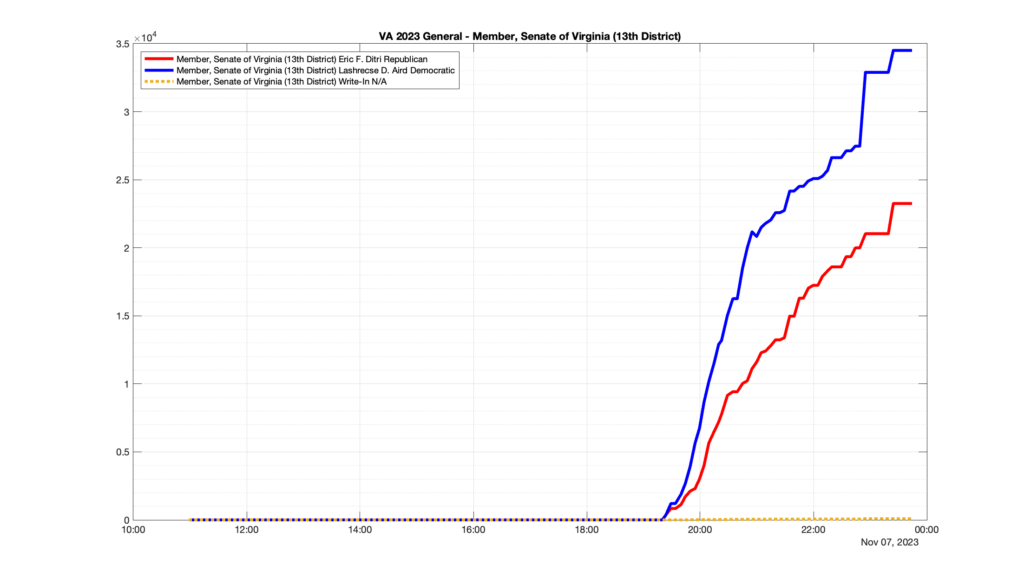
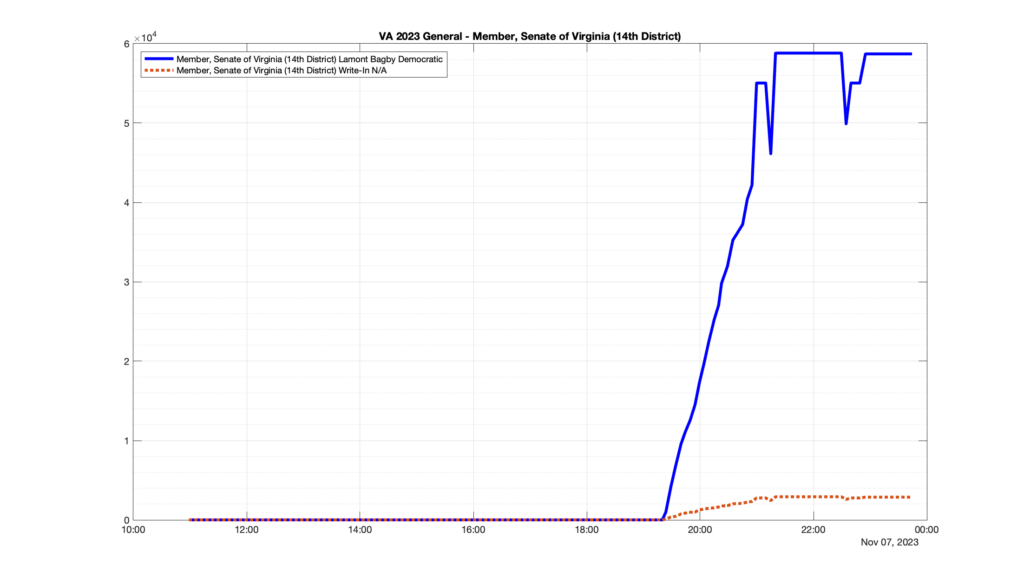
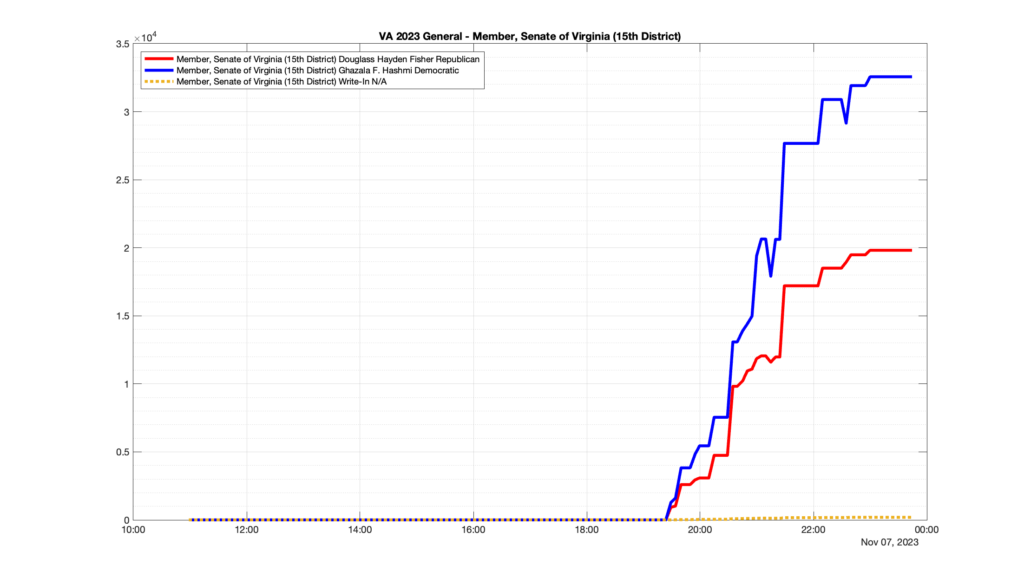
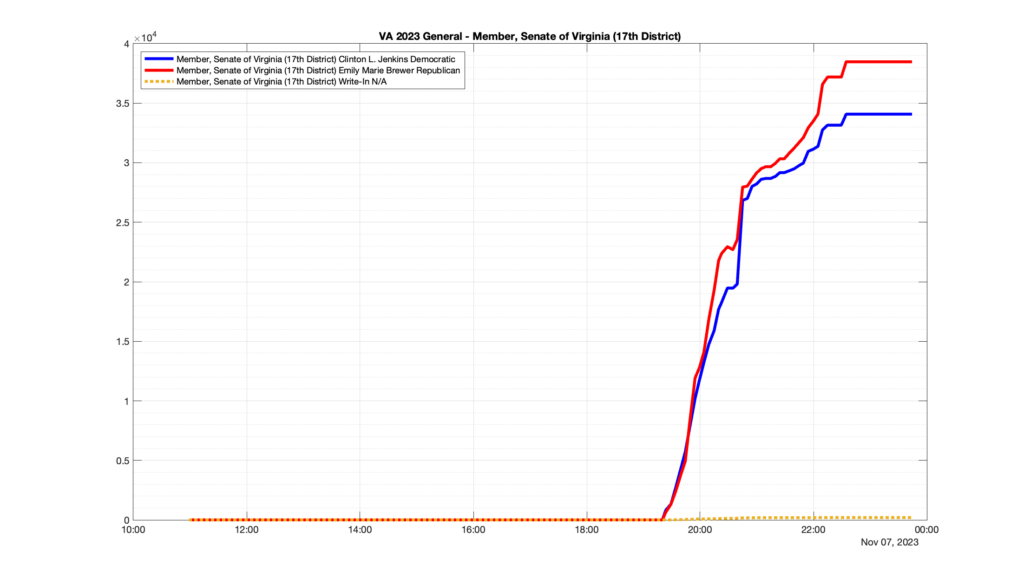
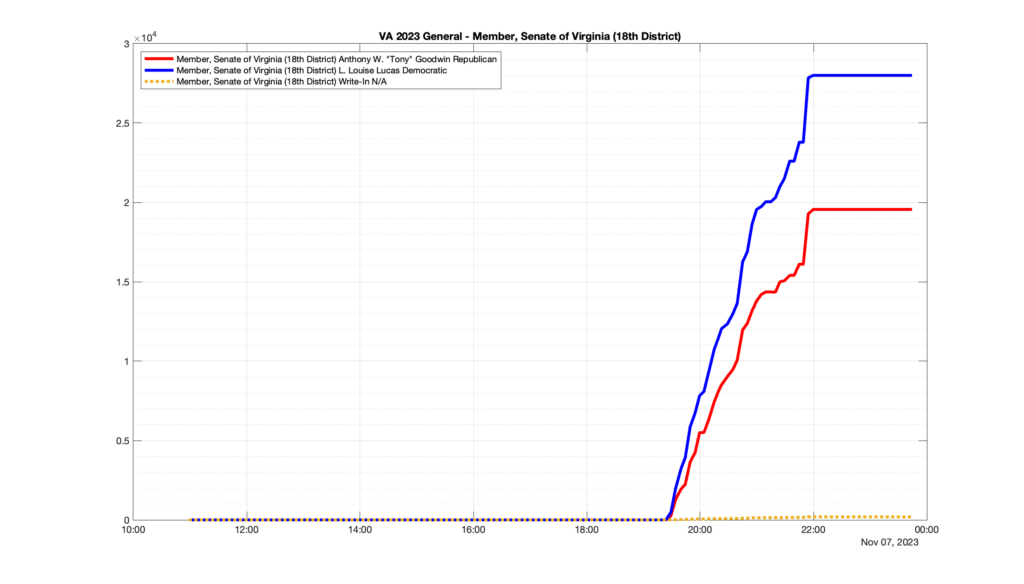
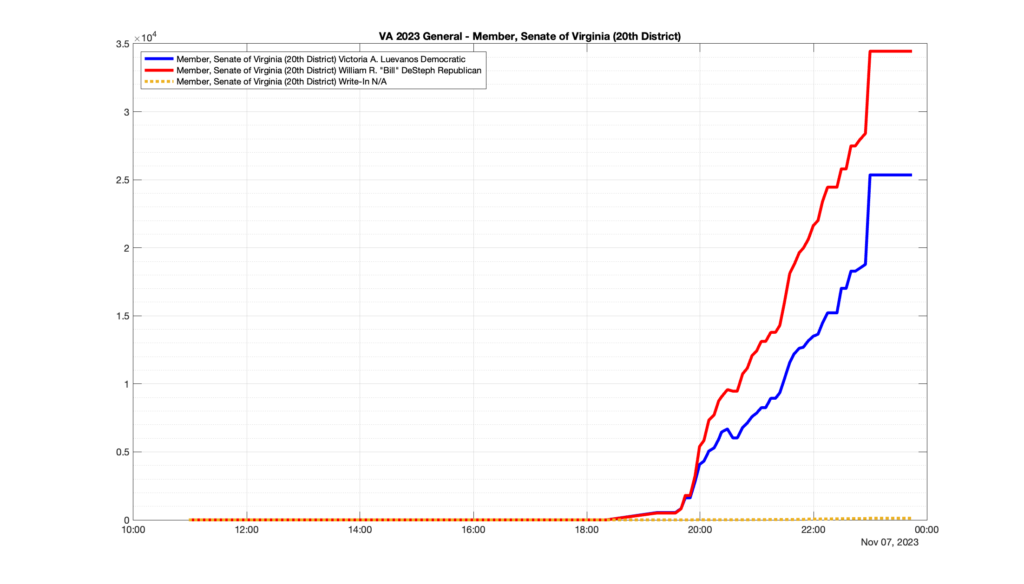
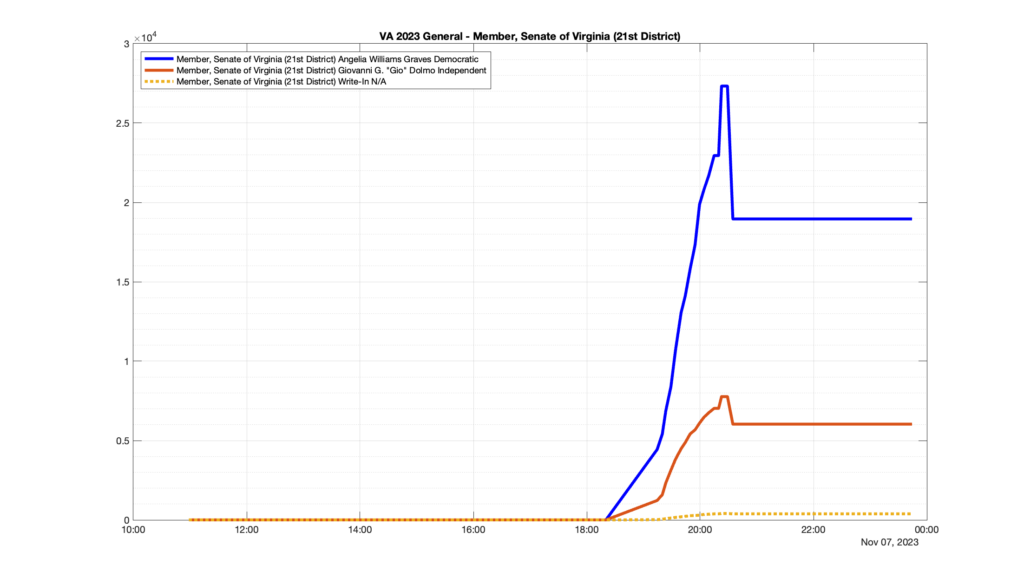
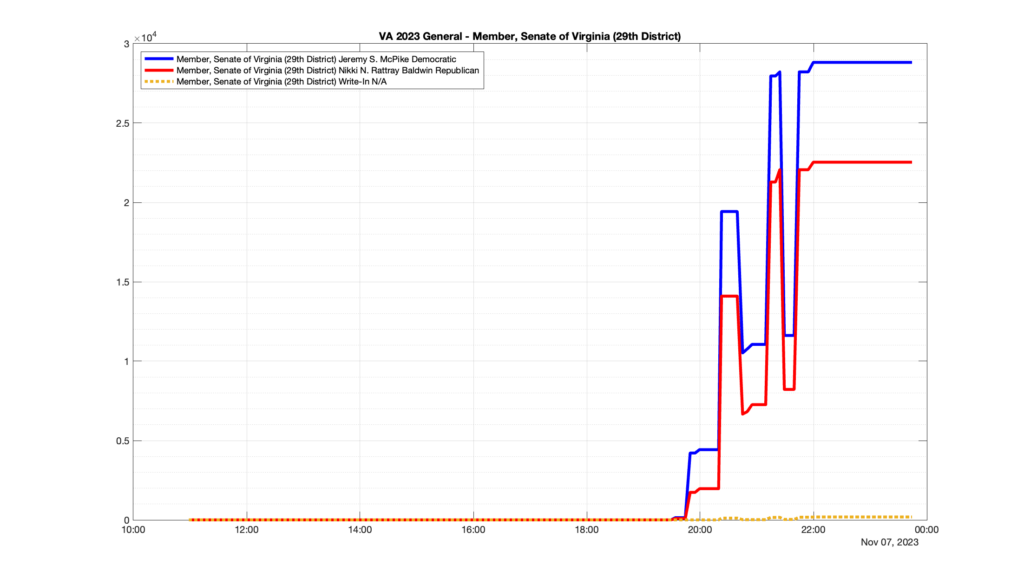
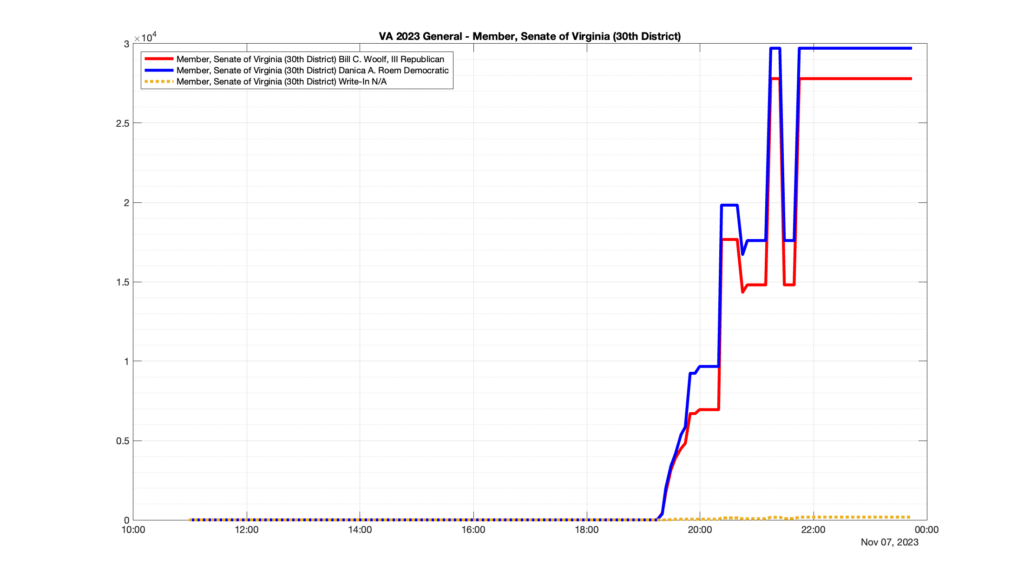
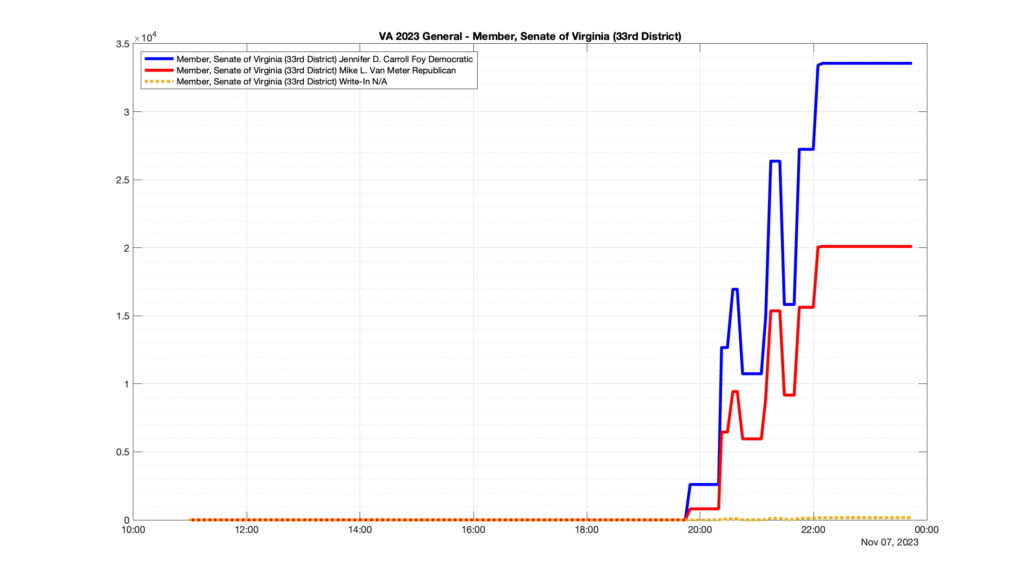
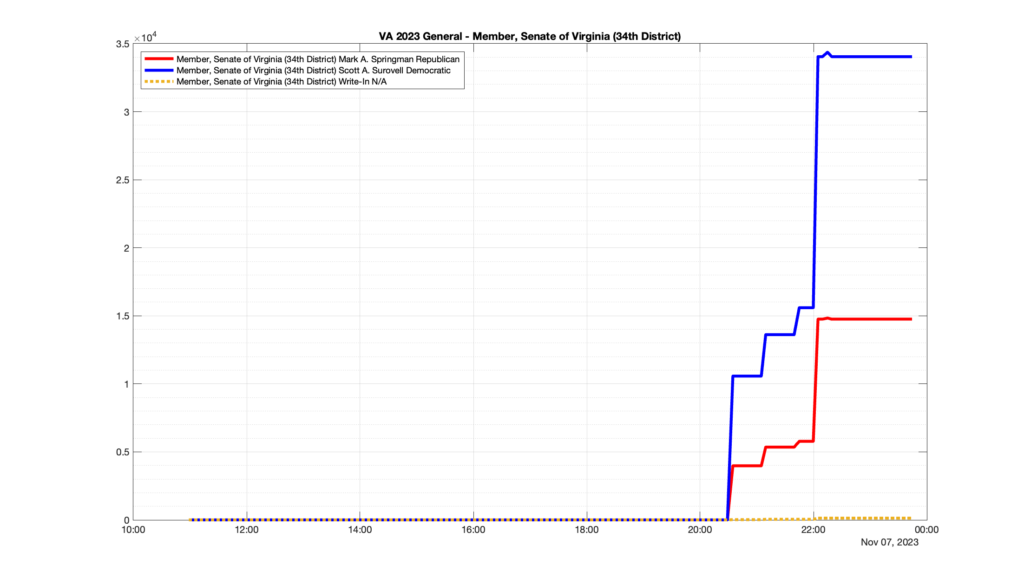
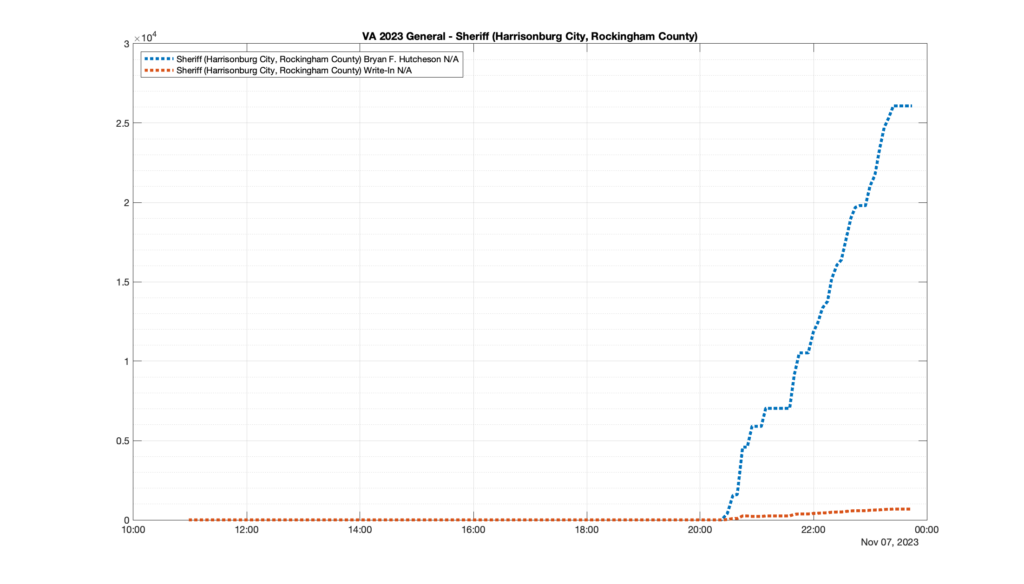
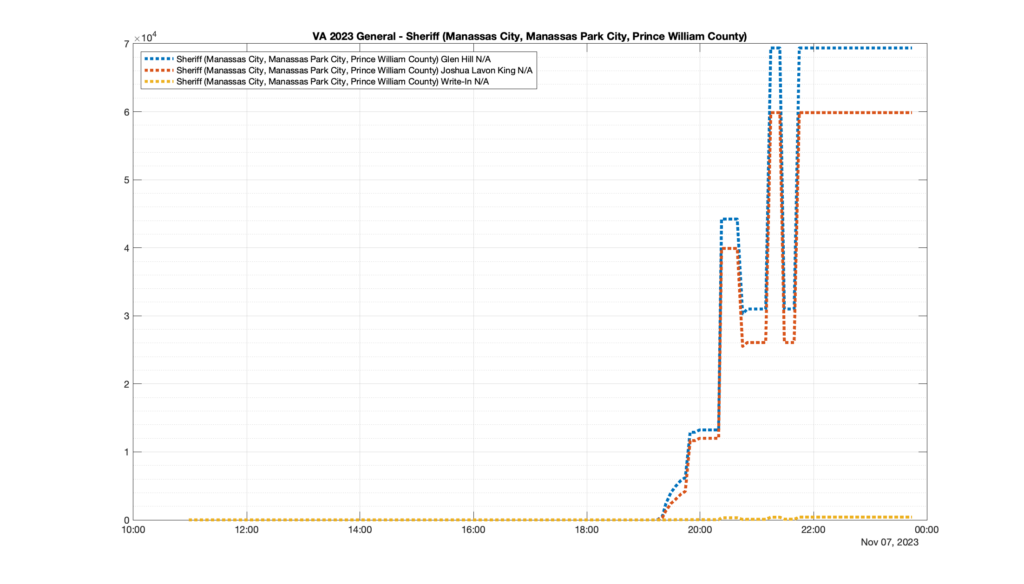
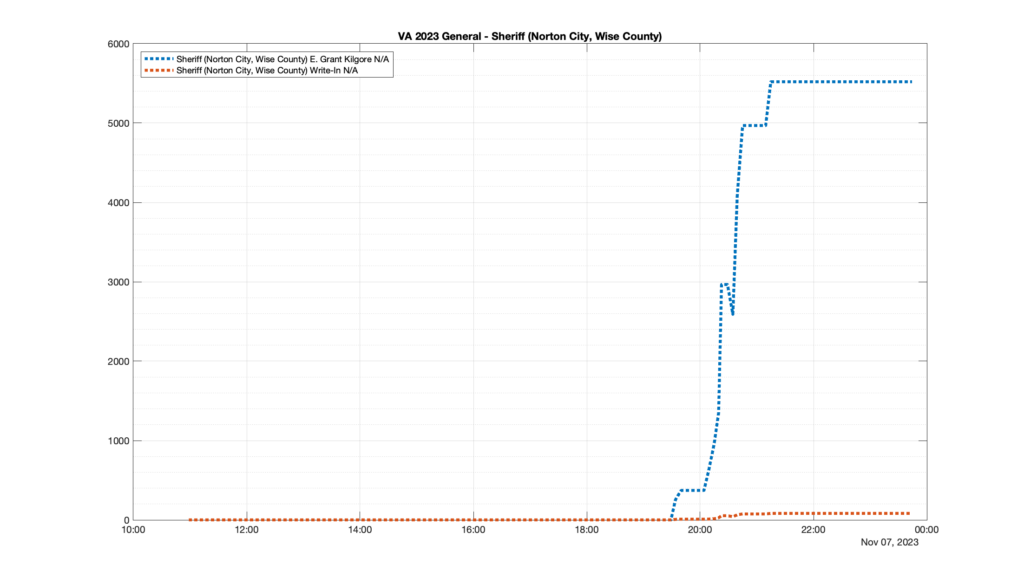
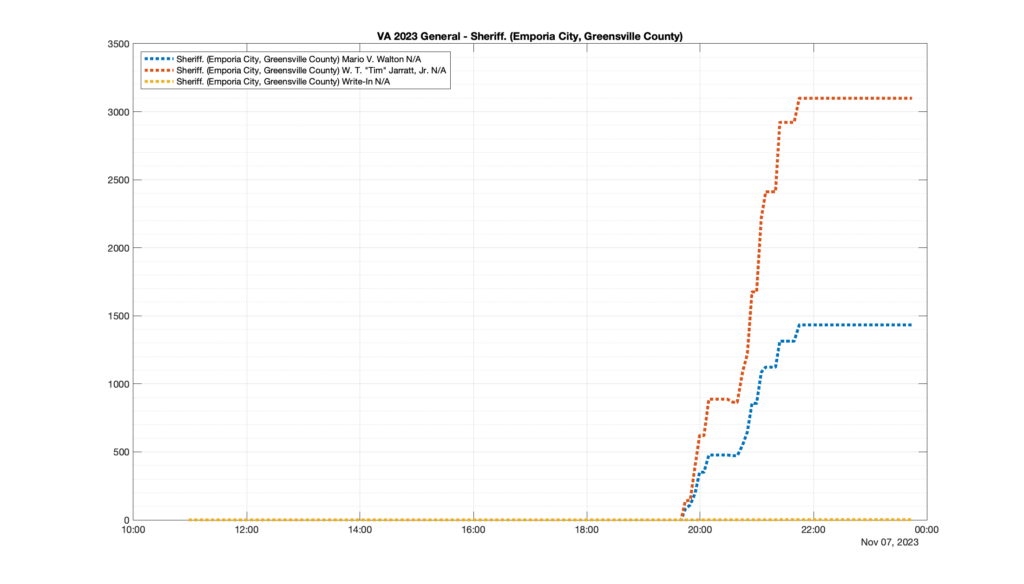
However, when I went to plot the results, I found some data curves that I can’t quite explain. Take, for example, the VA House of Delegates race in the 22nd District:
Now … last I checked, when accumulating counts of ballots … you wouldn’t expect the totals to go down, let alone oscillate back and forth.
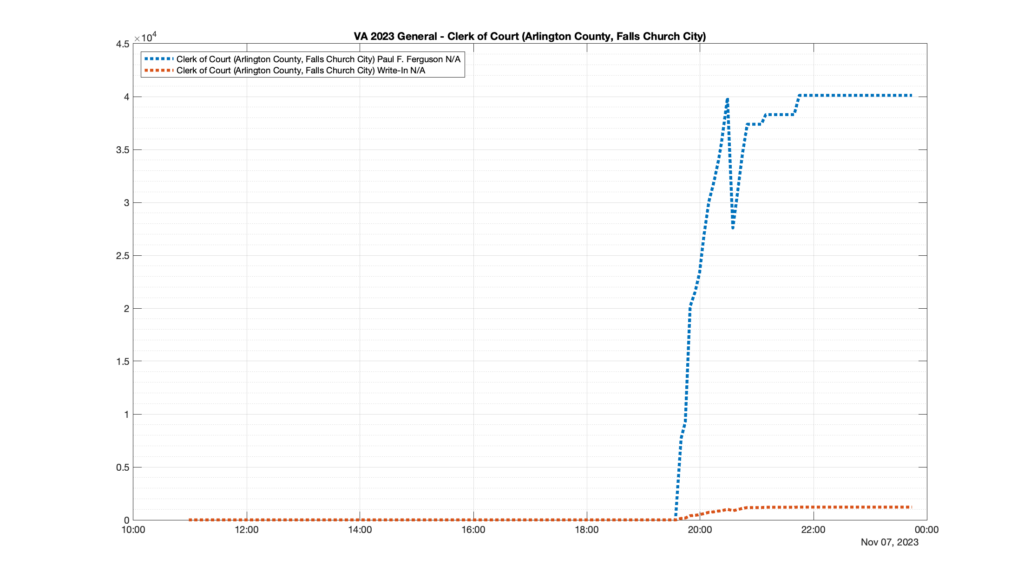
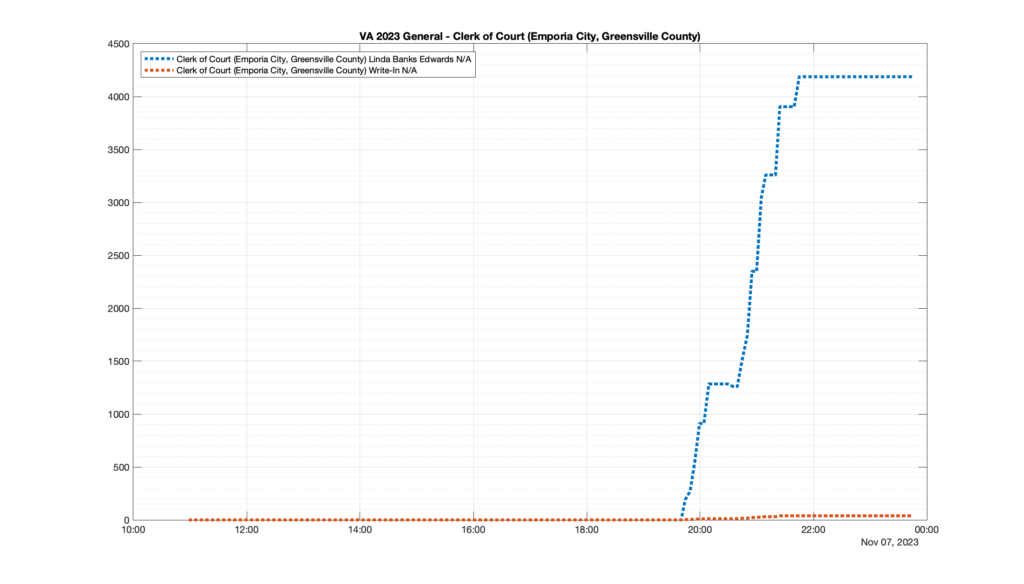
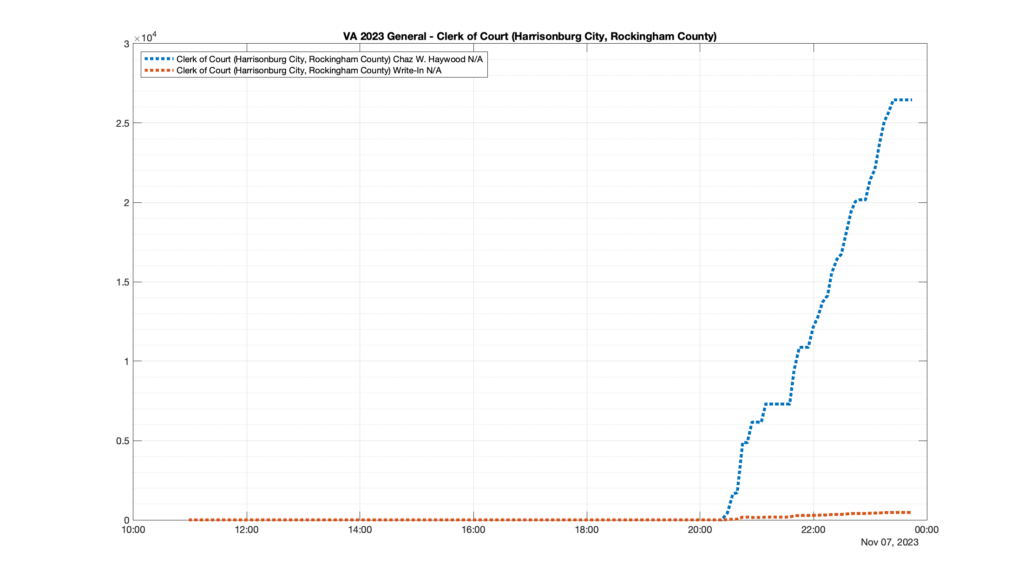
This is not the only race where I found ballot curves that have a decrease in one of the ballot count after a data update. (The gallery is posted below.) Of the 183 races I looked at so far, 79 had a ballot trace that had its count total reduced after a data update. (I haven’t looked at all of the races yet.)
Now, one expects there to be some issues and corrections that have to be made to the election night reporting data. But when 43% of the races sampled have obvious data quality issues like this … I think that deserves some explanation.
So … can ELECT please address this:
Why do 79 (and counting) races (~43% of races sampled) in the VA election night reporting have obvious issues where the vote totals decreased after a data reporting update?